在如下场景中,我们需要对A表数据进行筛选,然后将筛选后的结果跟另外一张表进行关联碰撞。如果筛选后的结果,内存可以放的下,就可以考虑使用RamIndexFilter来提升关联碰撞的性能。因为使用RamIndexFilter是直接使用索引进行关联的,并非采用暴力扫描的方式进行关联,关联碰撞性能会有大幅提升。
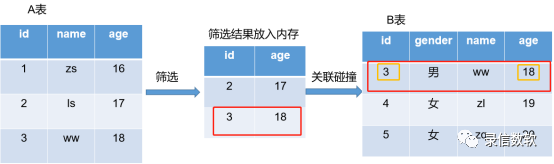
基本原理
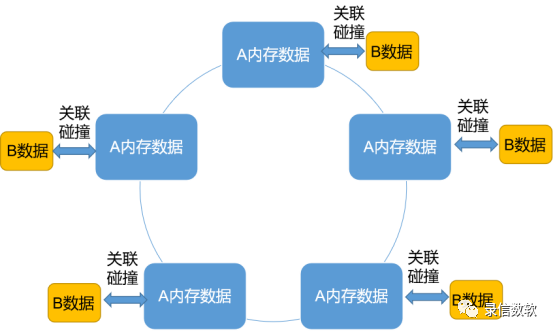
RamIndexFilter会先将检索匹配到的数据放到内存中;
然后将这些内存中的数据通过p2p的方式传递到每个待计算节点;
在executor中直接使用RamIndexFilter进行索引级别的筛选与过滤。
使用方法
1. 标签分词碰撞
该方法可以使用在分词的列,也可以用于非分词的列(只适用wildcard4类型的分词),termlike[N]必须至少匹配N个词 才能命中。“@termlike2@content@0”表示至少匹配2个词、匹配字段名为content的列、使用放入RamIndexFilter中的个字段。
RamIndexFilter@0000000001:10240:over_rand@ select explode(split('50,66,3,40,5,54',',')) @RamIndexFilter
select * from rif where partition like '%' and lucene_query_s like 'RamIndexQuery@termlike2@content@0@{RamIndexId:0000000001}'limit 10;
rif表中只有id为1的记录content字段值可以被放入RamIndexFilter中的数据命中两次(5、54),故查询结果如下图所示:

2. ID等值碰撞
用于匹配身份,MAC等ID类型。这个功能经常用来替代exists in 的查询。
RamIndexFilter@0000000001:10240:over_rand@ select explode(split('50,66,3,40,5,54',',')) @RamIndexFilter
select * from rif where partition like '%' and lucene_query_s like 'RamIndexQuery@term@age@0@{RamIndexId:0000000001}'limit 10;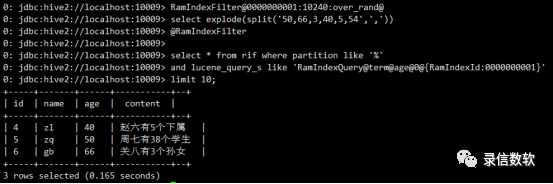
3. 带有范围的筛选,如时间
这里的query是lucene的query,TO 与 AND 必须是大写,否则会报错。
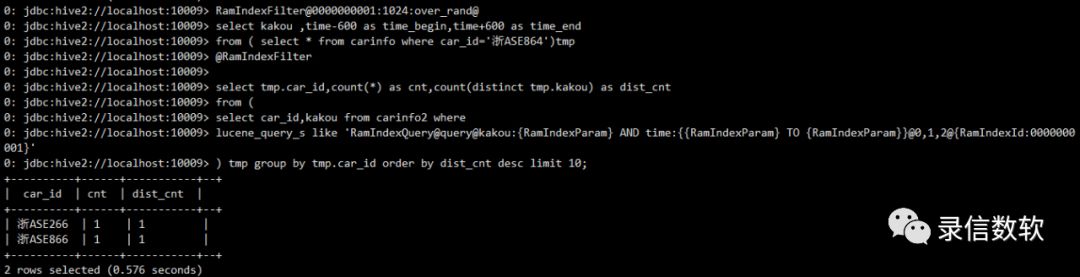
RamIndexFilter@0000000001:1024:over_rand@ select kakou ,time-600 as time_begin,time+600 as time_end from ( select * from carinfo where car_id='浙ASE864')tmp @RamIndexFilter
select tmp.car_id,count(*) as cnt,count(distinct tmp.kakou) as dist_cntfrom (select car_id,kakou from carinfo2 wherelucene_query_s like 'RamIndexQuery@query@kakou:{RamIndexParam} AND time:{{RamIndexParam} TO {RamIndexParam}}@0,1,2@{RamIndexId:0000000001}' ) tmp group by tmp.car_id order by dist_cnt desc limit 10;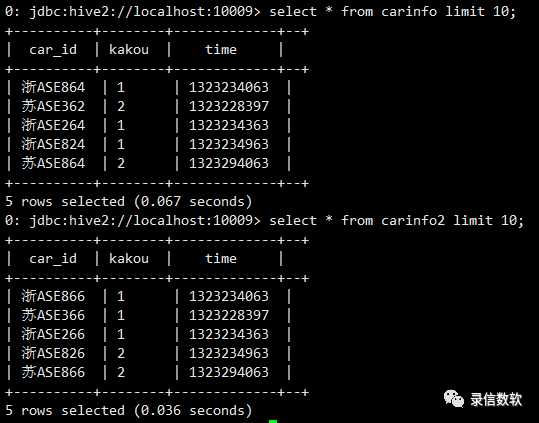
原文链接:https://mp.weixin.qq.com/s/ldoCqrik0PyTKDyCbecIlw
