迈向更全面的复杂文本推理,阅读理解数据集ReClor诞生
 2020-11-10 15:10:09
2020-11-10 15:10:09
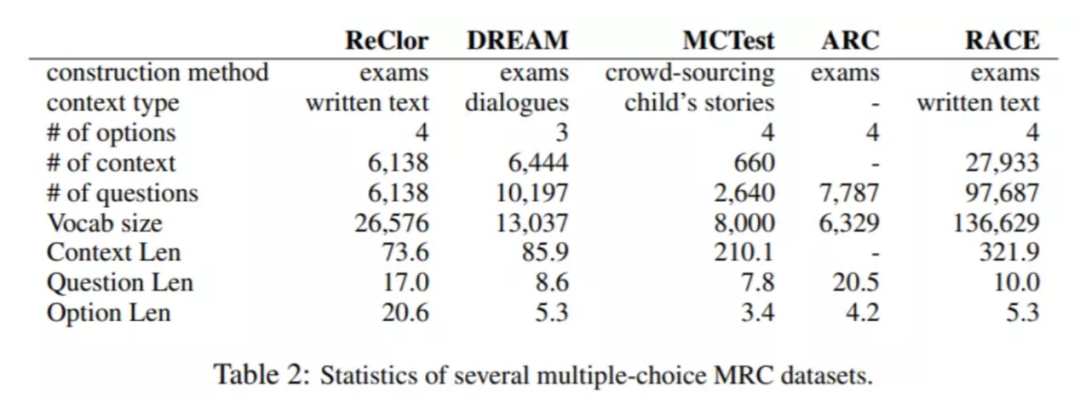
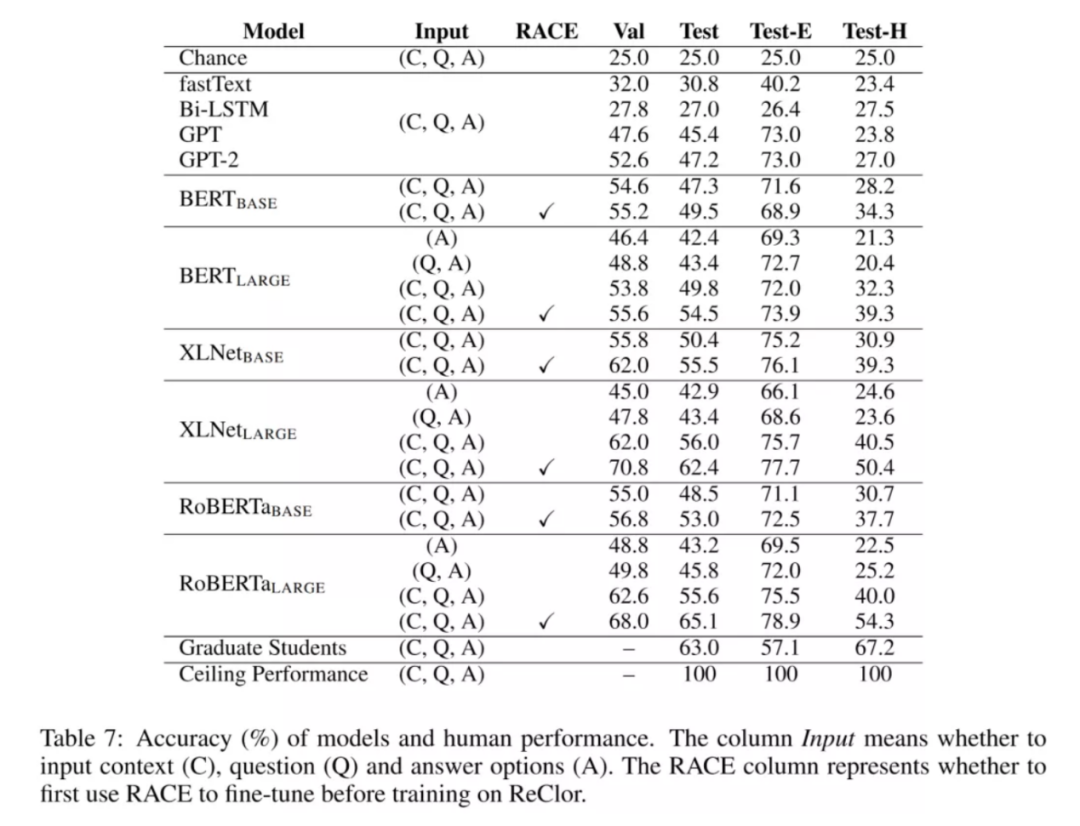
近年来,随着深度学习的出现,机器阅读理解(MRC,Machine Reading Comprehension)已经赢得越来越广泛的关注。它作为 NLP 的核心任务之一,也是评价模型理解文本能力的重要标杆。机器阅读理解的本质可以看作是一种句子关系匹配任务,需要模型根据文本和特定问题来预测答案。近,无监督表示学习的成功、强大的语言预训练模型,如,GPT-2、BERT、XLNet 和 RoBERTa 等,已经在大多数流行的阅读理解数据集上取得了惊人的成绩。或许,是时候引入更具挑战性的数据集来满足先进的模型的需求了。NLP 领域内与逻辑推理任务相关的是自然语言推理(Natural Language Inference),需要模型标记句子对的逻辑关系:继承、中立和矛盾。但是,这个任务只考虑三种简单的逻辑关系,而且推理只限于句子层面。为了推动逻辑推理模型从简单的逻辑关系分类发展到复杂的逻辑推理,从句子级发展到段落级,很有必要引入针对逻辑推理的阅读理解数据集。今年早些时候,新加坡国立大学冯佳时团队在 ICLR 2020 上发表的论文《ReClor: A Reading Comprehension Dataset Requiring Logical Reasoning》就是针对这方面的工作。论文介绍了一个来源于标准化研究生入学考试的、需要逻辑推理的阅读理解数据集 “ReClor”。该工作旨在以更困难的阅读理解任务来挑战当前的前沿模型,推动该领域朝着更全面的复杂文本推理方向迈进。据美国法学院录取委员会(Law School Admission Council)的定义,逻辑推理是一种对普通文本的观点进行检查、分析和批判验证的重要能力。这种能力是人类智力的重要组成部分,在谈判、论辩和写作等方面至关重要。然而,在自然语言理解领域中,据 Sugawara & Aizawa 统计,现有的阅读理解数据集近乎没有或者很少需要体现逻辑推理能力的数据,例如,在 MCTest 数据集中,这类数据占比为 0%,SQuAD 数据集中占比仅为 1.2%。而且早期研究表明,人工注释的数据集通常包含偏差,一些模型常常借助这些偏差来实现高精度,取得很好的效果,但这并非真正意义上理解文本。而 ReClor 之所以能够做到对推理能力有要求,主要原因之一在于,团队从美国研究生管理入学考试、美国法学院入学考试等标准化考试中收集了 6138 道需要逻辑推理的问题。此前的一些与推理相关的数据集,往往是由众包工作者提出推理问题,但具备复杂的逻辑推理能力并不是一蹴而就的,需要长时间的训练,因此众包工作者在设计此类逻辑推理问题时并不能保证整体的质量。好在幸运的是,在一些标准化考试中(如 GMAT 和 LSAT 等),团队惊喜地发现,其中的阅读理解的问题与预期效果是高度吻合的。于是,团队便从美国研究生管理入学考试、美国法学院入学考试等标准化考试中收集了 6138 道需要逻辑推理的问题,这些问题均来自开放的网站和书籍,这样就构成了一个需要逻辑推理的阅读理解数据集(ReClor)。和此前其他的多项选择阅读理解数据集格式类似,ReClor 中每个数据点包含着一段上下文、一个问题和四个答案选项,佳选项只有一个。原始的问题包含五个选项、一个正确选项,不过团队对问题进项了 “改造”:打乱选项顺序,随机删除一个错误选项,保证每个问题包含 1 个正确选项和 3 个错误选项。作者收集到了这些复杂逻辑推理的阅读理解问题,当回答此类问题时,首先需要识别上下文的逻辑关系,然后理解每个选项并择优选择一个正确答案。具体而言,所有问题中,约 91.22% 的问题来自 GMAT 和 LSAT 实际考试,其余则取自高质量的实践考试。所有的数据点划分为训练集、验证集和测试集,分别包含 4683、500 和 1000 个问题。考虑到全面评估 ReClor 上模型的逻辑推理能力,作者建议识别出带偏差的数据点作为 EASY 集,其余归为 HARD 集。统观实验结果,新预训练模型性能显著,可以在 EASY 集上以高精度捕获偏差。然而,在 HARD 集上却举步维艰,性能仅接近或略高于随机猜测的效果。这也就表明,有必要推动更多研究工作从根本上增强当前模型的逻辑推理能力。ReClor 的诞生也受到了更早问世的 RACE 数据集的启发。不过,和 RACE 数据集相比,ReClor 对推理能力的要求更高。表 2,ReClor 数据集与其他类似的阅读理解数据集的对比。图片出处:arXiv上面这个表格展示了 ReClor 数据集与其他类似的阅读理解数据集的对比。如图所示,ReClor 具有相对较大的词汇量(Vocab size)。从上下文的长度(Context Len)上看,ReClor 要 RACE 短得多。但在实际回答问题时,RACE 中的上下文有很多冗余的句子,而在 ReClor 中,上下文段落中的每一句话都很重要,这使得此数据集更专注于评估模型的逻辑推理能力,而不是从较长的上下文中提取相关信息的能力。可以观察到,这些数据集中,ReClor 的答案选项长度(Option Len)大。作者分析并手动标注测试集上问题的类型,并将其分为 17 类,每个问题类型的占比和描述如表 3 所示。论文中作者也展示了在 ReClor 数据集上所有模型的测试性能。为了充分评估模型的逻辑推理能力,团队从测试集中随机抽取 100 个样本,并将它们分成 10 个批次,分别分配给 10 位研究生,然后取其平均分作为基线。对照基线,根据测试集中有偏差的数据点的识别结果分类,能被模型仅通过选项就可以较为稳定预测正确的题目分组为 EASY 集,其余归为 HARD 集,以便于综合评估。接下来将分别通过图 1 和表 7 对实验结果进行分析:图 1 直观表明,当前预训练模型在 EASY 集上的性能整体不错,说明该类模型具有的捕捉数据集偏差的能力;然而,回到 HARD 集上却困难重重,这暗示出,使模型具有真正逻辑推理能力仍是一项需要攻克的难关。而表 7 给出了各个模型和人类在 ReClor 数据集上的准确率对比,很明显,fastText 的性能要比栏的随机猜测的准确率要好,潜在说明在某种程度上,词之间的关联有助于提高性能;而 Bi-LSTM 在数据集上整体表现较低。接下来看一下基于 Transformer 的预训练模型相对来说是否可以取得好的效果呢?答案是肯定的,其性能接近于人类的准确率;然而,从整体上来分析,这些模型在 EASY 集上表现良好,准确率在 75% 左右,说明这些模型具有捕捉数据集偏差的出色能力,但在 HARD 数据集上表现较差,准确率仅为 30% 左右。相比之下,人类在 HARD 集上仍然可以保持良好的表现。另外,表 7 还展示了,先在 RACE 数据集上微调、后在 ReClor 微调的实验结果,模型性能均有大幅提升,尤其是在 HARD 集上。该结果表明,迁移学习或许是增强逻辑推理能力的一种潜在有效的方案。但仍需要注意的是,即使在 RACE 上进行了微调之后,这些强基准在 HARD 集上的佳表现约为 50%,仍然低于人类的佳表现,并且与高表现相差甚远。这些结果表明,要使深度学习模型具备真正的逻辑推理能力,仍然任重道远。
[1]ReClor: A Reading Comprehension Dataset Requiring Logical Reasoning https://arxiv.org/abs/2002.04326[2] 项目主页:http://whyu.me/reclor/