boltdb 是市面上为数不多的纯 go 语言开发的、单机 KV 库。boltdb 基于 Howard Chu'sLMDB 项目 ,实现的比较清爽,去掉单元测试和适配代码,核心代码大概四千多行。简单的 API、简约的实现,也是作者的意图所在。由于作者精力所限,原 boltdb 已经封版,不再更新。若想改进,提交新的 pr,建议去 etcd 维护的 fork 版本 bbolt。
为了方便,本系列导读文章仍以不再变动的原 repo 为基础。该项目麻雀虽小,五脏俱全,仅仅四千多行代码,就实现了一个基于 B+ 树索引、支持一写多读事务的单机 KV 引擎。代码本身简约朴实、注释得当,如果你是 go 语言爱好者、如果对 KV 库感兴趣,那 boltdb 是不可错过的一个 repo。
本系列计划分成三篇文章,依次围绕数据组织、索引设计、事务实现等三个主要方面对 boltdb 源码进行剖析。由于三个方面不是完全正交解耦的,因此叙述时会不可避免的产生交织,读不懂时,暂时略过即可,待有全貌,再回来梳理。本文是篇, boltdb 数据组织。
引子
一个存储引擎底层的构成,就是处理数据在各种物理介质(比如在磁盘上、在内存里)上的组织。而这些数据组织也体现了该存储引擎在设计上的取舍哲学。
在文件系统上,boltdb 采用页(page)的组织方式,将一切数据都对齐到页;在内存中,boltdb 按 B+ 树组织数据,其基本单元是节点(node),一个内存中的树节点对应文件系统上一个或者多个连续的页。boltdb 就在数据组织上就只有这两种核心抽象,可谓设计简洁。当然,这种简洁必然是有代价的,后面文章会进行详细分析。
本文首先对节点和页的关系进行总体说明,然后逐一分析四种页的格式及其载入内存后的表示,后按照 db 的生命周期串一下 db 文件的增长过程以及载入内存的策略。
作者:青藤木鸟 https://www.qtmuniao.com/2020/11/29/bolt->, 转载请注明出处
概述
本文主要涉及到 page.go 和 freelist.go 两个源文件,主要分析了 boltdb 各种 page 在磁盘上的格式和其加载到内存中后的表示。
顶层组织
boltdb 的数据组织,自上而下来说:
- 每个 db 对应一个文件。
2. 在逻辑上:
- 一个 db 包含多个桶(bucket),相当于多个命名空间(namespace),桶可以无限嵌套
- 每个桶对应一棵 B+ 树
3. 在物理上:
- 一个 db 文件是按页为单位进行顺序存储
- 一个页大小和操作系统的页大小保持一致(通常是 4KB)
页和节点
页分为四种类型:
- 元信息页:全局有且仅有两个 meta 页,保存在文件;它们是 boltdb 实现事务的关键
- 空闲列表页:有一种特殊的页,存放空闲页(freelist) id 列表;他们在文件中表现为一段一段的连续的页
- 两种数据页:剩下的页都是数据页,有两种类型,分别对应 B+ 树中的中间节点和叶子节点
页和节点的关系在于:
- 页是 db 文件存储的基本单位,节点是 B+ 树的基本构成节点
- 一个数据节点对应一到多个连续的数据页
- 连续的数据页序列化加载到内存中就成为一个数据节点
总结一下:在文件系统上线性组织的数据页,通过页内指针,在逻辑上组织成了一棵二维的 B+ 树,该树的树根保存在元信息页中,而文件中所有其他没有用到的页的 id 列表,保存在空闲列表页中。
页格式和内存表示
boltdb 中的页分四种类型:元信息页、空闲列表页、中间节点页和叶子节点页。boltdb 使用常量枚举标记:
const (
branchPageFlag = 0x01
leafPageFlag = 0x02
metaPageFlag = 0x04
freelistPageFlag = 0x10
)
每个页都由定长 header 和数据部分组成:

其中 ptr 指向的是页的数据部分,为了避免载入内存和写入文件系统时的序列化和反序列化操作,boltdb 使用了大量的 go unsafe 包中的指针操作。
type pgid uint64
type page struct {
id pgid
flags uint16 // 页类型,值为四种类型之一
count uint16 // 对应的节点包含元素个数,比如说包含的 kv 对
overflow uint32 // 对应节点溢出页的个数,即使用 overflow+1 个页来保存对应节点
ptr uintptr // 指向数据对应的 byte 数组,当 overlay>0 时会跨越多个连续页;不过多个物理也在内存中也只会用一个 page 结构体来表示
}
元信息页(metaPage)
boltdb 中有且仅有两个元信息页,保存在 db 文件的开头(pageid = 0 和 1)。但是在元信息页中,ptr 指向的内容并非元素列表,而是整个 db 的元信息的各个字段。
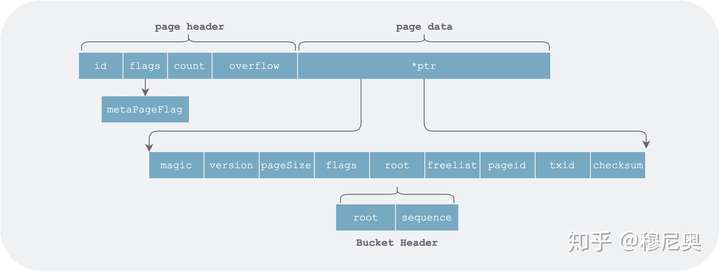
元信息页加载到内存后数据结构如下:
type meta struct {
magic uint32
version uint32
pageSize uint32 // 该 db 页大小,通过 syscall.Getpagesize() 获取,通常为 4k
flags uint32 //
root bucket // 各个子 bucket 根所组成的树
freelist pgid // 空闲列表所存储的起始页 id
pgid pgid // 当前用到的大 page id,也即用到 page 的数量
txid txid // 事务版本号,用以实现事务相关
checksum uint64 // 校验和,用于校验 meta 页是否写完整
}
空闲列表页(freelistPage)
空闲列表页是 db 文件中一组连续的页(一个或者多个),用于保存在 db 使用过程中由于修改操作而释放的页的 id 列表。
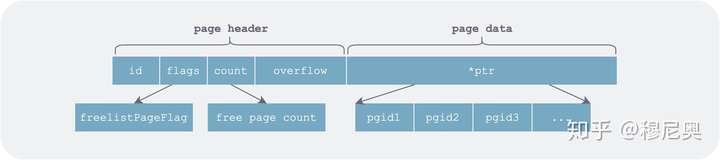
在内存中表示时分为两部分,一部分是可以分配的空闲页列表 ids,另一部分是按事务 id 分别记录了在对应事务期间新增的空闲页列表。
// 表示当前已经释放的 page 列表
// 和写事务刚释放的 page
type freelist struct {
ids []pgid // all free and available free page ids.
pending map[txid][]pgid // mapping of soon-to-be free page ids by tx.
cache map[pgid]bool // fast lookup of all free and pending page ids.
}
其中 pending 部分需要单独记录主要是为了做 MVCC 的事务:
- 写事务回滚时,对应事务待释放的空闲页列表要从
pending项中删除。 - 某个写事务(比如 txid=7)已经提交,但可能仍有一些读事务(如 txid <=7)仍然在使用其刚释放的页,因此不能立即用作分配。
这部分内容会在 boltdb 事务中详细说明,这里只需有个印象即可。
空闲列表转化为 page
freelist 通过 write 函数,在事务提交时将自己写入给定的页,进行持久化。在写入时,会将 pending 和 ids 合并后写入,这是因为:
write函数是在写事务提交时调用,写事务是串行的,因此pending中对应的写事务都已经提交。- 写入文件是为了应对崩溃后重启,而重启时没有任何读操作,自然不用担心有读事务还在用刚释放的页。
func (f *freelist) write(p *page) error {
// 设置页类型
p.flags |= freelistPageFlag
// page.count 是 uint16 类型,其能表示的范围为 [0, 64k-1] 。如果空闲页 id 列表长度超出了此范围,就需要另想办法。
// 这里用了个 trick,将 page.count 置为 64k 即 0xFFF,然后在数据部分的个元素存实际数量(以 pgid 为类型,即 uint64)。
lenids := f.count()
if lenids == {
p.count = uint16(lenids)
} else if lenids < 0xFFFF {
p.count = uint16(lenids)
// copyall 会将 pending 和 ids 合并并排序
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[:])
} else {
p.count = 0xFFFF
((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[] = pgid(lenids)
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[1:])
}
return nil
}
注意本步骤只是将 freelist 转化为内存中的页结构,需要额外的操作,比如 tx.write() 才会将对应的页真正持久化到文件。
空闲列表从 page 中加载
在数据库重启时,会首先从前两个元信息页恢复出一个合法的元信息。然后根据元信息中的 freelist 字段,找到存储 freelist 页的起始地址,进而将其恢复到内存中。
func (f *freelist) read(p *page) {
// count == 0xFFFF 表明实际 count 存储在 ptr 所指向的内容的个元素
idx, count := , int(p.count)
if count == 0xFFFF {
idx = 1
count = int(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[])
}
// 将空闲列表从 page 拷贝内存中 freelist 结构体中
if count == {
f.ids = nil
} else {
ids := ((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[idx:count]
f.ids = make([]pgid, len(ids))
copy(f.ids, ids)
// 保证 ids 是有序的
sort.Sort(pgids(f.ids))
}
// 重新构建 freelist.cache 这个 map.
f.reindex()
}
空闲列表分配
作者原版的空闲列表分配异常简单,分配单位是页,分配策略是适应:即从排好序的空闲页列表 ids 中,找到段等于指定长度的连续空闲页,然后返回起始页 id。
// 如果可以找到连续 n 个空闲页,则返回起始页 id
// 否则返回 0
func (f *freelist) allocate(n int) pgid {
if len(f.ids) == {
return
}
// 遍历寻找连续空闲页,并判断是否等于 n
var initial, previd pgid
for i, id := range f.ids {
if id <= 1 {
panic(fmt.Sprintf("invalid page allocation: %d", id))
}
// 如果不连续,则重置 initial
if previd == || id-previd != 1 {
initial = id
}
if (id-initial)+1 == pgid(n) {
// 当正好分配到 ids 中前 n 个 page 时,仅简单往前调整 f.ids 切片即可。
// 尽管一时会造成空间浪费,但是在对 f.ids append/free 操作时,会按需
// 重新空间分配,重新分配会导致这些浪费空间被回收掉
if (i + 1) == n {
f.ids = f.ids[i+1:]
} else {
copy(f.ids[i-n+1:], f.ids[i+1:])
f.ids = f.ids[:len(f.ids)-n]
}
// 从 cache 中删除对应 page id
for i := pgid(); i < pgid(n); i++ {
delete(f.cache, initial+i)
}
return initial
}
previd = id
}
return
}
这个 GC 策略相当简单直接,是线性的时间复杂度。阿里似乎做过一个 patch,将所有空闲 page 按其连续长度 group by 了一下。
叶子节点页(leafPage)
这种页对应 B+ 树中叶子节点,其存储的元素可以是普通 kv 数据、该 bucket 的 subbucket。
对于前者来说,页中存储的基本元素为某个 bucket 中一条用户数据。对于后者来说,页中的一个元素为该 db 中的某个 subbucket 。
// page ptr 指向的字节数组中的单个元素
type leafPageElement struct {
flags uint32 // 普通 kv (flags=0)还是 subbucket(flags=bucketLeafFlag)
pos uint16 // kv header 与对应 kv 的距离
ksize uint32 // key 的字节数
vsize uint32 // val 字节数
}
其详细结构如下:
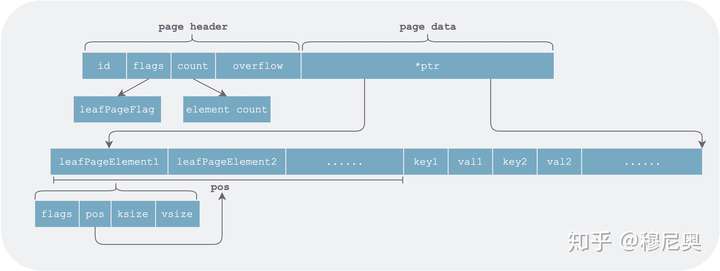
可以看出,leaf page 在组织数据时,将元素头(leafPageElement)和元素本身(key value)分开存储。这样的好处在于 leafPageElement 是定长的,可以按下标访问对应元素。在二分查找指定 key 时,只需按需加载相应页到内存(访问 page 时是通过 mmap 进行的,因此只有访问时才会真正将数据从文件系统中加载到内存)即可。
inodes := p.leafPageElements()
index := sort.Search(int(p.count), func(i int) bool {
return bytes.Compare(inodes[i].key(), key) != -1
})
如果元素头和对应元素紧邻存储,则需将 leafPageElement 数组对应的所有页顺序读取,全部加载到内存,才能进行二分。
另外一个小优化是 pos 存储的是元素头的起始地址到元素的起始地址的相对偏移量,而非以 ptr指针为起始地址的偏移量。这样可以用尽量少的位数(pos 是 uint16) 表示尽量长的距离。
func (n *branchPageElement) key() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n)) // buf 是元素头起始地址
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize]
}
中间节点页(branchPage)
中间节点页和叶子节点页的结构大体相同。不同之处在于,页中保存的数据的 value 是 page id,即该中间节点在哪些 key 上的分支分别指向的 page 。
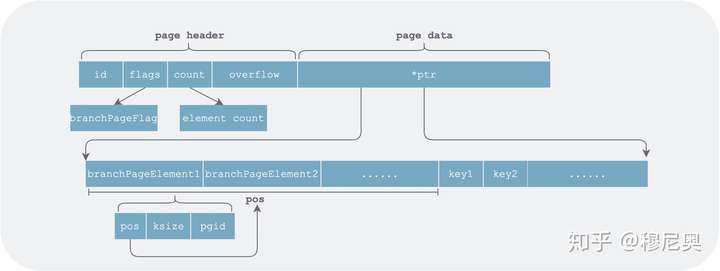
branchPageElement 中的 key 存的是其指向的页中的起始 key。
转换流程
boltdb 使用 mmap 将 db 文件映射到内存空间。在构建树并且访问过程中,按需将对应的页加载到内存里,并且利用操作系统的页缓存策略进行替换。
文件增长
当我们打开一个 db 时,如果发现该 db 文件为空,会在内存中初始化四个页(4*4k=16K),分别是两个元信息页、一个空的空闲列表页和一个空的叶子节点页,然后将其写入 db 文件,然后走正常打开流程。
func (db *DB) init() error {
// 设置页大小与操作系统一致
db.pageSize = os.Getpagesize()
buf := make([]byte, db.pageSize*4)
// 在 buffer 中创建两个元信息页.
for i := ; i < 2; i++ {
p := db.pageInBuffer(buf[:], pgid(i))
p.id = pgid(i)
p.flags = metaPageFlag
// 初始化元信息页.
m := p.meta()
m.magic = magic
m.version = version
m.pageSize = uint32(db.pageSize)
m.freelist = 2
m.root = bucket{root: 3}
m.pgid = 4
m.txid = txid(i)
m.checksum = m.sum64()
}
// 在 pgid=2 的页写入一个空的空闲列表.
p := db.pageInBuffer(buf[:], pgid(2))
p.id = pgid(2)
p.flags = freelistPageFlag
p.count =
// 在 pgid=3 的页写入一个空的叶子元素.
p = db.pageInBuffer(buf[:], pgid(3))
p.id = pgid(3)
p.flags = leafPageFlag
p.count =
// 将 buffer 中的这四个页写入数据文件并刷盘
if _, err := db.ops.writeAt(buf, ); err != nil {
return err
}
if err := fdatasync(db); err != nil {
return err
}
return nil
}
随着数据的不断写入,需要申请新的页。boltdb 首先会去 freelist 中找有无可重复利用的页,如果没有,就只能进行 re-mmap(先 mumap 在 mmap),扩大 db 文件。每次扩大会进行倍增(因此从 16K * 2 = 32K 开始),到达 1G 后,再次扩大会每次新增 1G。
func (db *DB) mmapSize(size int) (int, error) {
// 从 32KB 开始,直到 1GB.
for i := uint(15); i <= 30; i++ {
if size <= 1<<i {
return 1 << i, nil
}
}
// Verify the requested size is not above the maximum allowed.
if size > maxMapSize {
return , fmt.Errorf("mmap too large")
}
// 对齐到 maxMmapStep = 1G
sz := int64(size)
if remainder := sz % int64(maxMmapStep); remainder > {
sz += int64(maxMmapStep) - remainder
}
// 对齐到 db.pageSize
pageSize := int64(db.pageSize)
if (sz % pageSize) != {
sz = ((sz / pageSize) + 1) * pageSize
}
// 不能超过 maxMapSize
if sz > maxMapSize {
sz = maxMapSize
}
return int(sz), nil
}
在 32位 机器上文件大不能超过 maxMapSize = 2G;在 64 位机器上,文件上限为 256T。
读写流程
在打开一个已经存在的 db 时,会首先将 db 文件映射到内存空间,然后解析元信息页,后加载空闲列表。
在 db 进行读取时,会按需将访问路径上的 page 加载到内存,并转换为 node,进行缓存。
在 db 进行修改时,使用 COW 原则,所有修改不在原地,而是在改动前先复制一份。如果叶子节点 node 需要修改,则 root bucket 到该 node 路径上所涉及的所有节点都需要修改。这些节点都需要新申请空间,然后持久化,这些和事务的实现息息相关,之后会在本系列事务文章中做详细说明。
小结
boltdb 在数据组织方面只使用了两个概念:页(page) 和节点 (node)。每个数据库对应一个文件,每个文件中包含一系列线性组织的页。页的大小固定,依其性质不同,分为四种类型:元信息页、空闲列表页、叶子节点页、中间节点页。打开数据库时,会渐次进行以下操作:
- 利用 mmap 将数据库文件映射到内存空间。
- 解析元信息页,获取空闲列表页 id 和 root bucket 页 id。
- 依据空闲列表页 id ,将所有空闲页列表载入内存。
- 依据 root bucket 起始页地址,解析 root bucket 根节点。
- 根据读写需求,从树根开始遍历,按需将访问路径上的数据页(中间节点页和叶子节点页)载入内存成为节点(node)。
可以看出,节点分两种类型:中间节点(branch node)和叶子节点(leaf node)。
另外需要注意的是,bucket 可以进行无限嵌套,导致这一块稍微有点不好理解。在下一篇 boltdb 的索引设计中,将详细剖析 boltdb 是如何组织多个 bucket 以及单个 bucket 内的 B+ 树索引的。
参考
- github,boltdb repo
- 我叫尤加利,boltdb 源码分析
