https://github.com/google-research/pegasus
ICML 2020 жҺҘ收зҡ„и®әж–ҮпјҢhttps://arxiv.org/abs/1912.08777
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised objective Gap Sentences Generation (GSG) to train a transformer encoder-decoder model.
PEGASUS:еҹәдәҺеҸҘеӯҗй—ҙйҡҷзҡ„жҠҪеҸ–ејҸж‘ҳиҰҒйў„и®ӯз»ғжЁЎеһӢ
PEGASUSдё“з”ЁдәҺжңәеҷЁж‘ҳиҰҒз”ҹжҲҗгҖӮдҪҝз”Ёи°·жӯҢйў„и®ӯз»ғзҡ„жЁЎеһӢпјҢеңЁ1000дёӘж ·жң¬иҝӣиЎҢжөӢиҜ•пјҢз»“жһңдёҚе·®дәҺдәәзұ»иҜ„дј°з»“жһңгҖӮ
и°·жӯҢеҸ‘зҺ°пјҢйҖүжӢ©вҖңйҮҚиҰҒвҖқеҸҘеӯҗеҺ»йҒ®жҢЎж•ҲжһңеҘҪпјҢиҝҷдјҡдҪҝиҮӘзӣ‘зқЈж ·жң¬зҡ„иҫ“еҮәдёҺж‘ҳиҰҒжӣҙеҠ зӣёдјјгҖӮж №жҚ®ROUGEж ҮеҮҶеҜ№иҫ“еҮәз»“жһңиҝӣиЎҢиҜ„еҲӨпјҢйҖҡиҝҮжҹҘжүҫдёҺж–ҮжЎЈе…¶дҪҷйғЁеҲҶзӣёдјјзҡ„еҸҘеӯҗжқҘиҮӘеҠЁиҜҶеҲ«иҝҷдәӣеҸҘеӯҗгҖӮ
дёҺи°·жӯҢд№ӢеүҚжҸҗеҮәзҡ„T5еҜ№жҜ”пјҢеҸӮж•°ж•°йҮҸд»…дёәT5зҡ„5%гҖӮ
дҪҝз”Ё3з§ҚжЁЎеһӢеңЁ12дёӘж•°жҚ®йӣҶеҒҡе®һйӘҢпјҢи®ӯз»ғеҠЁжҖҒй—ҙйҡҷеҸҘз”ҹжҲҗжЁЎеһӢ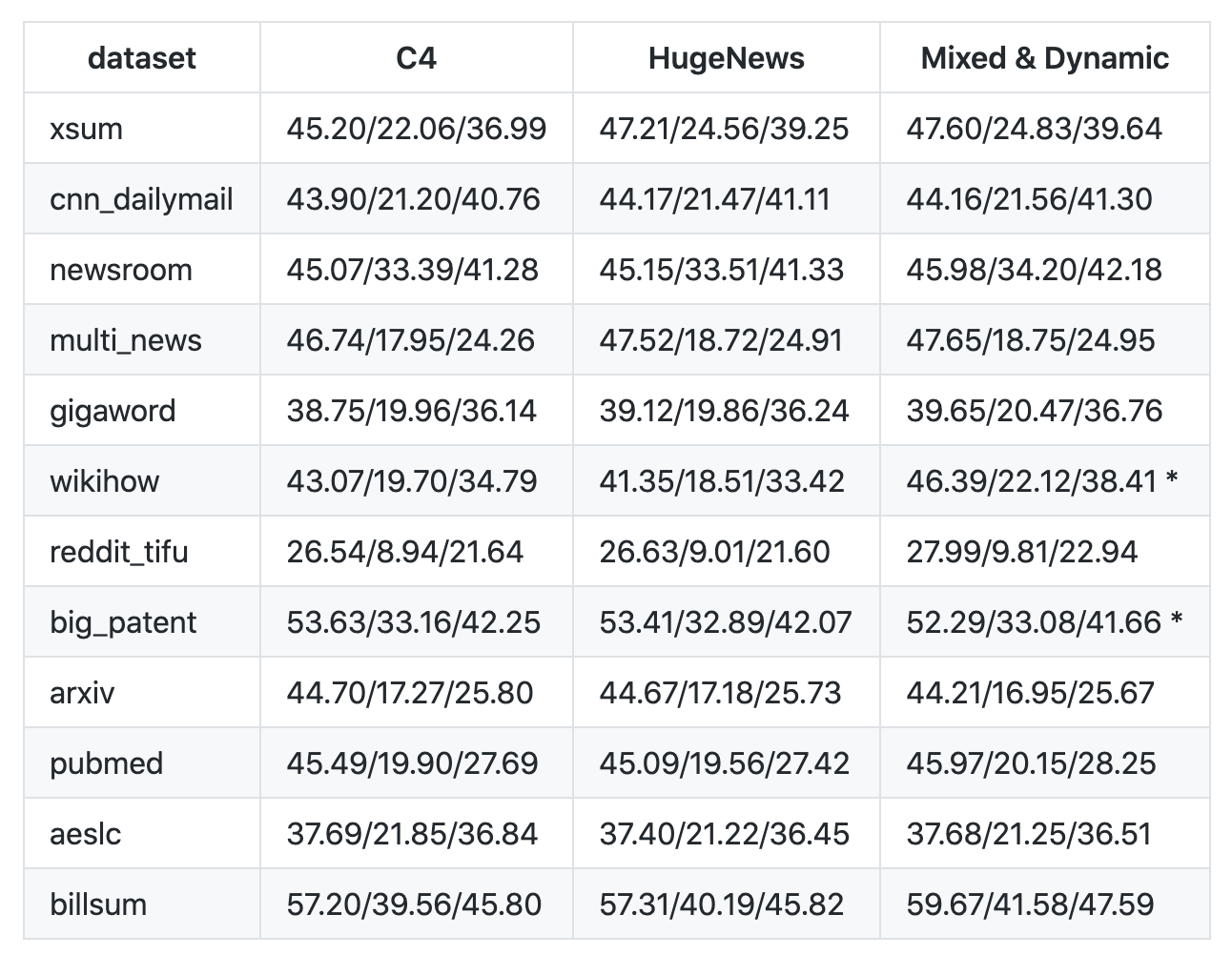
12дёӘдёҚеҗҢзҡ„ж•°жҚ®йӣҶпјҢеҢ…жӢ¬ж–°й—»гҖҒ科еӯҰи®әж–ҮгҖҒдё“еҲ©ж–Ү件гҖҒзҹӯзҜҮе°ҸиҜҙгҖҒз”өеӯҗйӮ®д»¶гҖҒжі•еҫӢж–Ү件е’ҢдҪҝз”ЁиҜҙжҳҺпјҢиЎЁжҳҺиҜҘжЁЎеһӢжЎҶжһ¶йҖӮз”ЁдәҺеҗ„з§Қдё»йўҳгҖӮ
еҮҶеӨҮзҺҜеўғ
д»Јз ҒжҳҜйңҖиҰҒжңәеҷЁе’ҢзҺҜеўғжүҚеҸҜд»ҘиҝҗиЎҢзҡ„гҖӮ
жәҗд»Јз Ғз»ҷеҮәзҡ„жҳҜgcloudе‘Ҫд»ӨпјҢжҲ‘жІЎжңүдҪҝз”Ёе®ғпјҢиҖҢжҳҜдҪҝз”ЁйҳҝйҮҢдә‘жңәеҷЁгҖӮ
е…·дҪ“й…ҚзҪ®дёәпјҡ
ubuntu 16.04 64дҪҚ
зЎ¬зӣҳ500G
1еқ—V100
GPUй©ұеҠЁзӣёе…ізүҲжң¬еҸ·пјҡ
CUDAпјҡ10.2.89
Driverпјҡ440.64.00
CUDNNпјҡ7.6.5
иҜ•дәҶCUDA10.1.168пјҢжңүжҠҘй”ҷгҖӮжүҖд»ҘпјҢCUDAзүҲжң¬еҫҲйҮҚиҰҒпјҢеҲ«йҖүй”ҷгҖӮе…·дҪ“и°·жӯҢиҮӘе·ұдҪҝз”Ёзҡ„жҳҜе“ӘдёӘзүҲжң¬пјҢжҲ‘зӣ®еүҚжІЎжүҫеҲ°зӣёе…іиө„ж–ҷгҖӮ
cat /usr/local/cuda/version.txt
CUDA Version 10.1.168
tensorflow.python.framework.errors_impl.NotFoundError: libtensorflow_framework.so.2: cannot open shared object file: No such file or directory
жӯЈзЎ®зҡ„жҸҗзӨәжҳҜпјҡ
2020-06-22 11:08:56.423661: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
gcloudд№ҹиҜ•дәҶдёҖдёӢпјҢжҸҗзӨәжқғйҷҗдёҚеҜ№гҖӮеӣҪеҶ…FQжңүдәӣиҙ№еҠІе‘ҖгҖӮ
е®үиЈ…pegasus
жҲ‘дҪҝз”Ёзҡ„жҳҜAncona3
cd ~/git
git clone https://github.com/google-research/pegasus
cd pegasus
source ~/anaconda3/bin/activate
# conda create --name env_pegasus python=3.7 еҲӣе»әж—¶йңҖиҰҒ
conda activate env_pegasus
pip3 install -r requirements.txt
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 setup.py install & build
дёӢиҪҪж•°жҚ®
е…ұ12дёӘж•°жҚ®йӣҶпјҢдҪҝз”Ёgsutilе·Ҙе…·дёӢиҪҪгҖӮ
gsutilе·Ҙе…·е®үиЈ…еҸӮиҖғhttps://cloud.google.com/storage/docs/gsutil_install
йңҖиҰҒеҮҶеӨҮ35GзЈҒзӣҳз©әй—ҙгҖӮжҲ‘з”өи„‘зЈҒзӣҳз©әй—ҙдёҚеӨҹпјҢз”ЁдәҶеӨ–жҢӮ移еҠЁзЎ¬зӣҳгҖӮ
gsutilе·Ҙе…·е®үиЈ…е®ҢжҜ•д№ӢеҗҺпјҢе°ұеҸҜд»ҘдёӢиҪҪж•°жҚ®дәҶгҖӮ
mkdir ckpt
gsutil cp -r gs://pegasus_ckpt/ ckpt/
дёӢиҪҪе®ҢжҜ•д№ӢеҗҺпјҢе°Ҷйў„и®ӯз»ғзҡ„жЁЎеһӢж–Ү件дёҠдј еҲ°жңҚеҠЎеҷЁеҜ№еә”зҡ„зӣ®еҪ•гҖӮ дёӢиҪҪйҖҹеәҰдҫқзҪ‘йҖҹиҖҢе®ҡпјҢжҲ‘з”ЁдәҶеӨ§жҰӮдёӨеӨ©ж—¶й—ҙеҗ§гҖӮ
з»Ҳзҡ„ж•°жҚ®дёәпјҡ
и®ӯз»ғе®ҢжҜ•д№ӢеҗҺпјҢpegasus/ckpt/pegasus_ckpt/aeslcзӣ®еҪ•пјҡ
ж•°жҚ®йӣҶ
дёӢйқўзҡ„и®ӯз»ғе’ҢиҜ„дј°пјҢеқҮдҪҝз”Ёaeslcж•°жҚ®йӣҶгҖӮ
AESLC (Zhang & Tetreault, 2019) consists of 18k email bodies and their subjects from the Enron corpus (Klimt & Yang, 2004), a collection of email messages of employees in the Enron Corporation.
и®ӯз»ғ
python3 pegasus/bin/train.py --params=aeslc_transformer \
--param_overrides=vocab_filename=ckpt/pegasus_ckpt/c4.unigram.newline.10pct.96000.model \
--train_init_checkpoint=ckpt/pegasus_ckpt/model.ckpt-1500000 \
--model_dir=ckpt/pegasus_ckpt/aeslc
д»ҘдёҠд»Јз ҒжҲ‘еңЁиҝҗиЎҢзҡ„ж—¶еҖҷжңүжҠҘй”ҷпјҢдҫқиө–жЁЎеқ—жңӘжүҫеҲ°гҖӮжҲ‘жҠҠtrain.py ж–Ү件жӢ·иҙқеҲ°д»“еә“ж №зӣ®еҪ•пјҢ然еҗҺеҶҚиҝҗиЎҢпјҢз»“жһңжҳҫзӨәеҸҜд»ҘгҖӮ
иҜ„дј°
и®ӯз»ғе®ҢжҜ•д№ӢеҗҺпјҢе°ұеҸҜд»ҘиҜ„дј°жЁЎеһӢдәҶгҖӮ
python3 pegasus/bin/evaluate.py --params=aeslc_transformer \
--param_overrides=vocab_filename=ckpt/pegasus_ckpt/c4.unigram.newline.10pct.96000.model,batch_size=1,beam_size=5,beam_alpha=0.6 \
--model_dir=ckpt/pegasus_ckpt/aeslc
еҗҢдёҠпјҢevaluate.pyж–Ү件д№ҹжӢ·иҙқеҲ°д»“еә“зҡ„ж №зӣ®еҪ•гҖӮ
иҜ„дј°з»“жһңпјҡ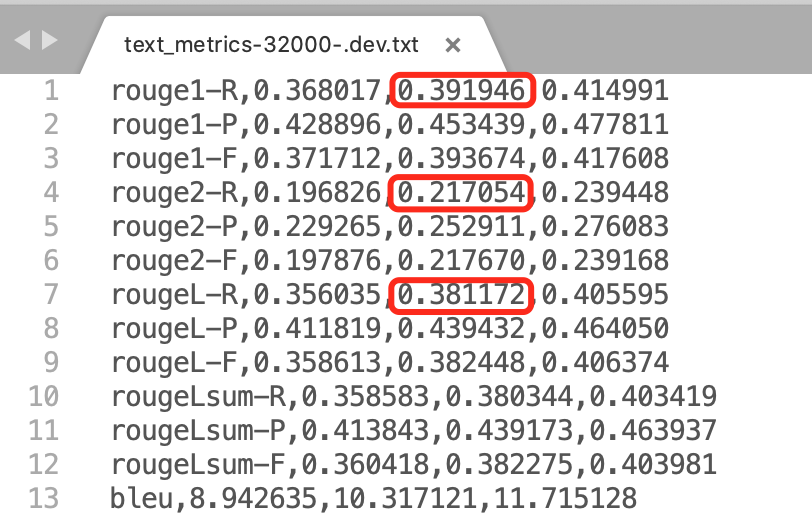
еҸҜи§ҒпјҢе’Ңи°·жӯҢе…¬еёғзҡ„з»“жһңеҹәжң¬дёҖиҮҙгҖӮ
37.69/21.85/36.84
дҪҝз”ЁиҮӘе·ұзҡ„ж•°жҚ®
ж”ҜжҢҒ2з§Қж јејҸзҡ„ж•°жҚ®йӣҶпјҡTensorFlow Datasets (TFDS) гҖҒ TFRecords.
иҜ„жөӢжҢҮж Ү
ROUGE is the main metric for summarization quality.
BLEU is an alternative quality metric for language generation.
Extractive Fragments Coverage & Density are metrics that measures the abstractiveness of the summary.
Repetition Rates measures generation repetition failure modes.
Length statistics measures the length distribution of decodes comparing to gold summary.
ж‘ҳиҰҒз»“жһңзӨәдҫӢпјҡ
ж•°жҚ®йӣҶ
7дёӘйўҶеҹҹпјҢе…ұ12дёӘж•°жҚ®йӣҶгҖӮ
7дёӘйўҶеҹҹеҲҶеҲ«дёәпјҡж–°й—»гҖҒ科еӯҰгҖҒзҹӯзҜҮе°ҸиҜҙгҖҒиҜҙжҳҺгҖҒз”өеӯҗйӮ®д»¶гҖҒдё“еҲ©гҖҒз«Ӣжі•жі•жЎҲ
1. news (Hermann et al., 2015; Narayan et al., 2018; Grusky et al., 2018; Rush et al., 2015; Fabbri et al., 2019), гҖҗж–°й—»пјҢ5дёӘж•°жҚ®йӣҶгҖ‘
2. science (Cohan et al., 2018), гҖҗ科еӯҰпјҢ2дёӘж•°жҚ®йӣҶгҖ‘
3. short stories (Kim et al., 2019), гҖҗзҹӯж•…дәӢ/зҹӯзҜҮе°ҸиҜҙпјҢ1дёӘж•°жҚ®йӣҶгҖ‘
4. instructions (Koupaee & Wang, 2018), гҖҗзҪ‘йЎө/иҜҙжҳҺпјҢ1дёӘж•°жҚ®йӣҶгҖ‘
5. emails (Zhang & Tetreault, 2019), гҖҗйӮ®д»¶пјҢ1дёӘж•°жҚ®йӣҶгҖ‘
6. patents (Sharma et al., 2019), гҖҗдё“еҲ©пјҢ1дёӘж•°жҚ®йӣҶгҖ‘
7. legislative bills (Kornilova & Eidelman, 2019). гҖҗз«Ӣжі•жі•жЎҲпјҢ1дёӘж•°жҚ®йӣҶгҖ‘
гҖҗ科еӯҰгҖ‘ж•°жҚ®йӣҶ
arXiv, PubMed (Cohan et al., 2018) are two long document datasets of scientific publications from arXiv.org (113k) and PubMed (215k). The task is to generate the abstract from the paper body.




гҖҗзҪ‘йЎө/иҜҙжҳҺгҖ‘ж•°жҚ®йӣҶ
WikiHow (Koupaee &Wang, 2018) is a large-scale dataset of instructions from the online WikiHow.com website. Each of 200k examples consists of multiple instruction-step para- graphs along with a summarizing sentence. The task is to generate the concatenated summary-sentences from the paragraphs.
Koupaee, M. and Wang, W. Y. Wikihow: A large scale text summarization dataset. arXiv preprint arXiv:1810.09305, 2018.

гҖҗж–°й—»гҖ‘ж•°жҚ®йӣҶ



NEWSROOMж‘ҳиҰҒжҳҜдёҖеҸҘиҜқ