这道题,我相信很多前端从业者都知道,它本质上来说并不复杂,但是却可以有很深远的扩展,终核心的主题其实就是异步的执行,其中对于题目的解法,还涉及到一些作用域的知识。那么我们以简版的题目入手,逐步深入,一点点的剖开这道题所涉及到的知识概念和体系。
我们先来看这道题:
for (var i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000); }
这个结果想必大家都能很快的说出来,这段代码会在刷新页面一秒后一次性的打印6次6。这是为啥呢?我们来分析下这段代码的实际执行顺序:

var i; for (i = 0; i < 6; i++) {} setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000); setTimeout(() => { console.log(i); }, 1000);
我们看,其实这段代码可以这样来理解,setTimeout并不是按照我们所想的那样,在循环的内部依次执行的,原因在于setTimeout是一个异步回调的宏任务,他会在执行到该代码的时候,把传入setTimeout的回调函数及参数信息存在一个延迟队列中,并不是消息队列噢,是延迟队列。当延迟队列发现,诶?时间到了,就会把延迟队列中的回调函数包装成事件插入到消息队列中,如果此时消息队列中没有其他待执行的任务在前面,那么就会立即执行该延迟事件。
所以由于异步回调的原因,导致了setTimeout中的回调函数并不是在for循环体内部执行的,而是等待for循环执行结束之后,并且执行完循环体后又i++了一次,等待一秒后,才一次性的执行了6次setTimeout中的回调。
一秒后,6次6。一秒的延迟是因为我们每次循环,添加的到延迟队列中的事件所包含的信息就是延迟一秒,因为没有顺序执行,所以并不会出现每次循环执行一次,就导致了这样的情况。而6次,则是因为循环体循环了6次,从0到5,一共6次。而打印出6则是因为在i = 5的后一次循环执行完循环体后,还执行了i++,然后setTimeout中异步回调所访问的i是全局作用域下的i,于是i在执行异步回调的时候就是6了。
好啦,我相信大家已经知道为什么这样写代码与我们的预期不符。那,要怎么样才能符合我们的预期呢?那么在这里确定一下,我们的预期是:每隔一秒,打印一次对应的数字。也就是秒打印0,第二秒打印1,这样子。
一、部分解决方案之IIFE
种不完全的解决方案就是利用IIFE的特性,形成了一个闭包,我们来看代码:
for (var i = 0; i < 6; i++) { (function (j) { setTimeout(() => { console.log(j); }, 1000); })(i); }
我们用一个匿名立即执行函数来包裹整个异步的setTimeout部分,然后把循环中的i作为匿名函数的参数传入,打印的就是这个传入的参数即可。这样,我们就可以在控制台看到顺序打印的0~5,但是还有个问题没有解决,我们看到0到5是在一秒之后,一下子打印出来的,每隔一秒的需求还是没有做到。
每秒的事情我们稍后再说,我们先分析下为什么用立即执行函数就能解决顺序打印的问题,为什么用立即执行函数就不再是6个6了呢?其实问题得到解决的根本原因在于局部作用域与全局作用域。函数会产生一个局部的作用域,当我们使用立即执行函数包裹异步时,异步回调所取的j其实是立即执行函数所传入的参数i,当立即执行函数执行的时候,会产生一个执行上下文栈帧加入到执行上下文栈的栈顶,而每一个栈帧中会存储一些上下文信息。这些上下文信息中包含了很多东西,比如arguments、比如变量环境、词法环境、this,作用域指针等等,这里不再展开,有兴趣可以去学习下执行上下文栈。
那么我们来分析下上面的代码是怎么执行的,每一次循环的时候,都会执行立即执行函数,立即执行函数会形成一个栈帧插入到栈顶,那么在执行到立即执行函数中的异步回调setTimeout的时候,会在延迟队列中添加一个回调函数,这个回调函数要去取j,而执行上下文栈中对应的栈帧有这个arguments参数j,所以回调函数取到的j就是对应循环的i。当函数执行完毕,栈帧出栈,下一次循环再执行类似的步骤,入栈,执行代码读取栈中的arguments的j,出栈。
那么,核心的点来了,作用域是真的,执行上下文也是真的,但是在立即函数执行完毕,把setTimeout的回调加入到延迟队列中后,执行上文对应的栈帧已经出栈了,我从哪取到的j呢?答案就是闭包,不信你看:

这个图有点大,大家看到这里有个Closure,就是延迟队列中存储的事件触发执行时所取到的j。在上面的代码中,每一个延迟队列中的回调函数都会对应一个闭包,从而取到了j。
Ok,我们现在解决了顺序打印的问题,但是每秒打印的问题还没解决。在这样的代码情况下,有一种破坏性的解决办法:
for (var i = 0; i < 6; i++) { (function (j) { setTimeout(() => { console.log(j); }, 1000 * (i + 1)); })(i); }
我们在每次循环的时候,让每次加入延迟队列中的回调事件的时间按照循环次数来递增,但是实际上,这样看起来解决了问题,但是却并不是我们想要解决的方式,其实我们希望的执行方式是:每次循环都会在一秒后执行打印。换句话说,希望异步可以像同步那样的执行。诶?你是不是想到了什么?嗯~~我们先看别的解决方案。
二、部分解决方案之块级作用域
通过IIFE来解决打印顺序的问题,其实是利用了函数作用域级栈中存储的信息搞定的。那么我们还有另外一种生成一个局部作用域的方式,就是块级作用域:
for (let i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000); }
那么我们直接看破坏性的解决每秒打印的问题,其实方法跟IIFE的时候一样,加秒呗:
for (let i = 0; i < 6; i++) { setTimeout(() => { console.log(i); }, 1000 * (i + 1)); }
其实块级作用域也好,函数作用域也罢,其核心原理几乎都是一致的,就是通过作用域来存储对应的变量,当异步回调加入到延迟队列的时候,取的是对应作用域的值,而不是全局作用域。
而块级作用域,实际上是把变量信息存储在了执行上下文栈帧中的词法环境中的,但是这里,注意这里,在执行上下文栈中仅仅只有一个全局的根栈帧,每一次循环都会绑定词法环境中的变量i,就有点像闭包一样。所以,在异步回调加入到延迟队列的时候,就会去词法环境中取到对应的i变量。

我们可以通过debugger看到,这里不再是closure,而是Block,也就是块级作用域。
那么我们来简单分析下上面的代码是如何执行的:每次循环都会生成一个新的块级作用域,当setTimeout把异步回调函数加入到延迟队列中时,会在其所依赖的上下文中存储异步回调中使用到的变量i。这里核心的点就是,加入延迟队列中的异步回调,已经有了所需要的对应的数据信息。
三、部分解决方案之setTimeout的第三个参数
还有一种解决方案,就是利用setTimeout的第三个参数,既然如此,我们就得先来了解下setTimeout的参数都有哪些:
var timeoutID = scope.setTimeout(function[, delay, arg1, arg2, ...]); var timeoutID = scope.setTimeout(function[, delay]); var timeoutID = scope.setTimeout(code[, delay]);
我们可以看到,setTimeout的个参数可以是一个函数,或者一段可执行的代码:
for (var i = 0; i < 6; i++) { setTimeout(console.log(i), 1000); }
这样写也没啥问题。但是并不推荐这样写,因为浏览器会像执行eval包裹的可执行字符串那样来执行这段代码,所以我们其实很少这么使用,第二个参数不用说,就是我们需要延迟执行的时间,诶?setTimeout不仅有第三个参数,还有第四五六七八九十个参数,换句话说,setTimeout的从第三个参数开始,后面可以加任意个参数,这些参数是可选的附加参数,一旦定时器到期,它们会作为参数传递给个参数的function。
注意!一旦定时器到期,就会把它们作为参数传递给function。那我们先试一下:
for (var i = 0; i < 6; i++) { setTimeout( (j) => { console.log(j); }, 1000, i ); }
这样也行,一点问题没有,也是隔了一秒,一下子都按顺序打印出来了。但是它的原理是咋回事呢?看起来好像跟前两种解决方案类似,都是每一个异步回调在加入到延迟队列中,触发执行的时候去某个地方取到了对应的数据。我们还是debugger一下来看看:
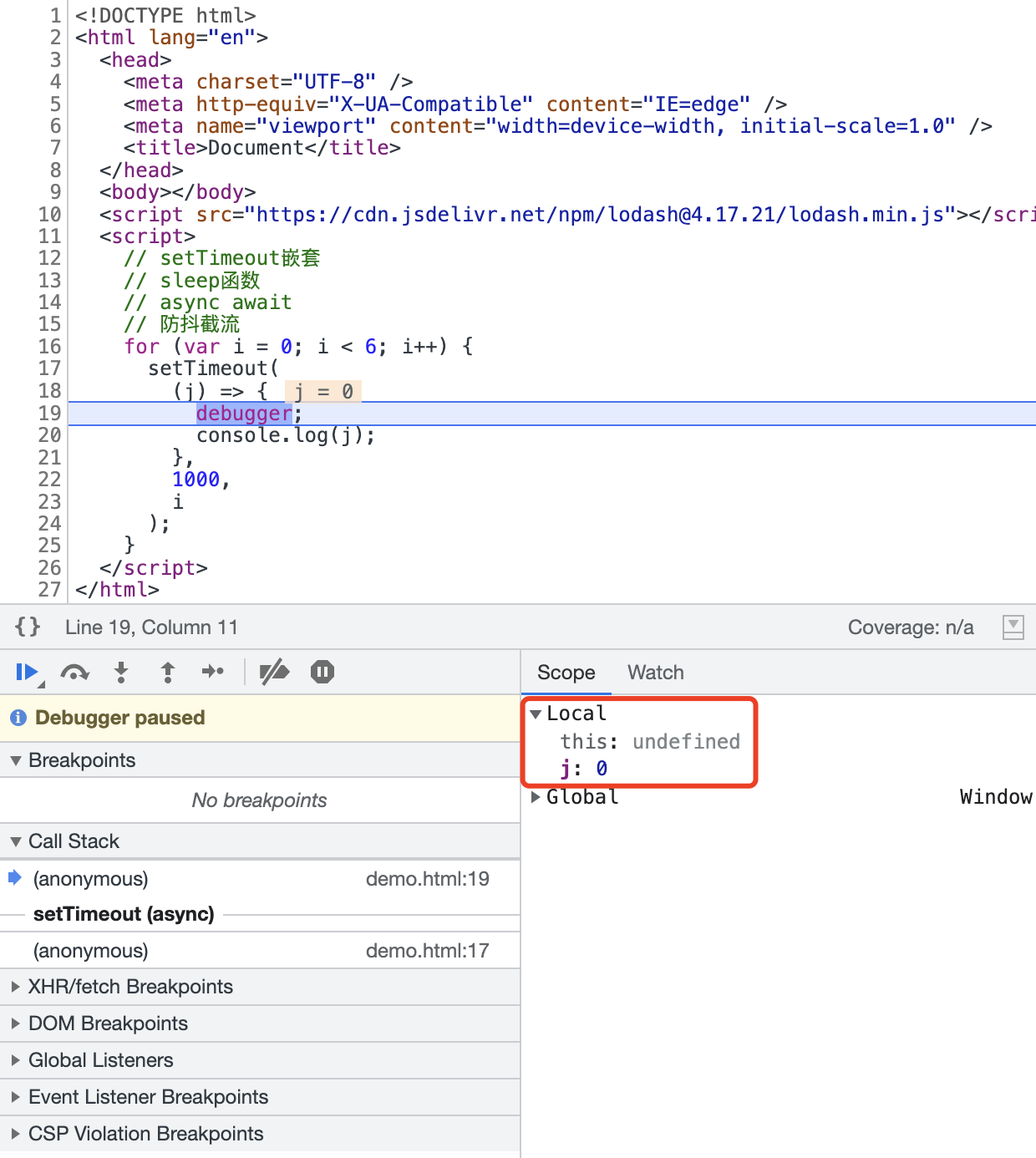
我们看setTimeout的第三个参数,所存储的位置跟前面两种解决方案完全不同,它存在了Local里,也就是自己的局部作用域。至于这种情况的秒数问题我就不写了吧。好吧~
四、部分解决方案总结
OK,那我们先来总结下这三种场景的解决方案,这三种解决方案都是利用了语言的特性在不同的内存位置存储对应的数据,但是本质上来说并没有解决核心的需求,也就是我们之前说过的,希望异步像同步那样来执行。仅仅只是解决了顺序打印的问题,既然我想要顺序打印,不考虑每隔一秒的话,那我这样不就行了:
for (var i = 0; i < 6; i++) { console.log(i); }
那非要异步隔一秒的话就这样:
setTimeout(function () { for (var i = 0; i < 6; i++) { console.log(i); } }, 1000);
这不是更好?你扯那些臭氧层有啥用。所以从根本上讲,以上三种方法,都算不上是解决方案,只是不得已可以实现的手段罢了。
但是我还有个问题,就是闭包也好、块级作用域也罢,它们是如何查找到对应的要打印的那个j的呢?首先,作用域是在函数声明时就已经确定好的,存储在执行函数的执行上下文栈帧中的。其次,闭包则像是某一个函数的背包,在它自己的执行上下文栈帧中找不到的时候,就会去闭包中找。后,setTimeout的第三个参数会作为function的参数,则是存储在了执行上下文的aguments中,aguments也是在执行上下文的栈帧里。你知道我说的这几种情况对应的以上哪种解决方案的吧?
五、破坏性解决方案之递归嵌套
破坏性解决方案,什么意思呢?就是与本篇开头的那段代码无论在形式上还是代码的编写上,都可能会脱离原貌甚至是完全不同,但是却可以实现我们真正的目的:每隔一秒顺序打印。换句话说,我们完全抛弃循环内异步的形式,只要能实现每隔一秒顺序打印即可。那么我们的目的也就变成了如何实现每隔一秒顺序打印的问题。
那么我们先看种解决方案,通过回调的方式,来试试。
setTimeout(() => { console.log(); setTimeout(() => { console.log(1); setTimeout(() => { console.log(2); setTimeout(() => { console.log(3); setTimeout(() => { console.log(4); setTimeout(() => { console.log(5); }, 1000); }, 1000); }, 1000); }, 1000); }, 1000); }, 1000);
这代码是不是很好看,从形式上如此的美妙,匀称,从编码上如此的清晰、易懂。完美的实现了我们的需求。我相信你看到这肯定会笑出声,嗯~我也一样。哈哈哈哈哈。
虽然你笑出了声,但是我还是要严肃的解释下上面的代码。嗯~~就是异步回调里嵌套异步回调,这样子其实每一次都在延迟队列中加入了一个事件,当时间到了执行函数的时候就又加进去了一个,如此往复。
这代码虽然好看,并且清晰易懂,但是着实不那么优雅,我们想办法怎么让上面的代码更优雅一点呢?
function run(num) { if (num > 5) return; setTimeout(() => { console.log(num); run((num += 1)); }, 1000); } run(0);
其实这代码也很好理解,跟我们上面的嵌套的方式没有任何区别,无非就是递归罢了,在每一次run方法执行的setTimeout中再调用run方法,递归的终点就是num > 5的时候,所以如果强硬的类比一下,递归就是循环的另外一种形式罢了。这个玩意没啥技术难度。但是确实是一种解决方案。
这里额外提一句,死循环和栈溢出有啥区别?嗯~~死循环可能会导致栈溢出,但是栈溢出不一定是因为死循环。
首先死循环是指代码形式,是指你的代码一直的执行下去(一直执行就可能会重复的声明某些变量,占用内存,就算你就是一个空的死循环,也会一直占用执行队列导致卡死),没有终点,于是浏览器或者宿主环境会根据你的代码,在编译的时候解析到了死循环的代码并抛出错误。而栈溢出,实际上可能是由于死循环导致的执行上下文栈的无限叠加,超出了宿主环境允许的大栈帧的数量,从而导致的错误。
六、破坏性解决方案之促销秒杀
额~~其实这个标题有点跑题了,但是它看起来很吸睛,让不懂的人很好奇,懂的人不珍惜,额~~~没事,我纯粹为了押韵。继续继续~~
额~~没办法,因为标题跑题了,我不得不解释下促销秒杀的实现思路大概是什么样的。
首先,促销秒杀意味着在某一个时间段会有远超平峰时期的并发,会产生一个服务器请求处理的拥堵,前面收到的数据还没处理完,后面的马上又来了。所以,大量数据在短时间内的并发会造成服务器的崩溃。当然,这种场景也可以有另外一种叫法,比如Dos或者DDos攻击,稍微扩展一下,大家知道即可。
其次,要解决这样的场景造成的服务器阻塞问题,并不仅仅是服务器中存在,在前端范畴内也是有类似的场景的,比如VueRouter中实现的runQueue方法就是为了解决这样的问题。那么解决方案说起来也很简单,就是我们把所有的请求都放到一个队列或者也可以说是数组中,从头开始调用执行数组中的异步方法,当异步结果返回,再去调用下一个。
那么,我们来看下代码的实现:
// 一个队列,我们模拟一下,在队列中加入了几个方法。 const queue = []; for (let i = 0; i < 6; i++) { queue.push(function () { return new Promise((resolve, reject) => { setTimeout(() => { console.log(i, new Date()); resolve(i); }, 1000); }); }); } // 执行队列的方法,主要用来增加步数,也就是遍历队列 function runQueue(queue, fn, cb) { const step = (index) => { if (index >= queue.length) { cb(); } else { if (queue[index]) { fn(queue[index], () => { step(index + 1); }); } else { step(index + 1); } } }; step(); } // 具体的执行逻辑 function run(hook, next) { hook().then((val) => { next(val); }); } // 启动 runQueue(queue, run, () => { setTimeout(() => { console.log("finally", new Date()); }, 1000); });
我们来看上面完整的代码,其实核心的runQueue方法是从VueRouter的源码抄过来的,嘿嘿。
首先,们虚拟了一个queue数组,这个数组用来存储所有的异步方法,我们用Promise包裹了一下,终会返回这个Promise。Promise内部就是一个一秒之后打印i和当前时间的setTimeout用来模拟ajax请求,或者其他异步逻辑。
接下来重点来了,就是这个runQueue方法,它接收一个queue作为要执行队列的数据列表,fn则是作为执行器,执行每一个queue中的事件,cb呢就是回调,当queue清空了之后会执行这个回调。runQueue方法的核心是一个step,step内部则其实很简单,判断传入的index,如果大于queue的长度,说明整个queue都执行完毕,则执行回调。否则,那么则继续执行fn执行器来执事件,其第二个参数则是开始下一次执行。
接下来就是执行器方法,也就是runQueue的第二个参数要接收的方法,很简单,就是调用事件,并且在确定有了结果之后执行next,也就是step。
后,我们执行runQueue方法,传入queue,run,以及后的cb,啊~~这里的cb我为了好看,也延迟了一秒,无所谓,你在本章的场景下,不写也行。
我们好好看看上面的代码,并不复杂,其实它的本质跟我们上一部分的嵌套来说没什么区别,只不过不是setTimeout单纯的嵌套,而是通过Promise的链式调用嵌套。只不过我们在执行的过程中加入了步数和回调,来让我们可以更细节的操作整个队列执行的过程,为啥要更细节的操作整个执行过程呢?因为针对复杂场景,很多地方都需要更加细腻的处理。当然,在本章的场景下,其实我们可以简化下上面的代码:
const step = (index) => { if (index > queue.length) return false; if (queue[index]) { queue[index]().then(() => { step(index + 1); }); } else { step(index + 1); } }; step(0);
看到没,其实就一个step方法……其实就是通过Promise的链式调用的能力,在then的时候执行下一个事件,当然也可以不用then,也可以用finally,让嵌套看起来好看了些。这代码就很好理解了吧~~
七、破坏性解决方案之Generator
generator是什么,有什么,怎么做,我不会说的很详细,这不是本篇文章的重点。如果你不清楚generator的作用和效果,为避免不分轻重我会尽可能简短的介绍清楚,但是如果我没说清楚,或者你还是没理解,请一定参考:generator函数的语法和generator的异步应用以及Iterator。
generator可以理解为一个状态机,它的内部会使用yield表达式产出状态,我们可以这样来创建一个generator函数,通过执行generator函数,会返回一个遍历器对象,也就是Iterator对象:
function* gen() { yield console.log("hello"); yield console.log("zaking"); } var genItem = gen(); genItem.next(); genItem.next(); console.log(genItem.next());
我们通过funciton*来声明一个Generator函数,内部有两个状态,这两个状态是一个console语句。然后我们通过执行gen这个Generator函数后,得到了genItem这个Iterator遍历器对象,然后就可以通过调用遍历器对象的next来获取到Generator函数内部的状态,当遍历结束后,再执行genItem.next()则会得到拥有value和done字段的对象,此时的done是true来标识遍历结束。当然,这只是同步执行前提下的Generator函数,比较好理解。
由于 Generator 函数返回的遍历器对象,只有调用next方法才会遍历下一个内部状态,所以其实提供了一种可以暂停执行的函数。yield表达式就是暂停标志。我们还可以把上面的代码写的丰富一点,便于理解:
function* gen() { console.log("1"); yield "hello"; console.log("2"); yield "zaking"; console.log("3"); } var genItem = gen();
console.log(genItem.next());
这样会打印出:

但是假设你不执行genItem.next()则不会打印任何内容也就是不会执行任何代码,换句话说,通过Generator生成的对象,只有调用该对象的next方法才会执行,直到在函数内部遇到yield则会暂停,会返回yield后面的内容到函数外部。再一次执行genItem.next():

后一次执行genItem.next():

这样,则整个Generator函数执行完毕,你看,我们有两个yield,但是其实要三次next()方法的调用才能真正的执行完整个Generator函数,那我要想知道什么时候结束了,只能通过判断调用next()返回的对象的done来确定。
以上都是同步执行,异步执行怎么办呢?其实看起来也并不复杂:
function* gen() { yield setTimeout(function () { console.log(1, new Date()); }, 1000); yield setTimeout(function () { console.log(2, new Date()); }, 1000); } var g = gen(); g.next(); g.next();
上面的代码打印出来是这样的,隔了一秒,然后:


换句话说,这并不是我们想要的,这样只是解决了顺序打印的问题,但是并没有解决每隔一秒的问题。要解决这个问题,我们得先考虑一个问题,就是当我们使用Generator来执行异步操作的时候,我怎么能知道什么时候交回执行权呢?只有异步执行有了结果的时候,才需要交回执行权,但是我们又不知道什么时候异步才会有结果,答案是只有回调才能知道。所以,针对同步执行的Generator函数,for…of遍历即可,因为Generator会返回一个Iterator对象,但是针对异步操作,for…of肯定是不行的。
一)Thunk函数
Thunk函数初的定义其实是用来替换某个表达式,但是在Javascript中Thunk函数的定义则有些不同,Thunk 函数替换的不是表达式,而是多参数函数,将其替换成一个只接受回调函数作为参数的单参数函数。比如这样:
function readFile(filename, callback) { console.log(filename); setTimeout(function () { callback(); }, 1000); } function Thunk(filename) { return function (cb) { return readFile(filename, cb); }; } var readFileThunk = Thunk("filename"); readFileThunk(function () { console.log("ayayay"); });
其实代码理解起来并不复杂,我们写了一个假的readFile方法,接收两个参数,一个filename和一个callback。当我们调用的时候会立即打印filename字段并且一秒后执行callback。然后我们的Thunk函数,其实也很简单,就是通过一个先接收一个filename,然后再返回一个直接收一个cb参数的函数,这个函数内部通过闭包拿到filename并传入readFIle。然后,我们通过Thunk函数率先传入filename生成一个只接受回调函数作为参数的readFileThunk函数。
理论上讲,任何函数,只要有回调函数,就可以写成Thunk函数的形式,那么我们可以提炼出一个通用的Thunk函数转换器:
const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; };
然后,针对上面的代码,我们就可以这样来写:
function readFile(filename, callback) { console.log(filename); setTimeout(function () { callback(); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); readFileThunk("filename")(function () { console.log("ayayay"); });
当然,我们只是小化的实现了通用的Thunk函数,生产环境建议可以使用Thunkify模块。诶?你这Thunk函数是不是Currying?柯里化?嗯~~我觉得是,但是就不再扩展了。如果这样跑题下去,就没边了。
那Thunk函数有啥用呢?前面稍微说过,同步执行的Generator函数可以用for…of遍历,但是异步执行的Generator就需要用到Thunk函数了。我们先来看一段代码:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile);
这段代码跟之前的没有太大的区别,只是稍稍修改了readFile方法把传入的filename传给了callback回调。其他的就一模一样了,那么我们接下来看看,通过Thunk函数处理后,我们如何利用Generator来顺序执行异步:
var gen = function* () { let r1 = yield readFileThunk("path--1"); console.log(r1); let r2 = yield readFileThunk("path--2"); console.log(r2); }; var g = gen(); var r1 = g.next(); r1.value(function (data) { let r2 = g.next(data); r2.value(function (data) { g.next(data); }); });
我们看,首先创建了一个Generator函数gen,然后这个函数内部调用了两次readFileThunk并传入了filename参数,然后打印结果,然后再来一次。重点在下面的代码,首先我们生成遍历器实例后,通过执行g.next(),此时相当于返回了个yield后面的readFileThunk,经过Thunk函数处理,我们只需要传入回调函数就可以了。再详细一点,当我们执行了个next的时候,相当于我们把协程切换到Generator内部,转移执行权。当Generator函数内部执行到yield的的时候,会返回yield后面的内容并把执行权移交给主协程。然后,我们执行r1.value并传入回调函数,再通过调用next,把回调函数的参数传递给next,此时主协程把执行权交给Generator协程,此时拿到的r1结果并打印,然后遇到第二个yield,再执行上面的步骤。
整个代码执行的过程可以这样理解:当执行next的时候,把代码的执行权交给了Generator函数,当执行yield的时候,就把执行权交给了主协程。通过yield和next的参数来实现两个协程的数据传递。后,再通过Thunk函数直接暴露了回调函数,可以让我们在协程外部来执行回调函数,回调函数内部去移交执行权。
到现在为止,我们实现了手动调用,来移交执行权,让整个Generator异步遍历器可以执行下去,但是如果异步很多,我们这样写下去,你看像不像回调地狱?哈哈哈哈~没错,哪怕是Generator,要想确定异步返回了结果再往后执行,本质也是通过回调实现的。
二)基于Thunk函数的自动执行
我们直接上代码吧,这个代码你应该略微比较熟悉:
function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); }
这个run函数,传入的是一个Generator函数。run函数内部则声明了一个next方法,其实这个next就是回调,次执行next实际上就是启动,然后执行gen.next,判断Generator的状态,再执行result.value。就是递归啦~
那么,还是上面的例子,我们就可以这样写,完整的代码如下:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); var gen = function* () { let r1 = yield readFileThunk("path--1"); console.log(r1); let r2 = yield readFileThunk("path--2"); console.log(r2); }; function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } run(gen);
所以你看,其实自动执行也不复杂。咱们之前在第六小节做的秒杀的那个解决方案,实际上就是这个思路。那么这只是我们为了实现本篇文章的目的所做的比较简单的run方法,生产环境其实可以co模块,这个就不多说了。
三)基于Promise的自动执行
上面的解决方案是基于回调函数的,还有一种解决方案是基于Promise的,额,其实就是回调函数的另外一种写法么。我们来看看基于Promise的要怎么写。其实有了前面的基础,写出Promise的例子就很简单了。那么我们先改造下readFile:
function readFile(filename) { return new Promise(function (resolve, reject) { setTimeout(function () { resolve(filename); }, 1000); }); }
嗯~就是callback没了,换成了Promise。简单吧?继续,我们的gen方法没有变化:
var gen = function* () { let r1 = yield readFile("path--1"); console.log(r1); let r2 = yield readFile("path--2"); console.log(r2); };
然后,我们先来看手动执行:
var g = gen(); g.next().value.then(function (data) { g.next(data).value.then(function (data) { g.next(data); }); });
额,我不知道该咋说了,就是回调嵌套,变成了链式调用。
那么,我们再来看看自动执行:
function run(gen) { var g = gen(); function next(data) { var result = g.next(data); if (result.done) return result.value; result.value.then(function (data) { next(data); }); } next(); } run(gen);
也没啥,对吧?重复的话我就不说了~~
四)回归
前面说了那么多,实际上已经解决了本篇的核心问题,但是由于是测试代码,所以我下面附上回归本篇问题的示例:
function readFile(filename, callback) { setTimeout(function () { callback(filename); }, 1000); } const Thunk = function (fn) { return function (...args) { return function (callback) { return fn.call(this, ...args, callback); }; }; }; var readFileThunk = Thunk(readFile); var gen = function* () { for (var i = 0; i < 6; i += 1) { var r = yield readFileThunk(i); console.log(r, new Date()); } }; function run(fn) { var gen = fn(); function next(data) { var result = gen.next(data); if (result.done) return; result.value(next); } next(); } run(gen);
我啥也没改啊,就是改了一下gen函数,你看现在这个gen函数,是不是跟我们写同步代码很像了。至于Promise版本的循环异步打印,嗯~~当作作业了,你自己试下~
但是其实我们做了好多的前置内容才实现了这样的写法,这种写法太烦了,有没有简单点的?有!
八、破坏性解决方案之Async
async,async,我相信大家基本上都用过或者了解过,但是async是啥?嗯~~async就是Generator的语法糖,它的本质就是Generator。那么我们看一段熟悉的代码:
function readFile(filename, callback) { return new Promise((resolve, reject) => { setTimeout(function () { resolve(filename); }, 1000); }); } var gen = async function () { let r1 = await readFile("path--1"); console.log(r1); let r2 = await readFile("path--2"); console.log(r2); }; gen();
打印的时候,我们看控制台,确实是每隔一秒打印了一次。你看,我们十分优雅的解决了开始的问题,至于循环打印,我们可以这样写(嗯,我把函数名改了):
function callConsole(i) { return new Promise((resolve, reject) => { setTimeout(function () { resolve(i); }, 1000); }); } var run = async function () { for (let i = 0; i < 6; i++) { let r = await callConsole(i); console.log(r, new Date()); } }; run();
试试看结果?
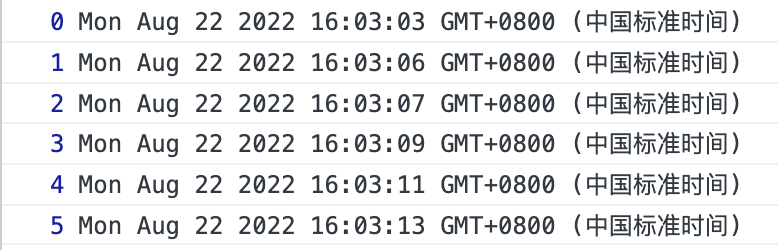
卧槽,完美的解决方案,一目了然的代码形式,异步就像同步那样简洁明了,这就是我们费了这么多功夫找到的完美的解决方案。
但是还没完,因为我们之前大量的铺垫,才能这么快得出结果。但是~没错,还有但是。我们得分析下,async和generator有啥区别呢?我抄一下阮一峰大神的《ECMAScript 6 入门》针对这一点的描述:
- 内置执行器
- 更清晰的语义
- 更广的适用性
- 返回值是Promise
差不多区别就是这几点,首先因为拥有了内置执行器,直观的感受就是代码更简单,不需要我们引入额外的模块或者代码去像执行Generator那样来执行Async函数,并且返回值是Promise,让我们可以用then来进行下一步的操作。
其他关于Async函数的部分,大家有兴趣可以自己查阅,不多说了噢,说多了总是会跑题的~
九、破坏性解决方案总结
我们简单回顾一下,关于破坏性解决方案的部分,我们都经历了哪些过程。
开始,我们通过setTimeout的异步回调,嵌套回调,后形成回调地狱,当上一个异步有了结果之后,再执行下一个,再执行下一个,直到没有回调了就结束了。但是这样的代码实在是有点LowBi,所以我们通过一个简单的递归,让代码更简洁了些,但是本质也还是回调地狱。
然后,我们学习了一个概念,就是促销秒杀,其实促销秒杀的本质无非就是维护一个队列,拿到的事件不会直接让宿主环境执行,而是先放到队列里,挨个执行,等到前一个有结果了,再执行下一个,诶?这话怎么这么熟悉,嗯~~其实根本上来说,也是回调,只不过从递归换成了循环,并且还加入了一点next的概念,以及通过Promise的包裹,在then里执行next,但是和回调没区别。
继续,我们就学了破坏性解决方案复杂的、也是重要的一部分,Generator函数,我们花了很大的篇幅来讲Generator,一步一步的带大家实现了我们终的目标。
后,因为在Generator部分大量的铺垫,引出了本章重要的也是终的完美的解决方案async函数,没错,能像同步那样来写异步代码,终极的解决方案就是async了。但是我还是要强调的是,无论是递归、循环、Promise、还是Generator、Async,本质上来说,都离不开回调,没有回调,你怎么知道我执行完了呢?只不过是书写形式上的变化和一些些原理实现上的不同罢了。
十、其他解决方案之sleep
sleep是什么?翻译过来是睡觉。那我发散下思维,在程序中的sleep,我是不是可以理解为让程序睡了一觉?醒过来再继续执行任务?嗯~~差不多,其实在Javascript中并没有sleep的概念,sleep往往是在Java或者Linux中的概念,完整的概念性解释如下:
Sleep函数可以使计算机程序(进程,任务或线程)进入休眠,使其在一段时间内处于非活动状态。当函数设定的计时器到期,或者接收到信号、程序发生中断都会导致程序继续执行。
那么在Javascript中,可以通过setTimeout定时器来实现sleep。回归到我们本章的主题,既然是用定时器,我是不是可以这样?停一秒,打印,停一秒,再打印,是不是就实现了我们的目的?那我们首先来实现一个基于Javascript的Sleep函数。
一)、基于Date的Sleep实现
种实现方式,其实就是用来计算时间,代码是这样的:
function sleep(time) { var timeStamp = new Date().getTime(); var endTime = timeStamp + time; while (true) { if (new Date().getTime() > endTime) { return; } } }
这块代码很简单,就是通过死循环来占用线程的任务执行,通过计算当前的时间和延迟的时间,得到结束的时间,结束的时间一到,则终止循环,这样就形成了一个Sleep函数,那么我们就可以非常简单的写出循环打印的代码了:
for (var i = 0; i < 6; i++) { sleep(1000); console.log(i, new Date()); }
很简单,并且满足我们的所有要求。但是这种实现直接占用了线程,导致任何代码都无法执行,这种方式只是为了实现而实现,没有任何实际应用的价值。
二)、基于Promise的Sleep实现
Promise的实现也并不复杂:
function sleep(time, i) { return new Promise(function (resolve) { setTimeout(function () { resolve(i); }, time); }); } for (var i = 0; i < 6; i++) { sleep(1000 * i, i).then((i) => { console.log(i, new Date()); }); }
但是这种实现你发现没有,似乎回到了我们开始的部分解决方案的那种方式里,递增描述并且把i作为参数传了进去。这样写,只是实现了Sleep,但是其实并没有实现一种优雅的书写方式解决异步遍历的问题。
三)、基于Async的Sleep实现
这个我不想说啥了,我感觉我不要脸的复制了一下:
function sleep(time) { return new Promise((resolve) => setTimeout(resolve, time)); } async function run() { for (var i = 0; i < 6; i++) { await sleep(1000); console.log(i); } } run();
跟我们破坏性解决方案的Async一模一样,所以真的没啥好说的,而且这里我还略掉了比如Generator的实现,setTimeout的嵌套的实现,因为完全就是在重复我们之前的代码,没有啥多说的价值。
当然,如果我们在Node环境中还可以使用子线程或者Sleep的第三方依赖包来实现,不过这些大家有兴趣可以自己查阅。
十一、其他没解决方案之防抖节流
防抖和节流,相信大家一定很熟悉了,其实无论是防抖的实现还是节流的实现,都是通过setTimeout来作为核心的技术点,聊到setTimeout,咱们首先想到的就是回调嵌套,回调嵌套?额?不好意思~~不好意思~~串台了。
聊到setTimeout,想必大家都很熟悉了,差不多咱们整篇的内容都在聊这个东西,接下来我们就看看怎么通过setTimeout来实现防抖和节流的功能,以及利用防抖和节流实现异步顺序打印的逻辑。
一)基于防抖没实现异步顺序打印
我们要实现防抖,就得先理解什么是防抖:在后一次触发事件后间隔一定的时间再执行回调。什么意思呢,大概就是,在你次触发事件后,会间隔一定的时间后再执行回调,如果在事件触发和执行回调的这段时间内再次触发了事件,则重新计算一定的间隔时间,等到时间到了再去执行回调。如果,偏激一点,你一直在到达执行回调的时间点之前触发事件,理论上讲,回调永远都不会执行,因为一直在重新计算达到时间。换句话说,我们简单一点理解的话,防抖就是在停止触发事件后间隔一定的时间执行回调。
我们来看看简单的防抖的实现:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <input type="text" id="input" /> </body> <script> function debounce(func, delay) { return function (args) { clearTimeout(func.id); func.id = setTimeout(() => { func.call(this, args); }, delay); }; } function jiadeAjax(msg) { console.log("假的ajax:" + msg); } const input = document.getElementById("input"); const debouncedJiadeAjax = debounce(jiadeAjax, 1000); input.addEventListener("keyup", (e) => { debouncedJiadeAjax(e.target.value); }); </script> </html>
这是完整的例子,你可以直接复制下来测试一下。代码我就不解释了,我们来看debounce这个函数,接受两个参数,一个回调函数,一个延迟时间,然后会返回一个函数,这个返回的函数的参数会在setTimeout的回调中传给func函数。当然,开始我们会首先清除之前的计时器。代码很简单,一共就8行。那么,我们怎么利用这个防抖来实现顺序异步打印呢?
二)基于节流没实现异步顺序打印
防抖我们大概了解,那么节流呢?节流要比防抖好理解一些,也就是规定时间内只允许执行一次回调。大概意思呢就是不管你触发了多少次事件,在一定的时间内,每次回调执行的间隔时间是固定的。我们可以类比一下,节流可以理解为河中的大坝,限制水流的流速,让流速满足我们的要求。那么我们来看下怎么实现节流吧:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <input type="text" id="input" /> </body> <script> const throttle = function (func, wait) { let previous = ; return function (args) { let now = +new Date(); if (now - previous >= wait) { func.call(this, args); previous = now; } }; }; function jiadeAjax(msg) { console.log("假的ajax:" + msg, new Date()); } const input = document.getElementById("input"); const throttleJiadeAjax = throttle(jiadeAjax, 1000); input.addEventListener("keyup", (e) => { throttleJiadeAjax(e.target.value); }); </script> </html>
这算是简版的节流的实现,也不过区区十行代码,核心的形式跟防抖是一样的,只不过在节流的实现上,我们要记录开始和当前触发事件的时间,如果现在的时间减去之前的时间大于或等于wait的时间,则执行回调,并重新设置previous,很简单。
十二、其他方案总结
其他解决方案部分,甚至是整个本篇文章,其实都只是在聊一件事,就是回调。嗯~~就一句话。然后,本来想的是防抖和节流也是通过setTimeout实现的,我的理解是只要存在异步理论上讲就可以异步遍历,但是想来想去没想出来基于防抖节流怎么实现异步遍历。算了,不想了~~就当留个笑话~~哈哈哈,次见写博客写到后写不出来了。
十三、文末逼逼
本篇文章,我们经历了部分解决方案,通过变量访问不同存储区域的数据,来获取到对应的信息,部分实现了异步遍历的能力。破坏性解决方案,则是通过使用现代Javascript的各种能力,终通过Generator、Async实现了近乎完美的异步遍历,就像写同步代码一样优雅。后,我们还聊了聊其他解决方案,但是聊着聊着,我们发现其他解决方案也离不开Async、setTimeout、Promise这些Javascript的核心能力,比如实现Sleep,方法很多,但是再写下去其实就是再过一遍破坏性解决方案,没意义。
本来我觉得防抖和节流也是可以实现异步遍历的,并且我可以确定的告诉你,基于防抖、节流的实现逻辑,配合一定的代码修改,是可以实现异步遍历的,但是问题在于,这又回到破坏性解决方案的部分了,所以我写着写着不想写了~~~额~~~不会写了也行,反正就是不写了。
后,其实还有一个点我没说,就是异步遍历器,这个的详细内容,大家可以去链接地址详细阅读学习,我说的肯定不如阮一峰大神说的好(主要是我说不明白)。我简单的介绍下异步遍历器,Generator函数只能返回同步遍历器,如果我们想要在Generator中使用异步,就必须返回一个Thunk函数或者Promise,因为这样会把回调暴露到外层,让我们在回调中操作稍后返回的数据。但是由于这样的写法很不直观,所以ES2018原生的支持了异步遍历器,也就是Symbol.asyncIterator。不管是什么样的对象,只要它的Symbol.asyncIterator属性有值,就表示应该对它进行异步遍历。不过,异步遍历器目前还没有浏览器的实现,只是规范的一个草案。
虽然异步遍历器还没有被实现,但是其实我们完全可以自己动手去写一个异步遍历器,并且其实已经在阮一峰大神的叙述讲解中给出了方案,本章的核心内容已经完美的告一段落,我就不再画蛇添足。
