转自:

在谈论数据库架构和数据库优化的时候,会常听到“分库分表”、“分片”、“Sharding”…等关键词。值的高兴的是,这部分公司的业务量应该正在实现(或者即将面临)高速增长,或技术方面也面临着一些挑战。但让人担忧的部分是,他们的系统“分库分表”真的有选择正确吗?
随着业务规模的不断扩大,用户需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。关于数据库的扩展主要包括:业务拆分、主从复制、数据库分库与分表等,本篇文章的灵感就来源自作者与朋友关于数据库分库分表问题的讨论。
DRDS vs TiDB
起源
DRDS
- 数据库中间件Cobar、MyCat、Amoeba
Tidb
- Google Spanner/F1
架构
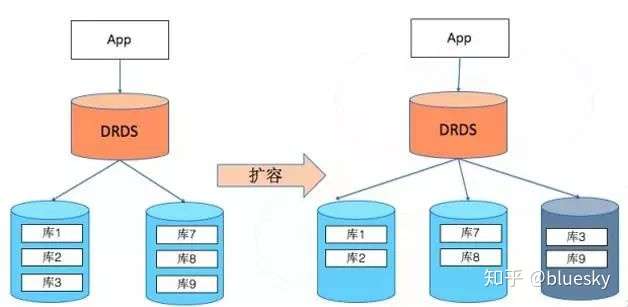
DRDS架构
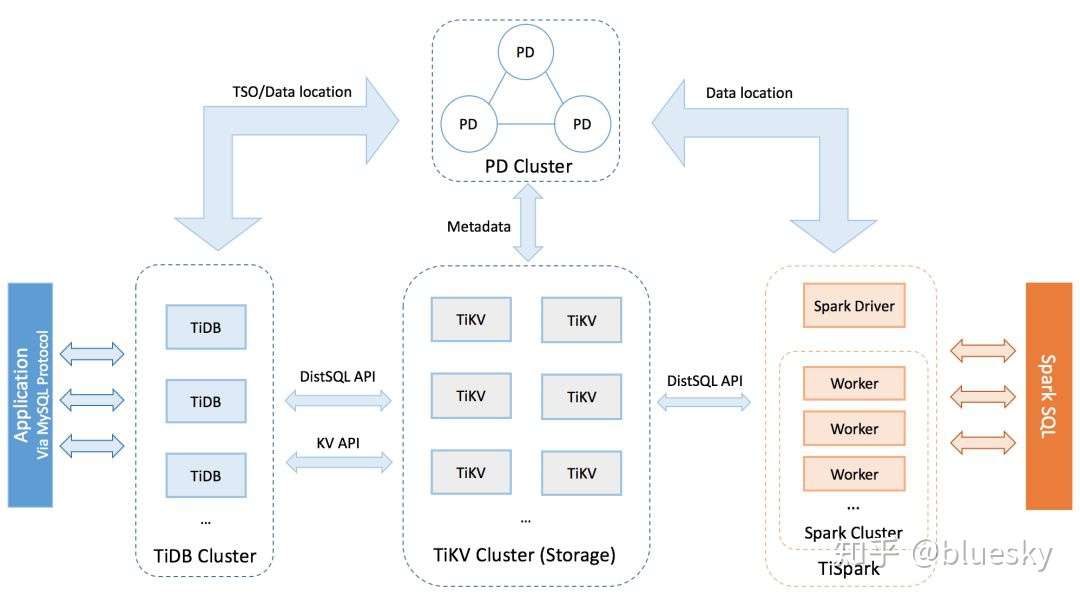
TiDB架构
分片机制
DRDS
- 支持HASH、RANGE_HASH、MMDD等多种分片类型
- 原理上都是基于HASH分片
- 需要在建表时指点分片Key以及分片方式
- 不支持全局索引
TiDb
- 通过multi-raft协议,将数据Region(按范围分区)分布于不同节点,分片不需要应用干预
- 由于按照范围对数据进行分片,在某些范围数据被集中访问时易造成热点问题,业务上可以通过对主键进行散列编码打散数据或者热点数据通过cache方式解决该问题
应用限制
DRDS
- Sharding 后对应用和 SQL 的侵入都很大,需要 SQL 足够简单,这种简单的应用导致 DB 弱化为存储。
- SQL 不能跨维度 join、聚合、子查询等。
- 每个分片只能实现 Local index,不能实现诸如键、外键等全局约束。
TiDB
- 不支持外键
- 自增主键保证但不保证连续
支持的事务模型
DRDS
- DRDS本质上是DB Proxy,事务基本上是指Proxy层的事务,原则上并不涉及RDS数据库级别的事务
- FREE:允许多写;不保证原子性;无性能损耗;数据批量导入、表初始化等场景
- 2PC:两阶段提交事务;保证原子性,不保证可见性;推荐 MySQL 5.6 用户使用
- XA:XA强一致事务;保证原子性;保证可见性;推荐 MySQL 5.7 及更高版本用户使用
- FLEXIBLE:柔性事务;补偿型事务;适用于性能要求较高、高并发的业务场景
TiDB
- TiDB参考Percolator 事务模型,事务下沉到TiKV(存储引擎)
- 通过2PC(Prewrite阶段和Commit阶段)提交以及乐观锁保证分布系统中的ACID
- TiDB提供的事务隔离级别(Snapshot Isolation)与MySQL提供的事务隔离级别保持一致
高可用保障
DRDS
- 通过下游RDS主备方案保证数据高可用
- 数据冗余两副本以上,基本上从节点不参与计算只进行数据备份,资源上比较浪费
- 跨机房多地部署实施困难,需要借助同步工具或业务上实现数据双写
TiDB
- tidb的元数据存储在pd中,通过pd调度数据分片
- 分片低三副本,通过multi-raft调度
- 通过节点标签影响pd调度,实现两地三中心部署
从架构来讲TiDB的原生三副本机制要优于DRDS通过异步数据同步实现高可用的机制。异步同步主要的缺点是切换周期长,存在数据丢失的风险。对于DRDS当业务系统使用XA或者GTS这种强一致性协议时,某节点宕机会导致服务整体不可用
扩缩容再平衡机制
横向扩索容主要考虑数据再平衡的效率和对在线业务系统的影响问题。考虑到DRDS分库分表采用哈希切分,那么在数据再平衡时需要针对分片key将所有数据进行重新分片,造成网络及系统开销较大;TiDB采用Range分片机制,当节点数发生变化,根据pd调度,只对部分Region进行迁移,系统开销理论上小的多.
运维成本
DRDS
- 由于DRDS多由云厂商开发,本质上是一种服务,不存在运维成本,只有沟通成本
- 由于Proxy层技术不透明,数据又基于RDS,系统性能优化需要与厂商沟通解决
TiDB
- 社区提供了ansible为基础的安装运维包,可以说单纯运维门槛不高,基于prometheus和grafana提供比较完善的监控系统
- 性能优化一部分靠生态提供的工具,pd-ctl、tidb-ctl等。另一方面靠社区的相应
- 源码透明,可以深入了解其实现
应用场景
DRDS
- 顺时高峰且易形成数据热点的场景
DRDS的分片机制为hash分片,天然将数据打散到各个节点,借助RDS本身的缓存机制可以很好的缓解数据热点。比如企业的考勤系统或银行的柜员系统,在早上上班高峰并发量多,几分钟到一个小时的时间内员工会集中打卡或者登录单例数据库会瞬间达到性能瓶颈。
TiDB
- 多租户SaaS应用:
该场景多为多租户场景,SAAS供应商为每一个用户提供单独的库,每个数据库的数据量不均衡。如果使用MySQL单实例挂载多库的方式只能纵向扩展;多实例多库方式要么在应用层为每个应用程序配置不同的数据库URL,要么实现业务数据Router;采用TiDB可以统一管理数据资源,将多个实例转化为一个集群维护,同时借助TiDB的数据分片机制避免单一用户形成实例热点。 - 微服务架构统一管理数据资源:
微服务架构的一个原则是数据可拆分,但如果每个微服务使用MySQL主备方式维护一组MySQL实例不仅不便于管理,而且由于每个服务对数据库资源使用的不均衡及易造成资源浪费。应用TiDB集群不仅可以很好的解决上述问题,而且便于维护,同时就业务来讲比较容易形成数据服务中间层。
备份机制
DRDS
依赖于RDS本身的备份机制
TiDB
- Tidb遵循MySQL协议,全量情况下可以通过MyDumper等逻辑备份工具备份数据
- 增量数据可以通过社区提供的TiDB-Binlog实时生成增量备份文件
应用改造成本
DRDS
- 分片键的选择,实际开发中通常会存在说干业务依赖于同一张表的情况,通过某一个列作为分片条件提高某项业务性能时可能隐性降低某些业务的性能。
- 分片算法的选,DRDS的拆分算法很多,择简单取模、数值向右移、双拆分列哈希等等,需要开发者先弄清楚这些概念再根据业务情况进行选择
- 拆分后的表不支持全局约束,如果由于业务需求必须维护全局只能通过建立中间表的方式维护性,增加开发成本和数据库调用次数
- 拆分后的表部分SQL要根据DRDS的扩展语法重写
TiDB
- TiDB的SQL实质上是MySQL语法的一个完全子集,如果业务没有用到MySQL的内建函数和外键约束的话基本可以平滑迁移,只需要对部分SQL根据TiDB架构特性进行优化
- 如果重度应用MySQL的系统存在某些TiDB不支持的函数,那么这部分功能需要应用端实现
总体上来讲,DRDS的应用改造成本主要集中在业务数据拆分上,以及由于数据拆分带来的业务应用重构;Tidb由于自身架构原生支持分片所以不存在数据拆分问题,应用重用主要由于对MySQL的私有内建函数依赖重。
个人观点总结
DRDS起源于DB中间件,通过hash算法做数据分片用于扩展单机数据库的不足,属于过度产品,扩展时数据再平衡的时间会随着数据及节点数量的增加而增加。从应用改造后续维护的角度来讲,性价比不高。从场景上来讲DRDS的hash分片机制可以更好的散列数据,更加不易形成数据热点;TiDB在频发访问的数据量小于64M时易形成热点,当数据的范围大于64M的时候几乎可以数据会被分配到其他节点热点也随之消除。从应用架构来考虑,这个量级的热数据完全可以通过缓存解决。TiDB从架构来讲是一个很优雅的数据库系统,社区及公司历史不长但发展很快,在实际使用过程中会遇到一些坑,这些坑一部分是由于产品成长过程中的bug或者待优化feature造成,另一部分是由于单机环境和分布式环境的差异造成的。勇于尝试新事物,也许未来收益会更大。
