第1章 Amazon Neptune 技术概述
1.1 什么是图数据库
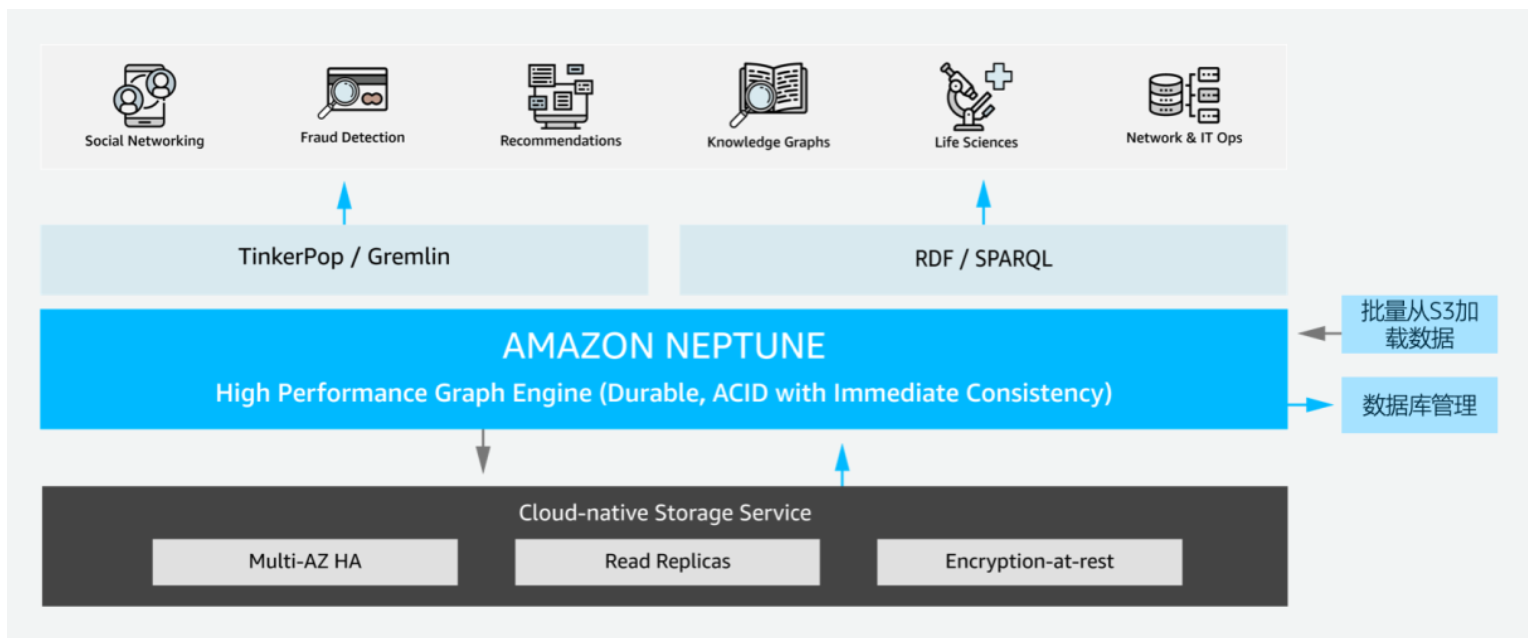
Amazon Neptune 是一项快速、可靠且完全托管的图数据库服务,可帮助您轻松 构建和运行使用高度互连数据集的应用程序。Amazon Neptune 的核心是专门构建的高 性能图数据库引擎,它进行了优化以存储数十亿个关系并将图形查询延迟降低到毫秒 级。 Amazon Neptune 支持常见的图形模型 Property Graph 和 W3C 的 RDF 及其关 联的查询语言 Apache TinkerPop Gremlin 和 SPARQL,从而使您能够轻松构建查询以有 效地导航高度互连数据集。Neptune 支持图形使用案例,如建议引擎、欺诈检测、知 识图谱、药物开发和网络安全。
Amazon Neptune 具有高可用性,并提供只读副本、时间点恢复、到 Amazon S3 的持续备份以及跨可用区复制等功能。Neptune 非常安全,可支持 HTTPS 加密客户端 连接和静态加密。Neptune 完全托管,因此,您再也无需担心数据库管理任务,例 如,硬件预置、软件修补、设置、配置或备份。
1.2 核心优势
1) 支持开放图形 API
Amazon Neptune 支持 Gremlin 和 SPARQL 的开放图谱 API,并为这些图形模型 及其查询语言提供高性能。使用 Amazon Neptune,您可以选择属性图形模型及其开源 查询语言 Apache TinkerPop Gremlin 或 W3C 标准资源描述框架 (RDF) 模型及其标准 查询语言 SPARQL。
2) 高性能和高可扩展性
Amazon Neptune 是一个专门构建的高性能图数据库。它针对处理图形查询进行 了优化。Neptune 可在三个可用区内支持多 15 个低延迟读取副本,从而扩展读取容量并每秒执行超过 10 万个图形查询。您可以根据需求变化轻松扩展和缩小数据库 部署,包括从较小的实例类型到较大的实例类型。
3) 高可用性和持久性
Amazon Neptune 具有高可用性、持久性,并且符合 ACID (原子性、一致性、隔 离性、持久性)。Neptune 旨在提供超过 99.99% 的可用性。其存储系统具有容错能力 并能自我修复,专为云而构建,可以跨三个可用区复制六个数据副本。Neptune 会不 断将您的数据备份到 Amazon S3,并以透明方式从物理存储故障中恢复。对于高可用 性,实例故障转移通常只需不到 30 秒。
4) 高度安全
Amazon Neptune 为您的数据库提供多级安全保护,包括使用 Amazon VPC 进行 网络隔离、支持终端节点访问的 IAM 身份验证、HTTPS 加密的客户端连接、使用您通 过 AWS Key Management Service (KMS) 创建和控制的密钥对静态数据进行加密。在加 密的 Neptune 实例上,底层存储中的数据会被加密,在同一个集群中的自动备份、快 照和副本也会被加密。
5) 完全托管
使用 Amazon Neptune,您无需担心硬件预置、软件修补、设置、配置或备份等 数据库管理任务。Neptune 会自动持续地监控您的数据库并将其备份到 Amazon S3, 因此可实现精细的时间点恢复。您可以使用 Amazon CloudWatch 监控数据库性能。
1.3 使用场景
Amazon Neptune 等图数据库专门用于存储和导航关系。在社交网络、推荐引擎 和欺诈检测等使用案例中,您需要在数据之间创建关系并快速查询这些关系,此时, 图数据库将比关系数据库更具优势。使用关系数据库构建这些类型的应用程序面临着 许多挑战。您将需要多个具有多个外键的表。用于导航此数据的 SQL 查询需要嵌套查 询和复杂的联接,它们很快就会变得不灵便,而且随着数据量逐渐增加,查询的性能 也会降低。
Amazon Neptune 使用节点 (数据实体)、边缘 (关系) 和属性等图形结构来表示和
存储数据。这些关系存储为数据模型的一等公民。这样,系统便可直接关联节点中的 数据,从而显著提高导航数据中关系的查询的性能。Neptune 的大规模交互式性能可 有效地实现各种图形使用案例。
1) 社交网络
Amazon Neptune 可以快速轻松地处理大量的用户配置文件和交互,从而构建社 交网络应用程序。Neptune 能够以高吞吐量实现高度交互式的图形查询,从而为您的 应用程序带来社交功能。例如,如果您要向应用程序构建社交源,则可以使用 Neptune 来提供结果,它会优先向用户显示来自其家人、具有其所“赞”更新的好友以 及居住在其附近的好友的新更新。
2) 推荐引擎
使用 Amazon Neptune,您可以在图形中存储客户兴趣、好友和购买历史记录等 信息之间的关系,并快速查询图形以提出个性化且相关的建议。例如,借助 Neptune,您可以使用高度可用的图数据库,并根据关注相同运动内容且具有类似购买 历史记录的其他人购买的产品,向用户提供产品推荐。或者,您可以识别有共同好友 但还不认识对方的人员,然后提供好友推荐。
3) 欺诈检测
借助 Amazon Neptune,您可以使用关系以近乎实时的方式处理财务和购买交 易,从而轻松检测欺诈模式。Neptune 提供完全托管服务来执行快速图形查询,从而 检测潜在购买者是否在使用与已知欺诈案例相同的电子邮件地址和信用卡。如果您要 构建零售欺诈检测应用程序,Neptune 可以帮助您构建图形查询,以便轻松检测关系 模式,例如多个人与个人电子邮件地址相关联,或者多个人共享同一个 IP 地址但居 住在不同的物理地址。
4) 知识图谱
Amazon Neptune 可帮助您构建知识图谱应用程序。使用知识图谱,您可以将信 息存储在图形模型中,并使用图形查询来支持用户轻松导航高度互连的数据集。 Neptune 支持开源和开放标准 API,从而您可以快速使用现有信息资源来构建知识图谱,并将其托管在完全托管的服务上。例如,如果用户对“蒙娜丽莎”感兴趣,您还可
以帮助他们发现达芬奇的其他艺术作品或卢浮宫的其他艺术品。利用知识图谱,您可 以将主题信息添加到产品目录,构建和查询复杂的监管规则模型,或者进行一般信息 建模(如维基数据)。
5) 生命科学
Amazon Neptune 可帮助您构建支持存储和导航生命科学领域内信息的应用程 序,并使用静态加密功能轻松处理敏感数据。例如,您可以使用 Neptune 来存储关于 疾病和基因相互作用的模型,并搜索蛋白质途径中的图形模式,以查找可能与疾病相 关的其他基因。您可以将化合物建模为图形,并查询分子结构中的模式。Neptune 还 可以帮助您整合信息,从而应对医疗保健和生命科学研究领域的挑战。您可以使用 Neptune 跨不同系统创建和存储数据,并专门组织研究出版物,从而快速查找相关信 息。
6) 网络/IT 运营
您可以使用 Amazon Neptune 存储网络图形,并使用图形查询来回答有多少台主 机正在运行特定应用程序等问题。Neptune 可以存储和处理数十亿的事件来管理和保 护您的网络。如果您检测到异常事件,则可以使用 Neptune 并通过事件属性来查询图 形模式,从而快速了解它可能对您的网络产生的影响。您可以查询 Neptune 以找到可 能遭入侵的其他主机或设备。例如,如果您在主机上检测到恶意文件,则 Neptune 可 以帮助您找到传播恶意文件的主机之间的连接,使您能够进行跟踪,找到下载该恶意 文件的原始主机。
1.4 参考架构
在开始设计数据库之前,我们还建议您参考 GitHub 存储库用于图形数据库的 AWS 参考架构,在其中您可以了解有关图形数据模型和查询语言选择的信息,并浏览 参考部署架构的示例,Amazon Neptune 的关键服务组件参考如下:
主数据库实例 – 支持读取和写入操作,并执行针对集群卷的所有数据修改。每 个 Neptune 数据库集群均有一个主数据库实例,负责写入(即,加载或修改)图形数 据库内容。
Neptune 副本 – 连接到同一存储卷作为主数据库实例并仅支持读取操作。除主 数据库实例之外,每个 Neptune 数据库集群多可拥有 15 个 Neptune 副本。这 样,通过将 Neptune 副本放在单独的可用区中并分配来自读取客户端的负载,可以实 现高可用性。
集群卷 – Neptune 数据存储在集群卷中,旨在实现可靠性和高可用性。集群卷由 跨一个 AWS 区域中的多个可用区的数据副本组成。由于您的数据会自动跨可用区复 制,因此具有高持久性,数据丢失的可能性较小。
1.4.1 应用部署架构-NLB/ALB 模式
https://github.com/aws-samples/aws-dbs-refarch-graph/tree/master/src/connecting-using- a-load-balancer
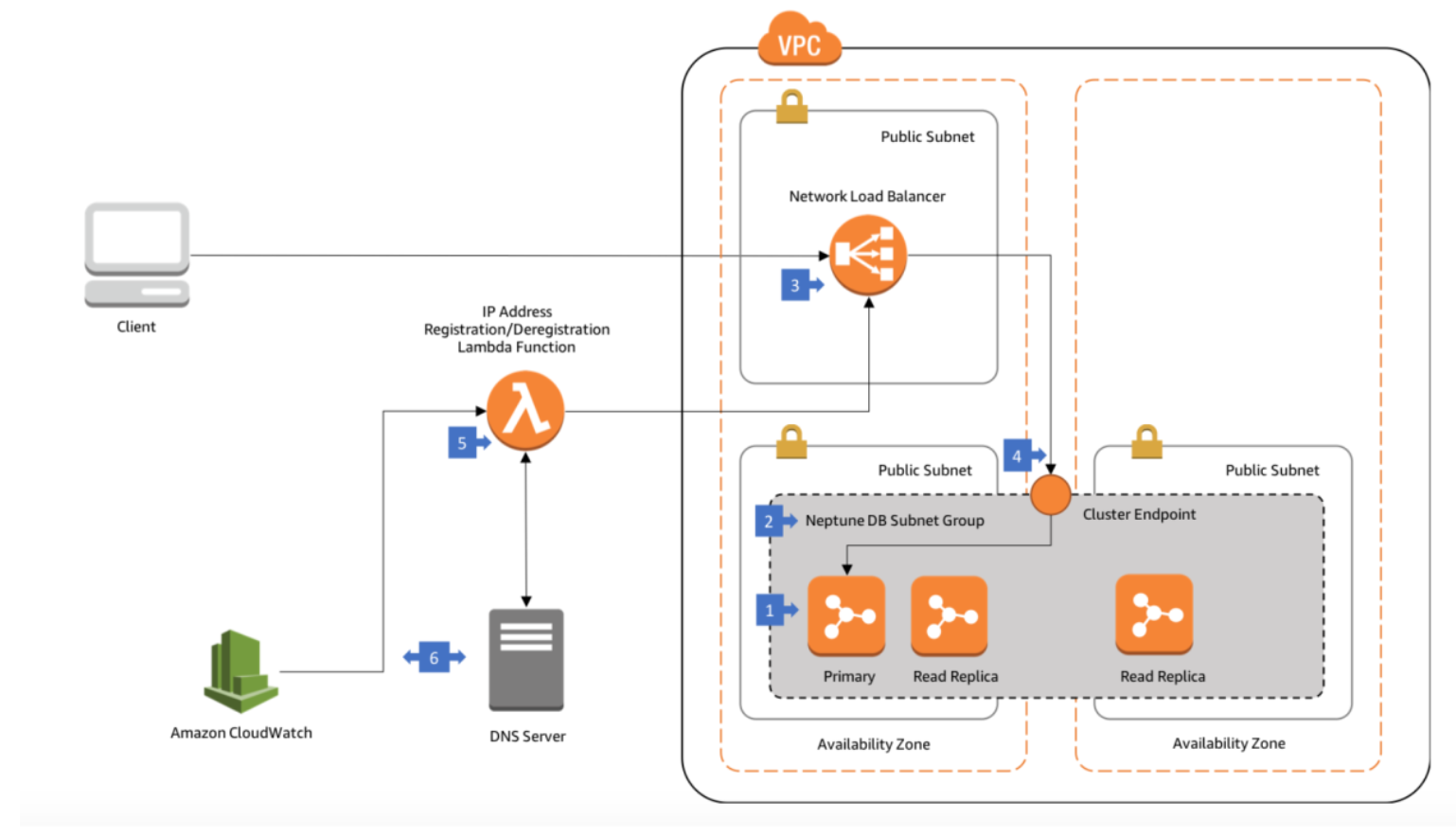
NLB 模式部署架构概述:
在这种体系结构中,您的 Neptune 群集至少在两个可用区中的两个子网中运行,每
个子网都在不同的可用区中。
Neptune DB 子网组在两个可用区中至少跨越两个子网。
来自外部客户端的 Web 连接在公共子网中的网络负载平衡器上终止。
负载平衡器将请求转发到 Neptune 群集端点(该端点随后路由到数据库群集中的主
实例)。
Lambda 函数会定期刷新群集端点的目标 IP 地址。
此 Lambda 函数由 CloudWatch 事件触发。触发时,该函数向 DNS 服务器查询 Neptune
群集终结点的 IP 地址。 它将新的 IP 地址注册到负载均衡器的目标组,并注销所有 过时的 IP 地址。
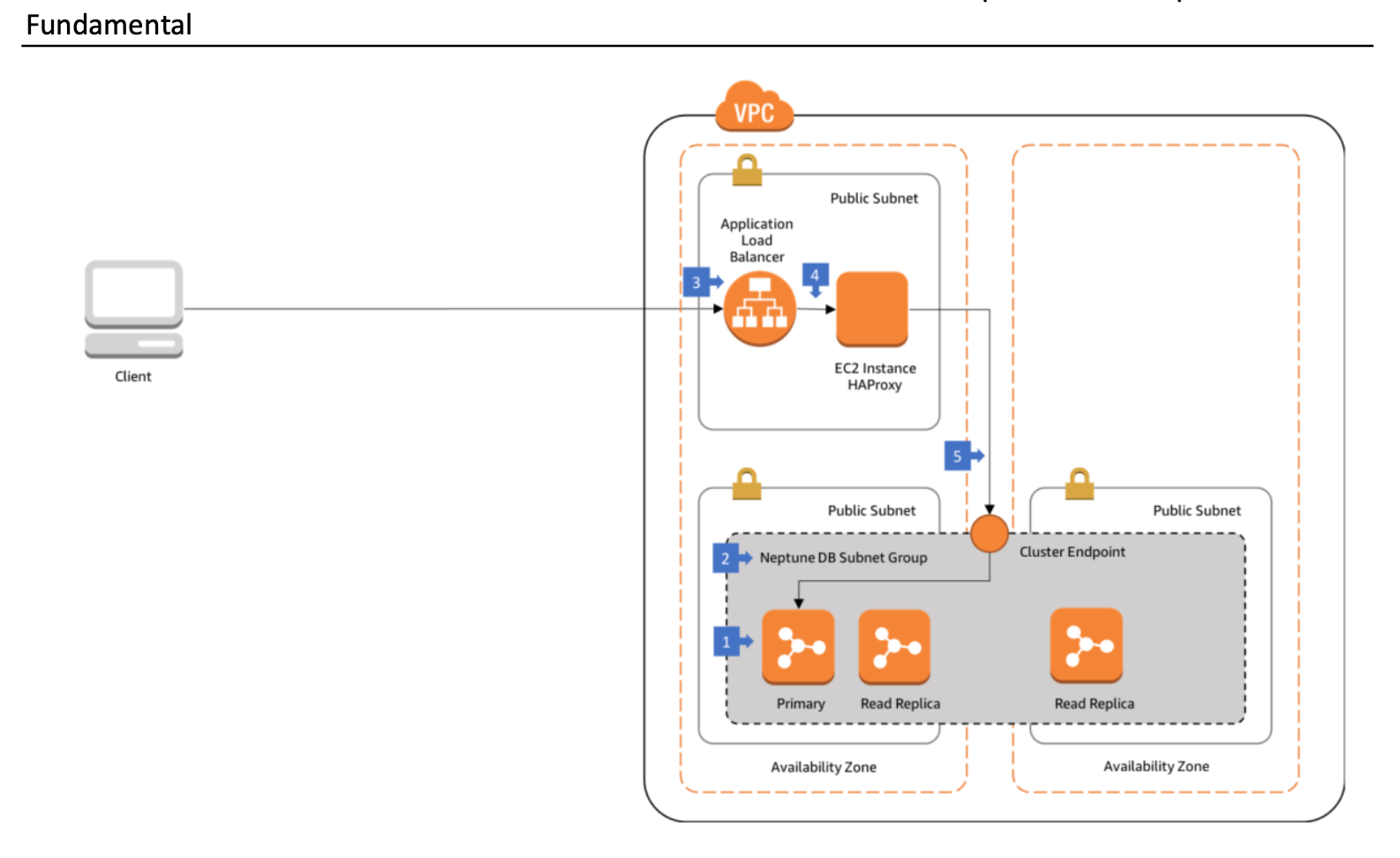
ALB 模式部署架构概述:
在这种体系结构中,您的 Neptune 群集至少在两个可用区中的两个子网中运行,每
个子网都在不同的可用区中。
Neptune DB 子网组在两个可用区中至少跨越两个子网。
来自外部客户端的 Web 连接在公共子网中的 Application Load Balancer 上终止。
负载平衡器将请求转发到在 EC2 实例上运行的 HAProxy。 此 EC2 实例注册在属于
ALB 的目标组中。
HAProxy 配置有 Neptune 群集终结点 DNS 和端口。 来自 ALB 的请求将转发到数据
库集群中的主实例。
1.4.2 应用部署架构-无服务器模式
https://github.com/aws-samples/aws-dbs-refarch-graph/tree/master/src/accessing-from- aws-lambda
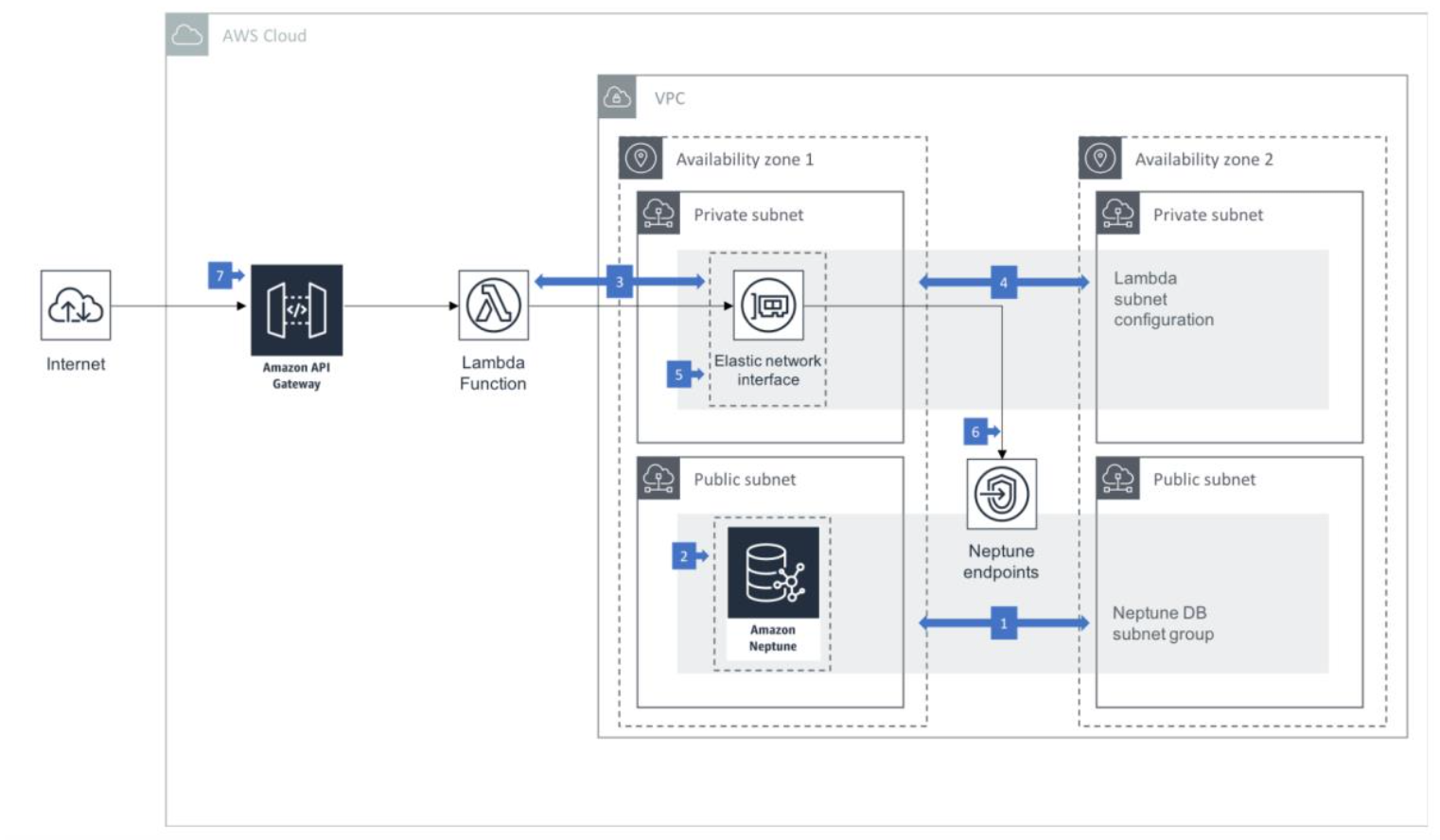
Amazon API Gateway 与 AWS Lambda 模式部署架构概述:
在这种体系结构中,您的 Neptune 群集至少在两个可用区中的两个子网中运行,每
个子网都在不同的可用区中。通过在至少两个可用区中分布集群实例,可以帮助确
保在可用性区发生故障的极少数情况下数据库集群中有可用实例。
Neptune 的 VPC 安全组配置为允许从 Neptune 群集端口上的 AWS Lambda 安全组进
行访问。
AWS Lambda 配置为访问您的 VPC 中的资源。这样,Lambda 可以创建弹性网络接口
(ENI),使您的功能可以安全地连接到 Neptune。
Lambda VPC 配置信息包括至少 2 个专用子网,从而允许 Lambda 以高可用性模式运
行。
允许 Lambda 使用的 VPC 安全组通过 Neptune VPC 安全组上的入站规则访问 Neptune。
在 Lambda 函数中运行的代码使用 Gremlin 或 SPARQL 客户端将查询提交给 Neptune
群集的群集,读取器和/或实例端点。
API Gateway 公开了接受客户端请求并执行后端 Lambda 函数的 API 操作。
1.4.3 应用部署架构-Kinesis Data Stream 模式
https://github.com/aws-samples/aws-dbs-refarch-graph/tree/master/src/writing-from- amazon-kinesis-data-streams
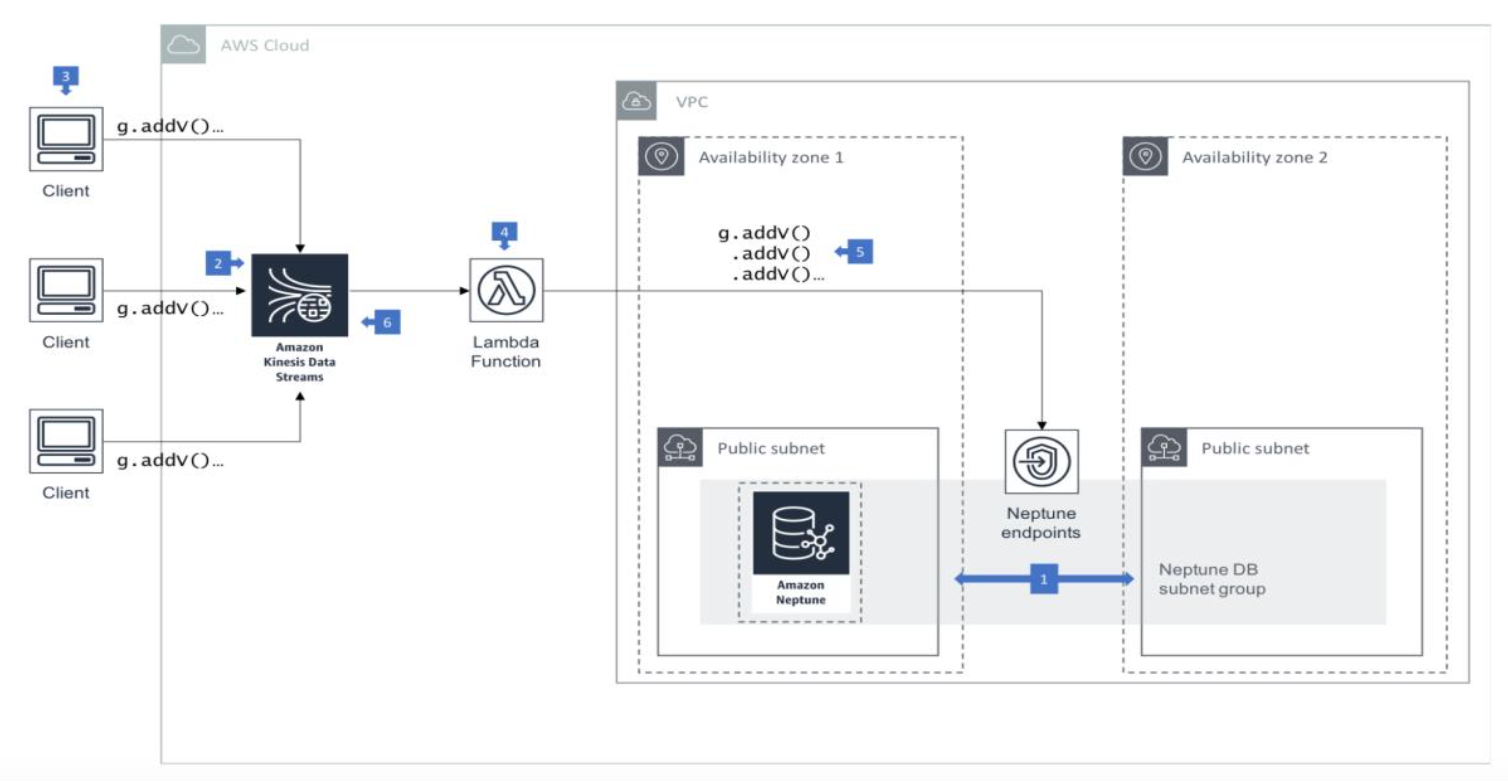
Amazon Kinesis Data Stream 模式部署架构概述:
在这种体系结构中,您的 Neptune 群集至少在两个可用区中的两个子网中运行,每
个子网都在不同的可用区中。通过在至少两个可用区中分布集群实例,可以帮助确
保在可用性区发生故障的极少数情况下数据库集群中有可用实例。
提供 Kinesis 数据流以接受来自客户端应用程序的写入请求,该客户端应用程序充当
记录生产者。
客户端可以使用 Amazon Kinesis Data Streams API 或 Kinesis Agent 将单个记录写入数
据流。
AWS Lambda 函数处理数据流中的记录。创建 Lambda 函数和事件源映射。事件源映
射告诉 Lambda 将数据流中的记录发送到 Lambda 函数,该函数使用 Gremlin 或
SPARQL 客户端向 Neptune 集群端点提交写请求。
Lambda 函数将批处理写入 Neptune。每个批处理都在单个事务的上下文中执行。
为了提高该函数处理记录的速度,请将分片添加到数据流中。 Lambda 按顺序处理每个分片中的记录,如果函数返回错误,则停止处理分片中的其他记录。
第2章 实验操作指南
本实验将通过 AWS CloudFormation 的方式对实验环境进行自动化部署,主要会使 用到 AWS IAM、Amazon VPC、Amazon EC2、Amazon S3、Amazon Neptune、Amazon SageMaker 这些服务,虽然不要求学员掌握所有服务的使用技能,但好具有一定的 AWS 云服务使用经验。具体的实验架构参考下:

2.1 初始环境安装
使用中国区帐号的学员,请选择宁夏区域,CloudFormation 地址如下:
https://cn-northwest-1-migration.s3.cn-northwest-1.amazonaws.com.cn/neptune-full-stack- nested-template.json
使用 Global 帐号的学员,请选择东京区域,CloudFormation 地址如下:
https://ap-northeast-1-migration.s3-ap-northeast-1.amazonaws.com/neptune-full-stack- nested-template.json
请提前设置好用户权限和 EC2 的密钥对,CloudFormation 模板操作视频如下:
https://cn-northwest-1-migration.s3.cn-northwest-1.amazonaws.com.cn/Neptune-CFN.mov
2.1.1 运行 CloudFormation 模板
1) 在控制台上选择CloudFormation服务,点击“创建堆栈”
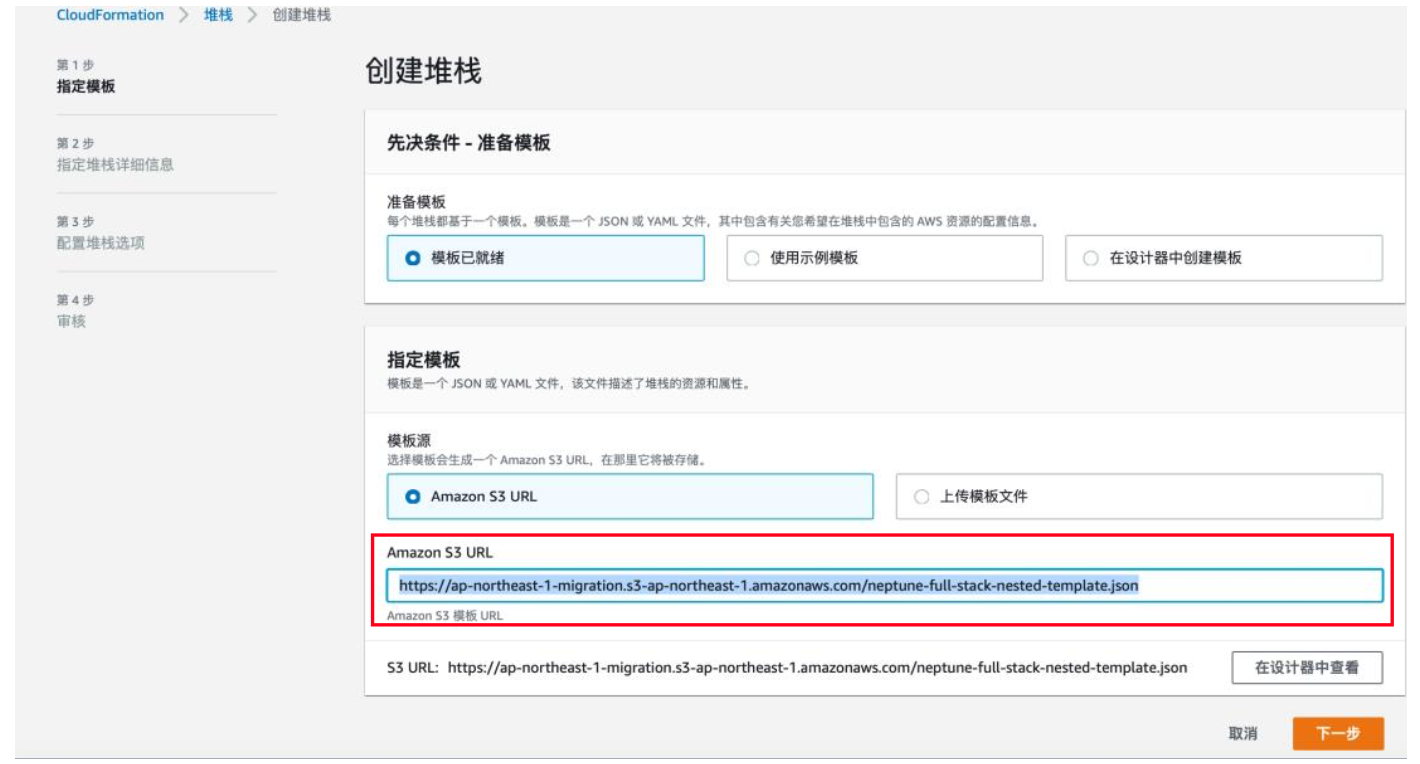
2) 将 CloudFormation 地址复制过来,点击“下一步”
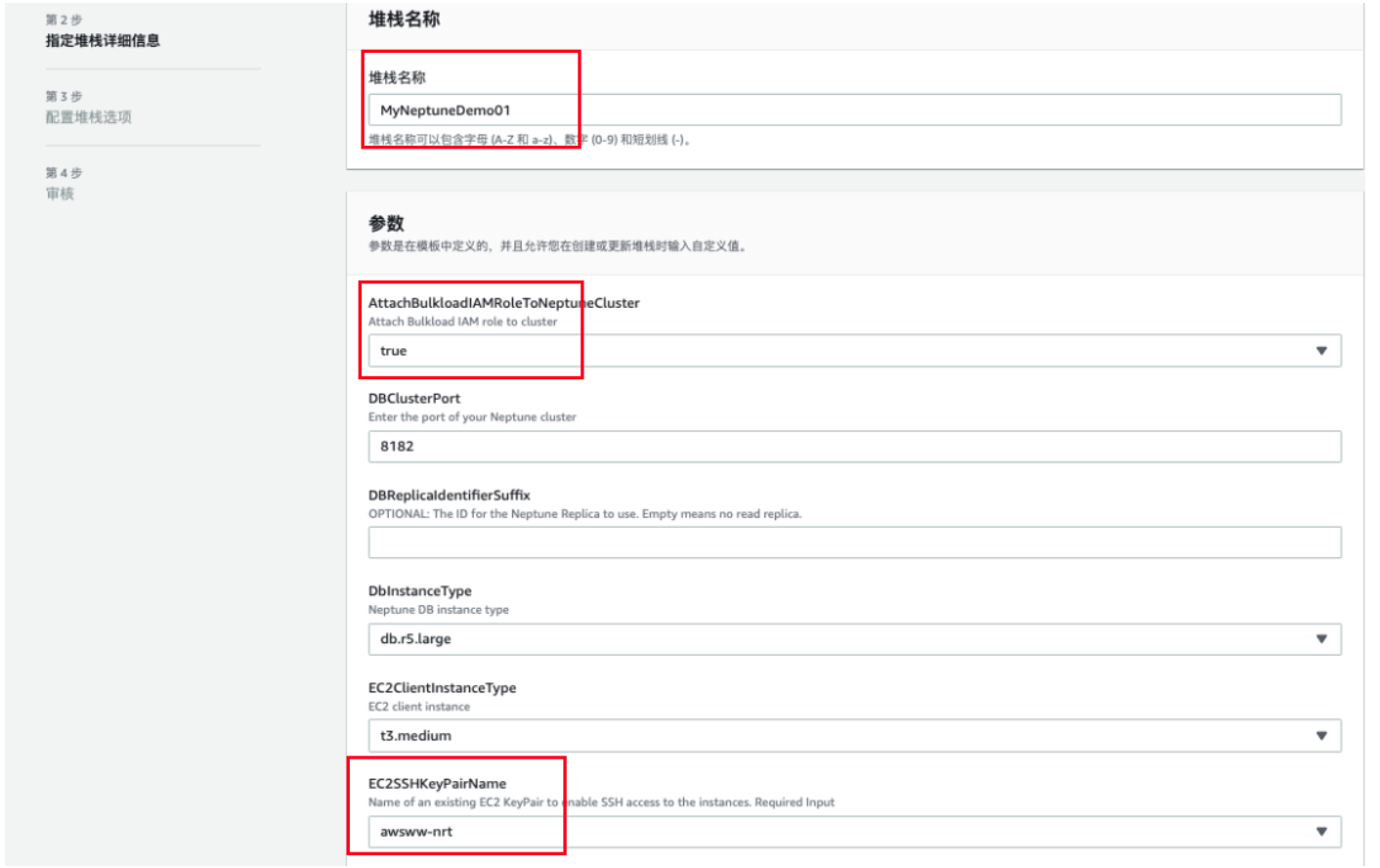
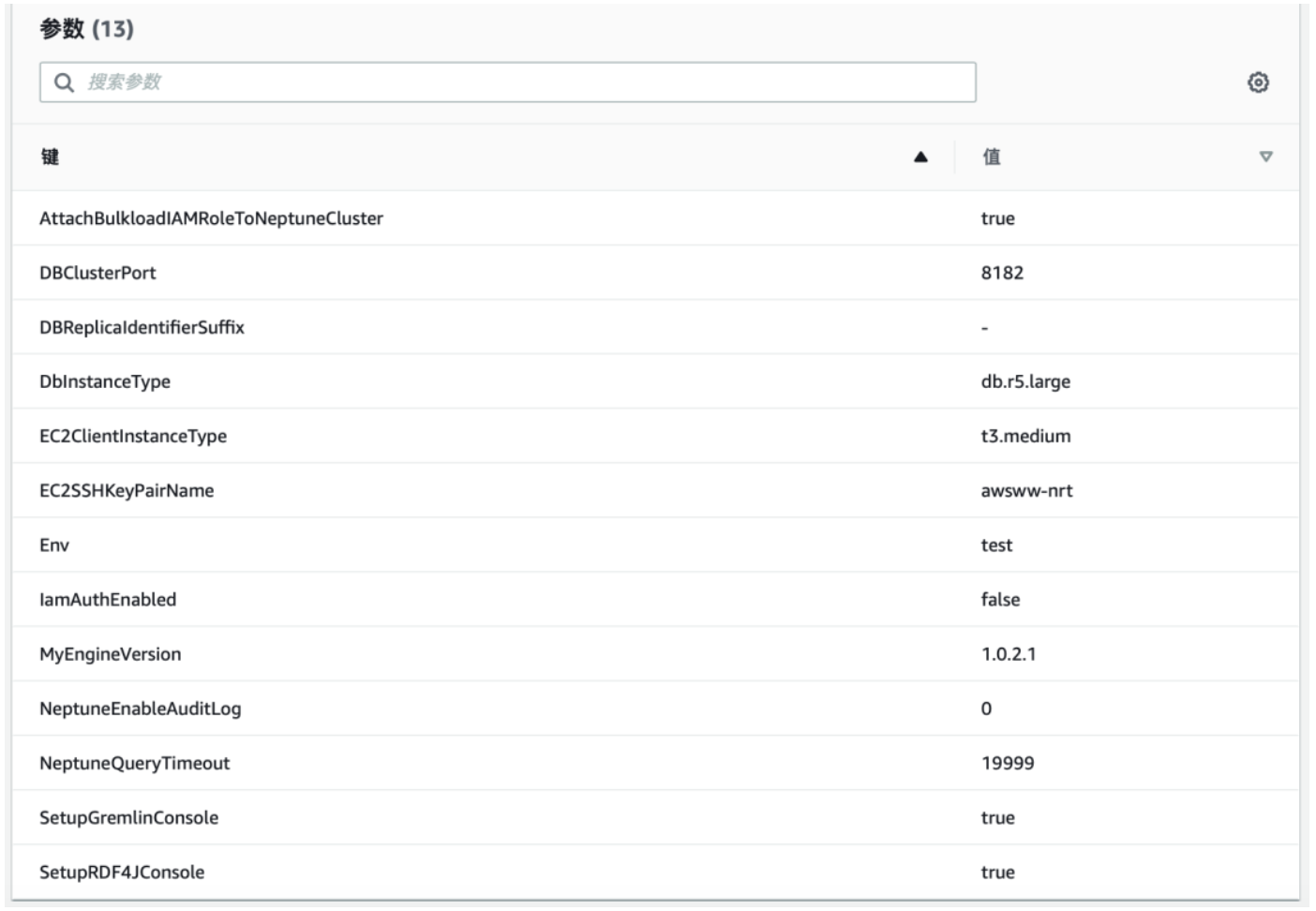
3) 请意红色方框里面的输入内容,其他内容都可以默认,点击“下一步”

继续“下一步”
4) 请意红色方框里面的选择内容,点击“创建堆栈”
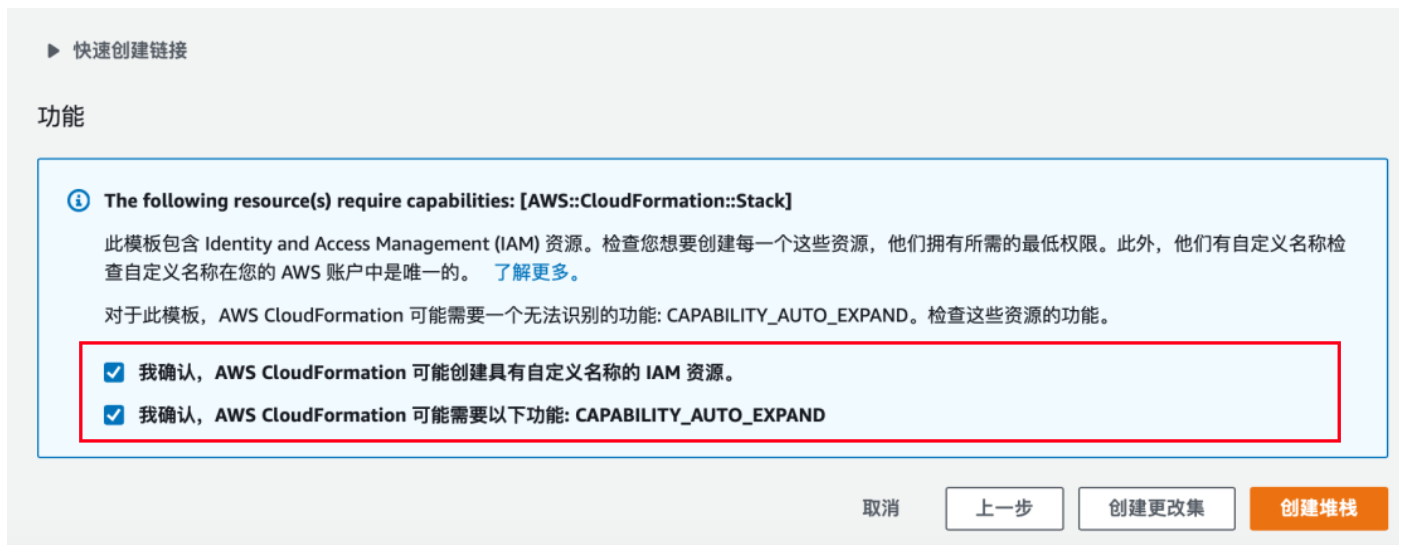
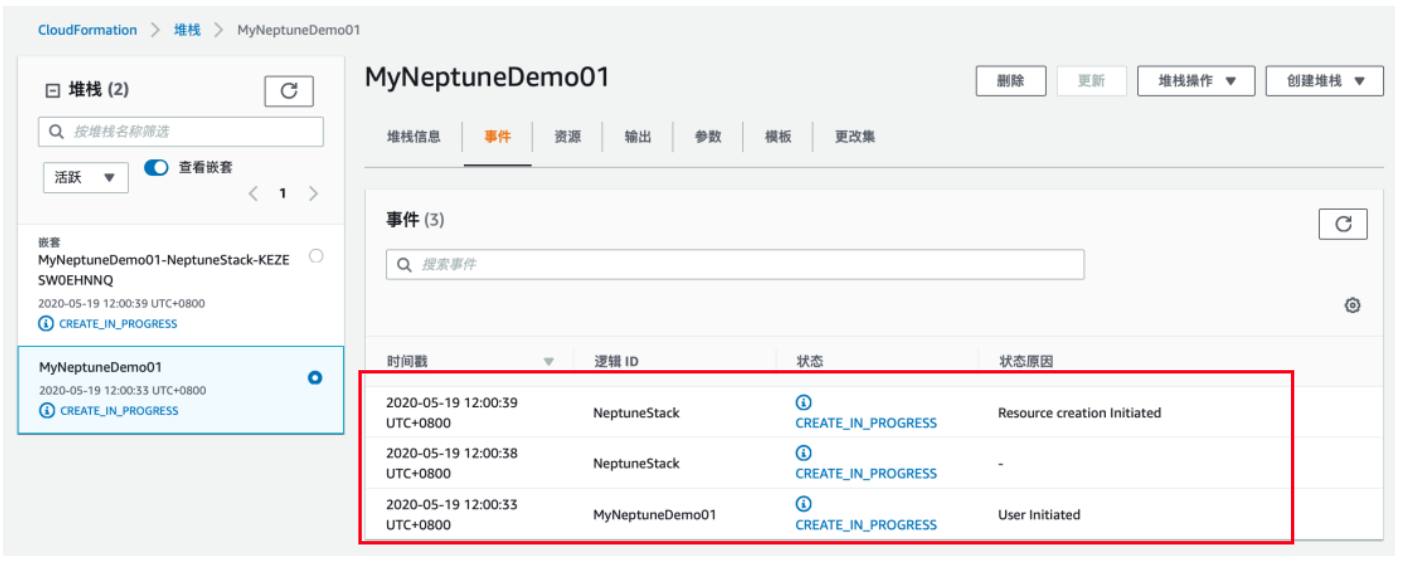
5) 请意红色方框里面的内容,如果中断请检查CloudFormation的日志
6) 整个创建过程大约需要10分钟,直接点击主模板查看相关的输出参数
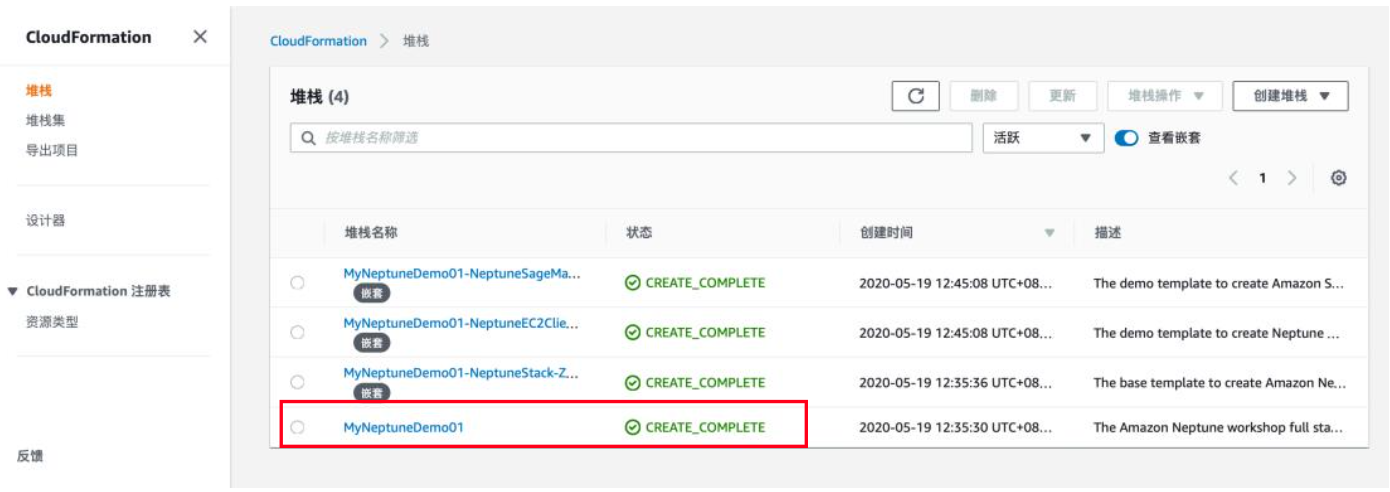
7) DBClusterEndpoint 是 Amazon Neptune 集群的访问入口,请直接复制出来
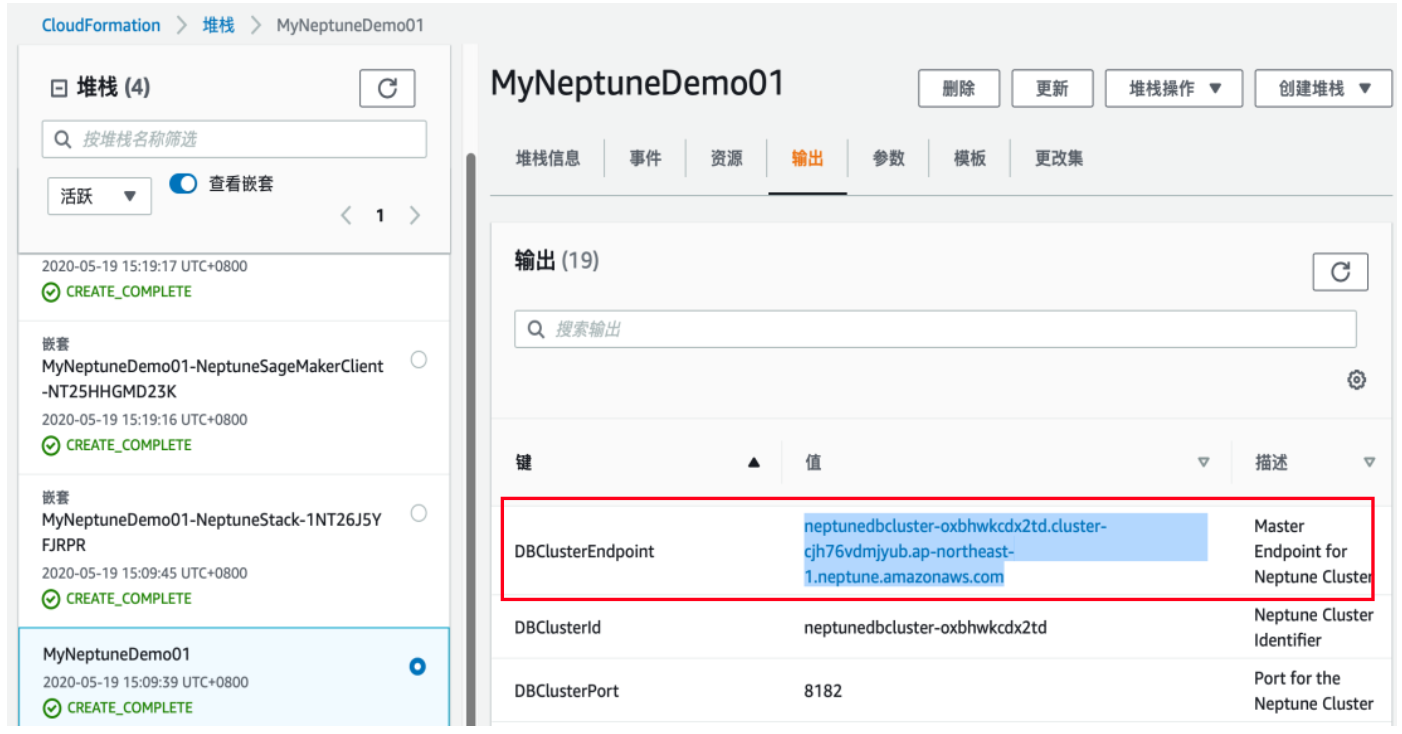
特别说明:由于运行中关联到的服务众多,请提前确保自己的帐号有足够的权限去运行 CloudFormation 模板,该模板会引用另外三个模板去创建所有资源,如遇出错,请检查相应的断点 位置,再去推导可能出错的原因。
2.1.2 配置 Amazon SageMaker
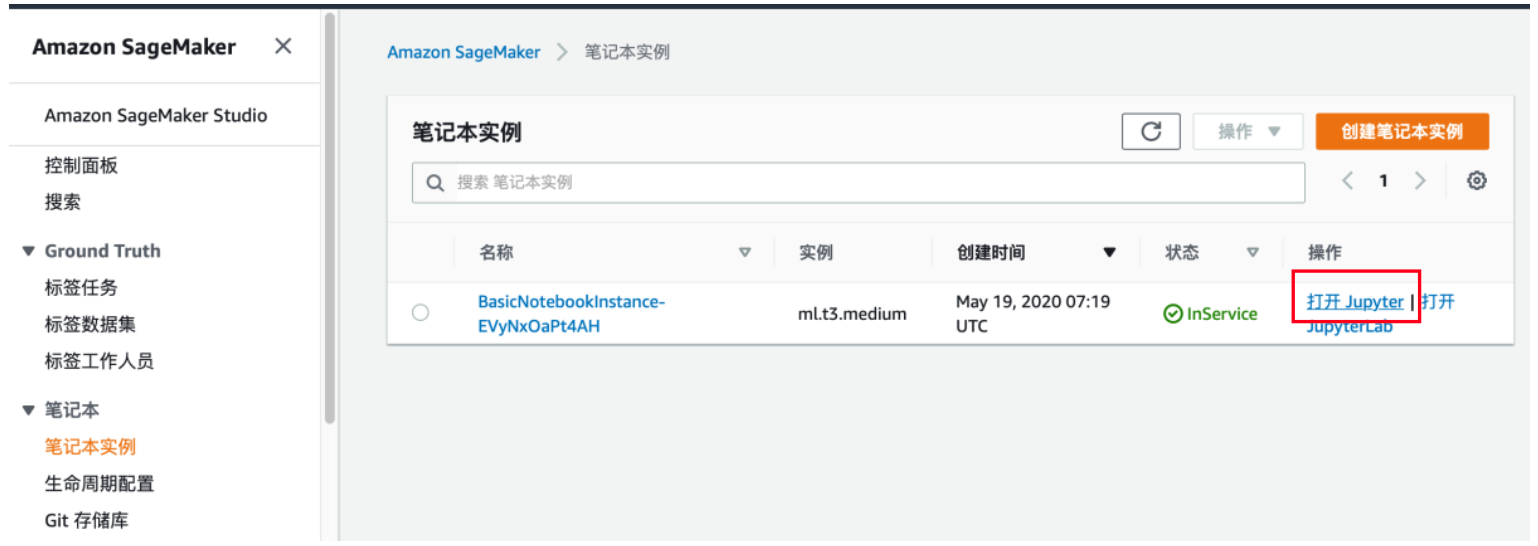
在 Amazon SageMaker 中主要需要配置 Neptune 集群的访问入口。在 AWS Console
打开 SageMaker,具体显示如下,请点击“打开 Jupyter”
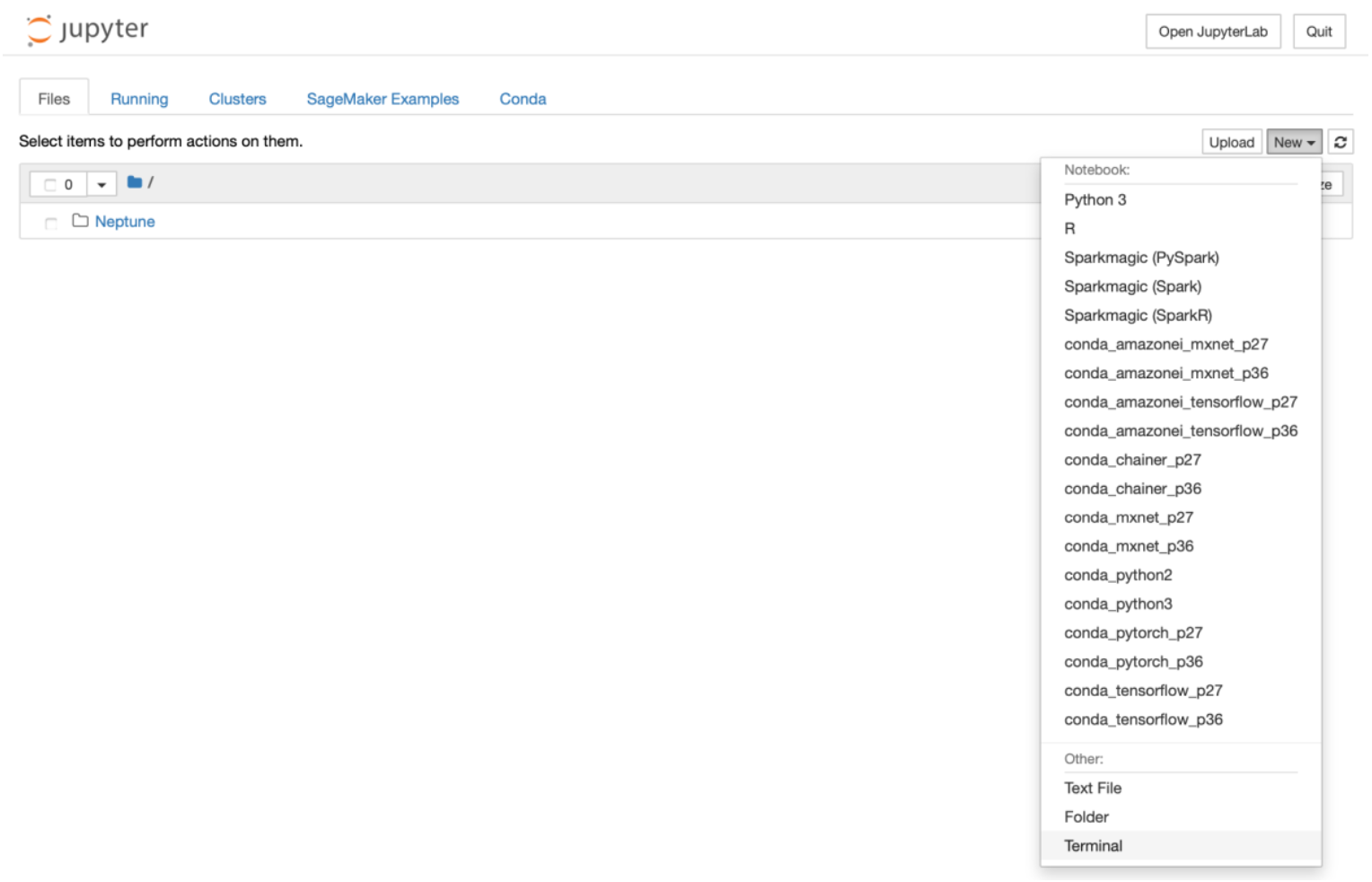
1) 请点击右上角的“New”->“Terminal”打开终端窗口
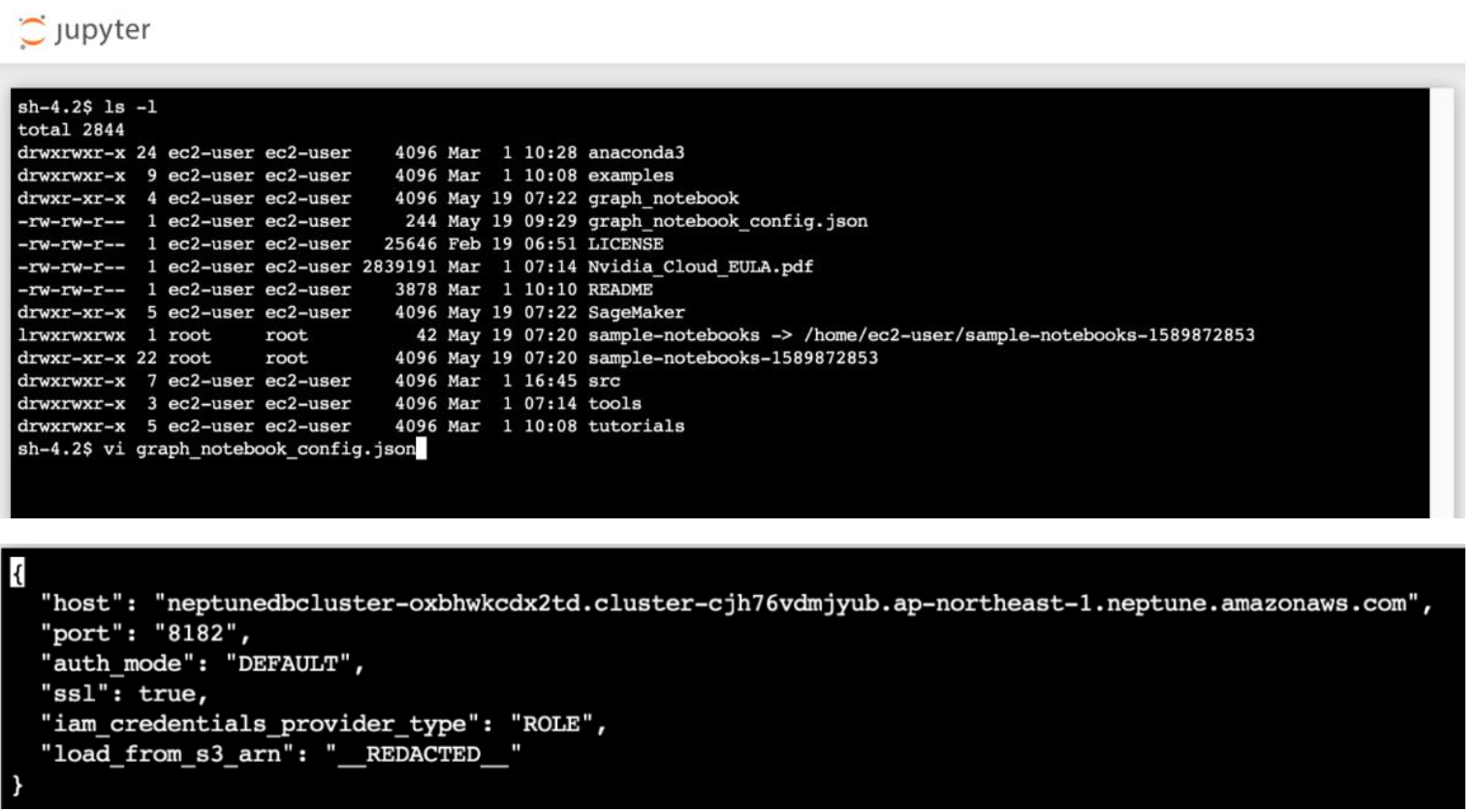
2) 直接 vi 编辑 graph_notebook_config.json 配置文件,把 host 的内容更改 Neptune 的 DBClusterEndpoint
3) 关闭终端窗口,退回到笔记实例界面
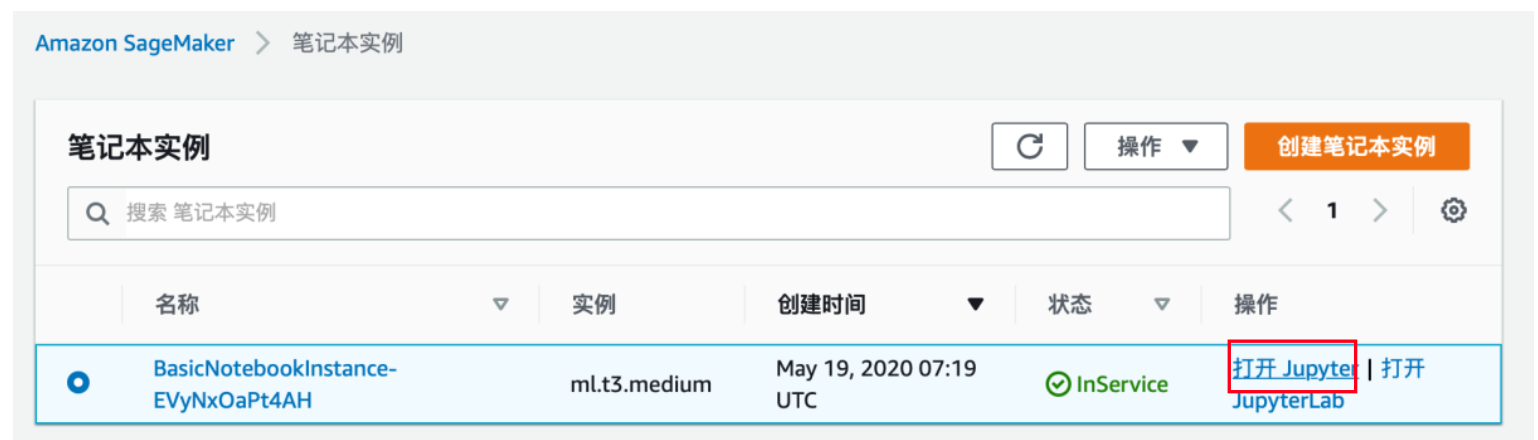
2.1.3 验证安装
1) 请点击“打开 Jupyter”
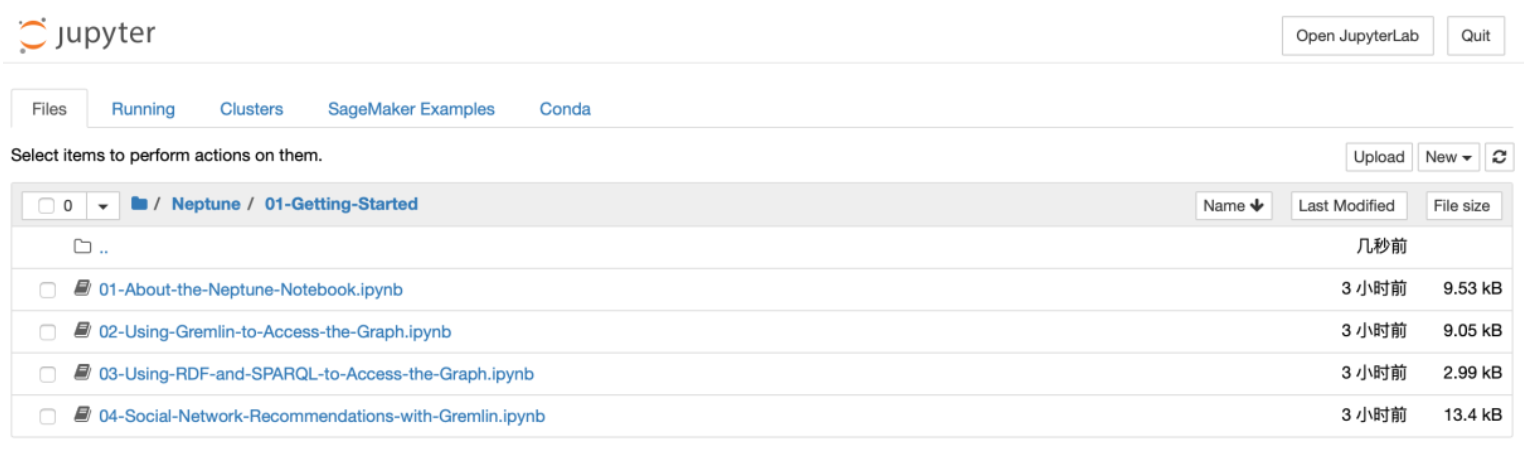
2) 再点击 Neptune 目录,再点击 01-About-the-Neptune-Notebook.ipynb,打开如下界面:
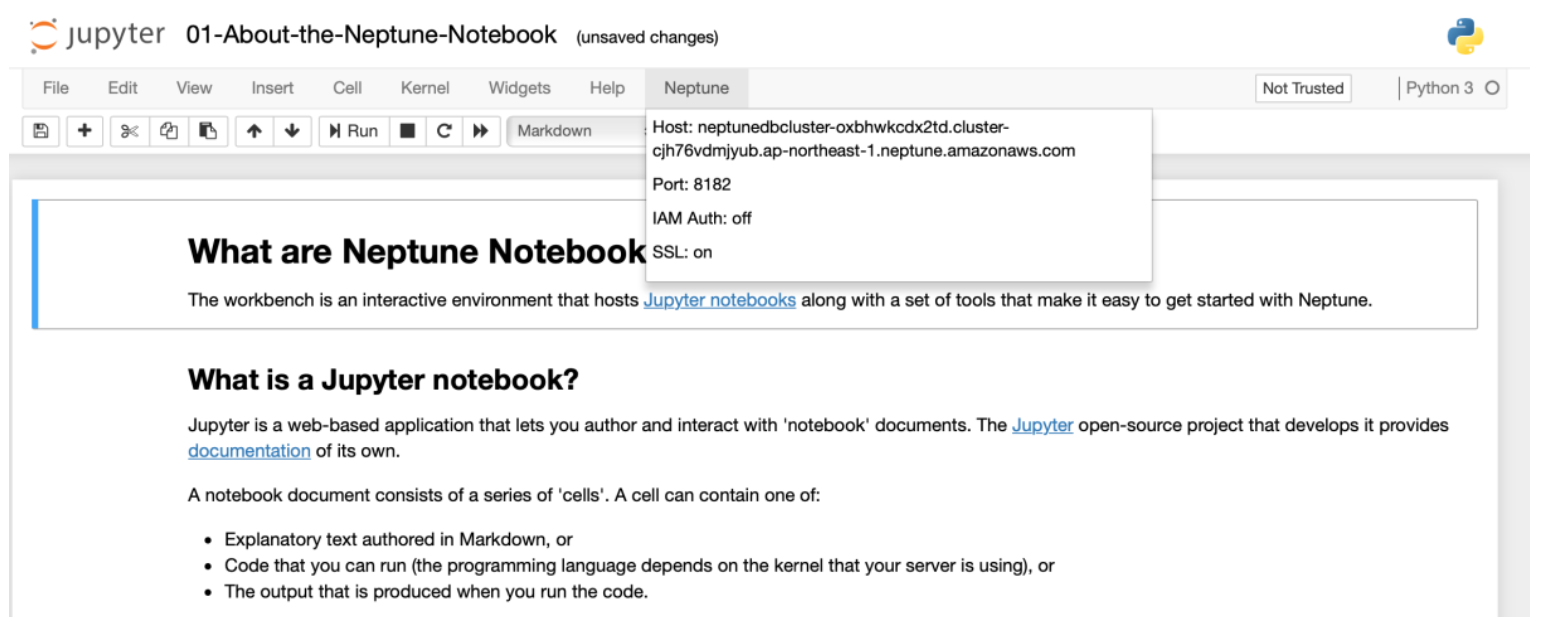
3) 拉到如下位置,选中 %status 框,再点击菜单栏的“Run”
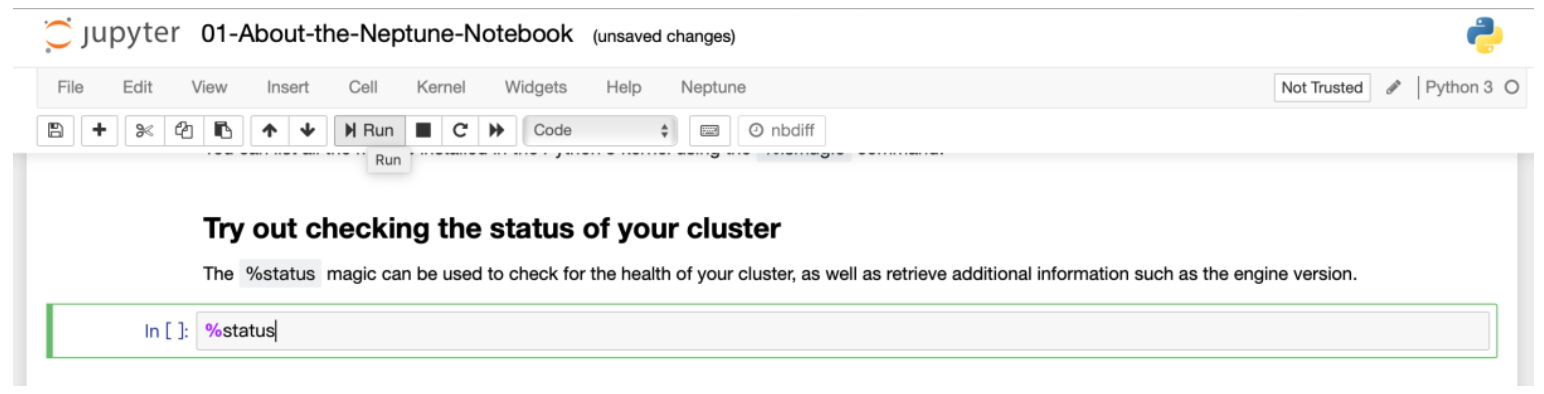
4) 如果运行正常,将会显示如下信息(集群状态、版本等等)
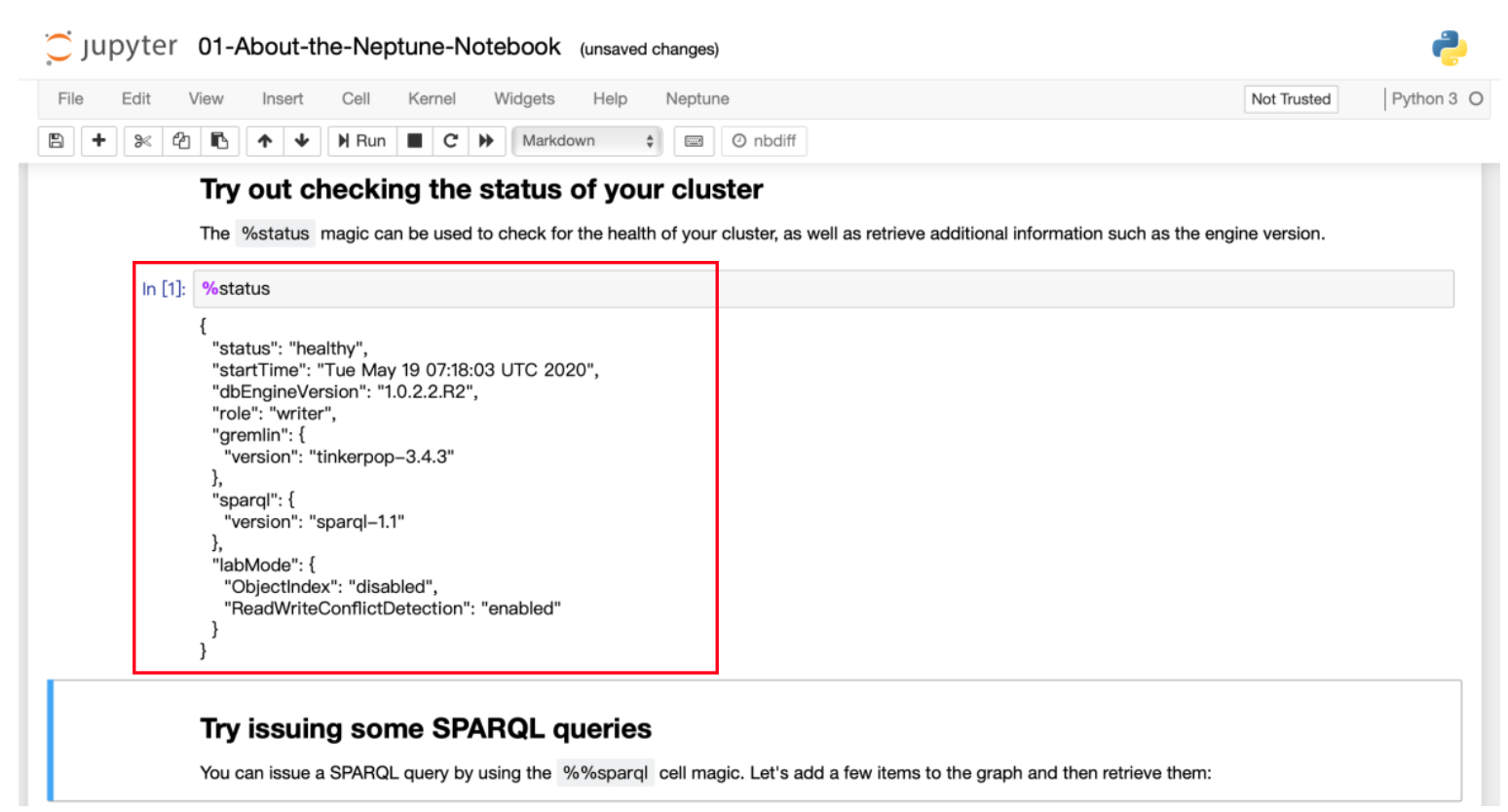
2.2 SPARQL 与 Gremlin 基本练习
目前有关 Amazon SageMaker 操作 Amazon Neptune 的文档还未正式发布,大家可 以按 SageMaker Jupyter Notebook 文档指定的内容进行练习。
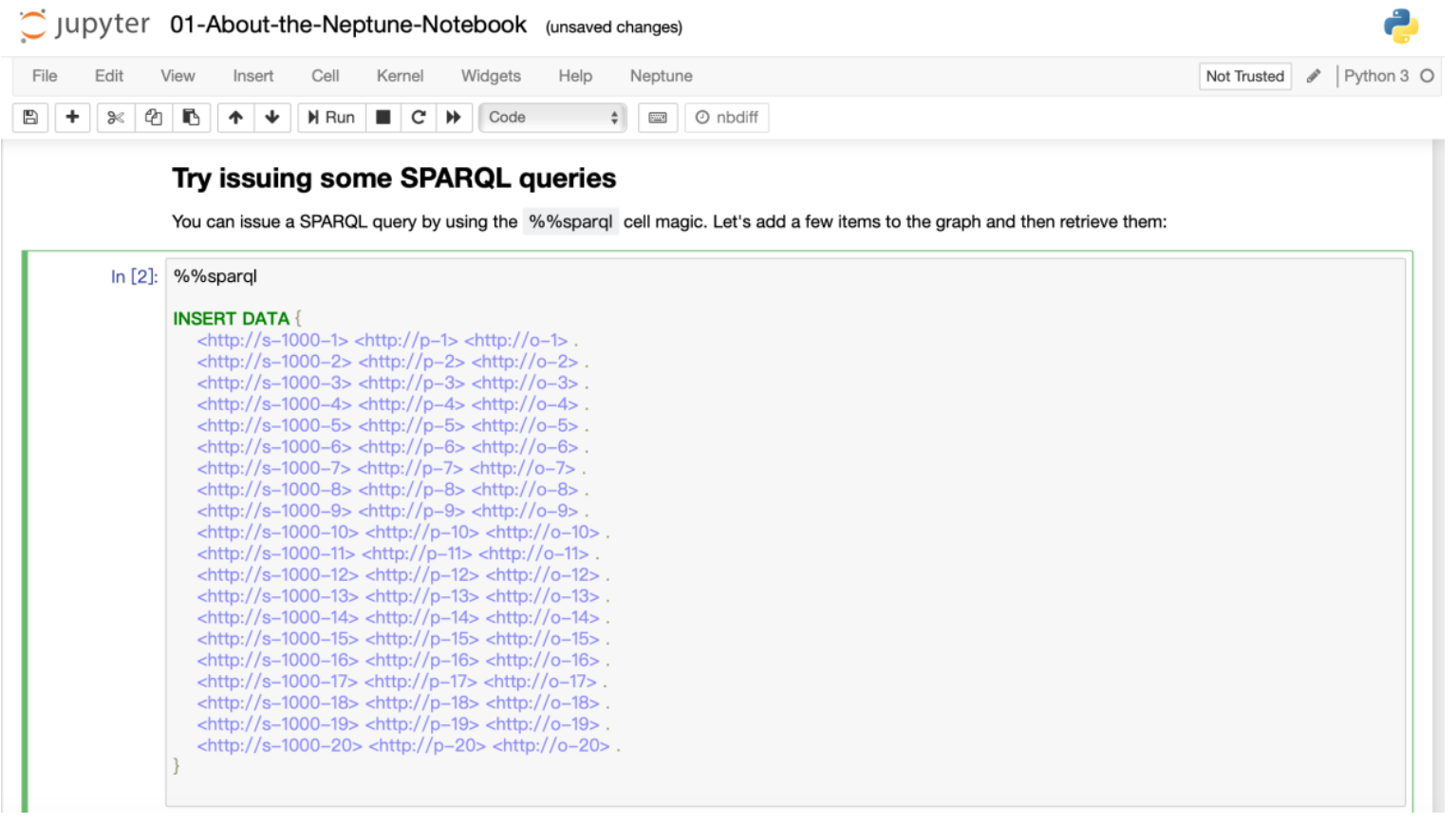
2.2.1 SPARQL on Jupyter Notebook 练习
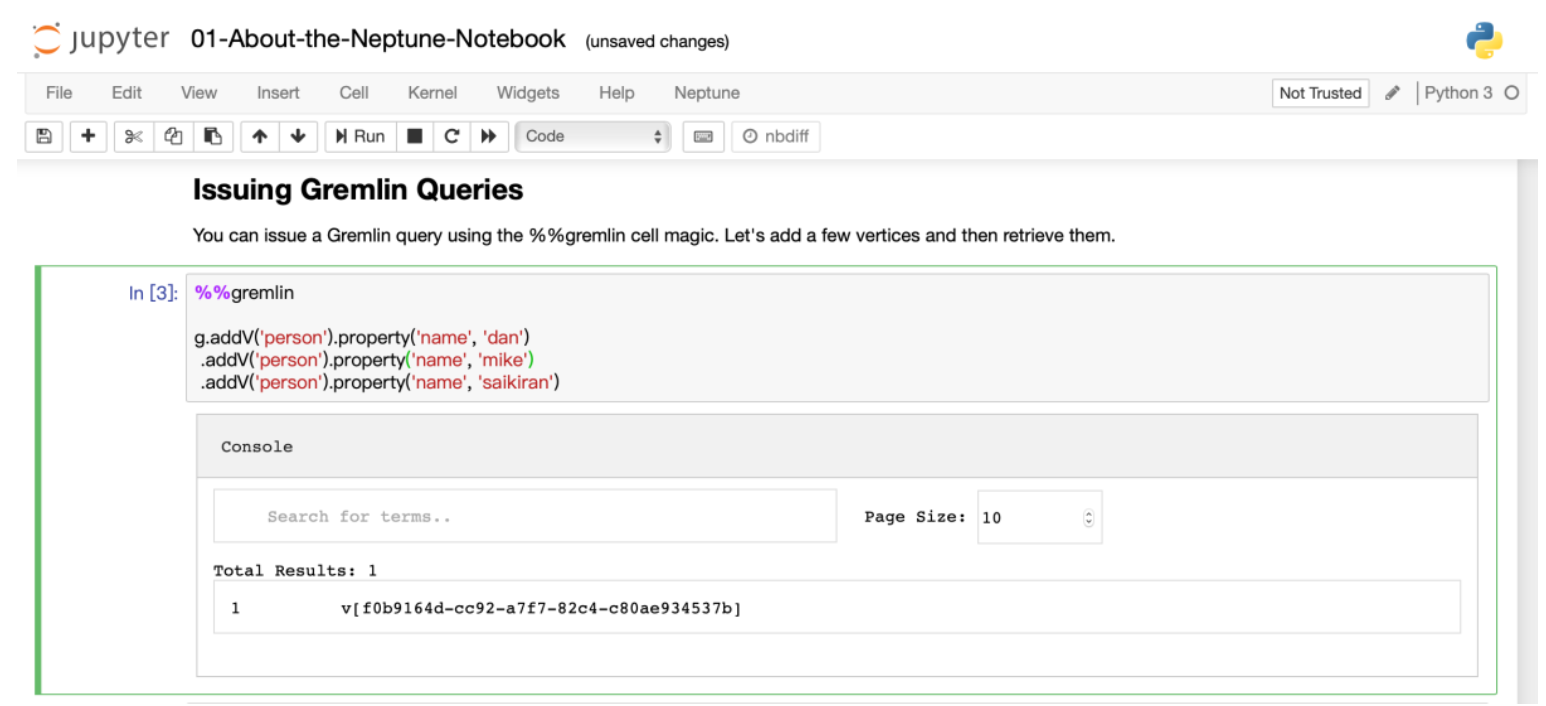
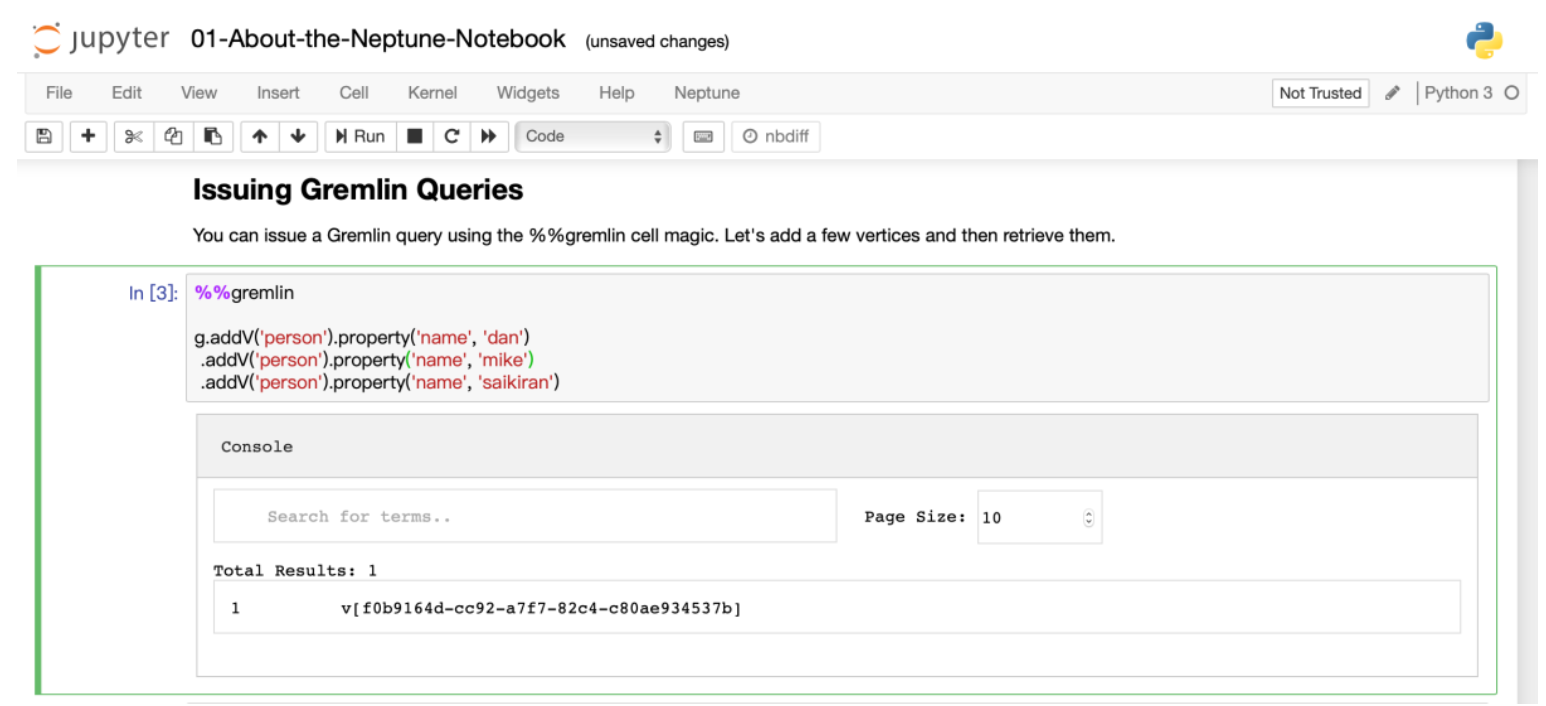
2.2.2 Gremlin on Jupyter Notebook 练习
2.2.3 SPARQL on Console/Workbench 练习(可选)
https://docs.aws.amazon.com/zh_cn/neptune/latest/userguide/access-graph-sparql-rdf4j- console.html
初始环境在 CloudFormation 都已经安装配置好 eclipse-rdf4j-3.2.0-sdk
可以直接通过 ec2-user 用户,SSH 到 EC2,按照文档操作即可。

### 进入 Console
eclipse-rdf4j-3.2.0/bin/console.sh
1

进入 Workbench
可以自行配置 Apache Tomcat 9.0,按 CloudFormation 模板的输出提示做 SSH 隧道访问即 可
http://localhost:8080/rdf4j-workbench/
2.2.4 Gremlin on Console 练习(可选)
https://docs.aws.amazon.com/zh_cn/neptune/latest/userguide/get-started-graph- gremlin.html
初始环境在 CloudFormation 都已经安装配置好 apache-tinkerpop-gremlin-console 可以直接通过 ec2-user 用户,SSH 到 EC2,按照文档操作即可。

进入 Console
apache-tinkerpop-gremlin-console-3.4.6/bin/gremlin.sh
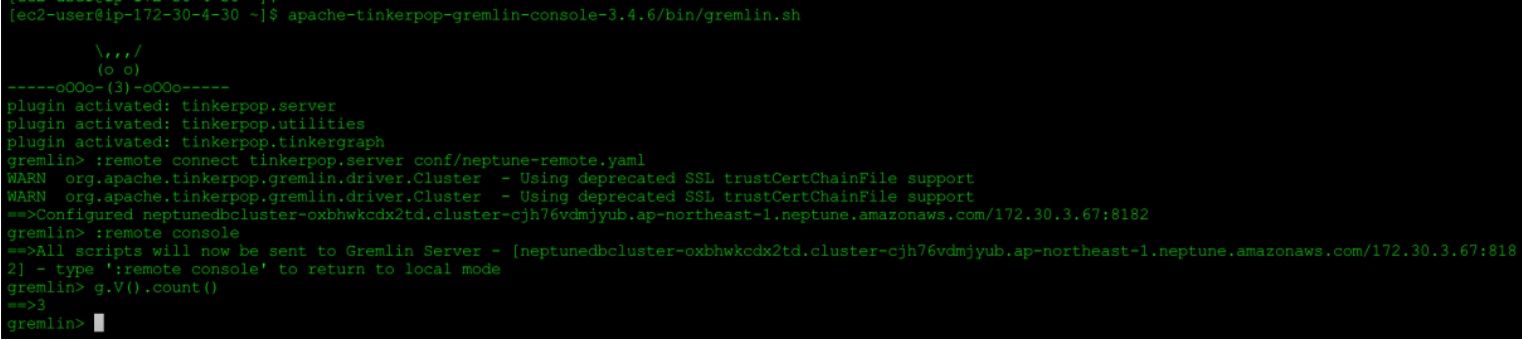
2.3 实验环境清理

附录
Amazon Neptune 文档中心
https://docs.aws.amazon.com/zh_cn/neptune/latest/userguide/intro.html
Amazon Neptune CLI 指南
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/neptune/index.html
Amazon Neptune 开发者资源
https://aws.amazon.com/cn/neptune/developer-resources/
Amazon Neptune 参考架构
https://github.com/aws-samples/aws-dbs-refarch-graph
Amazon Neptune 参考样例
https://github.com/aws-samples/amazon-neptune-samples
Amazon Neptune 数据导入
https://github.com/awslabs/amazon-neptune-tools
Migrating a Neo4j graph database to Amazon Neptune
https://aws.amazon.com/cn/blogs/database/migrating-a-neo4j-graph-database-to- amazon-neptune-with-a-fully-automated-utility/
Cypher for Gremlin adds Cypher support to any Gremlin graph database.
https://github.com/opencypher/cypher-for-gremlin
SQL2Gremlin
http://sql2gremlin.com/
PRACTICAL GREMLIN: An Apache TinkerPop Tutoria
http://www.kelvinlawrence.net/book/Gremlin-Graph-Guide.html
————————————————
版权声明:本文为CSDN博主「AI架构师易筋」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zgpeace/article/details/109404983
