数据库的存储方式可以分为行式(row-oriented)和列式(column-oriented)。列式意味着列中的所有值都存储在一起。这与行式存储的相反,后者将一行的所有值存储在一起。哪种存储方式更好取决于您的应用程序的访问方式。一般来说,行式数据库擅长随机读操作不适合用于大数据,像SQL Server、Oracle、mySQL等属于行式数据库范畴。列式数据库从一开始就是面向大数据环境下数据仓库的数据分析而产生的。
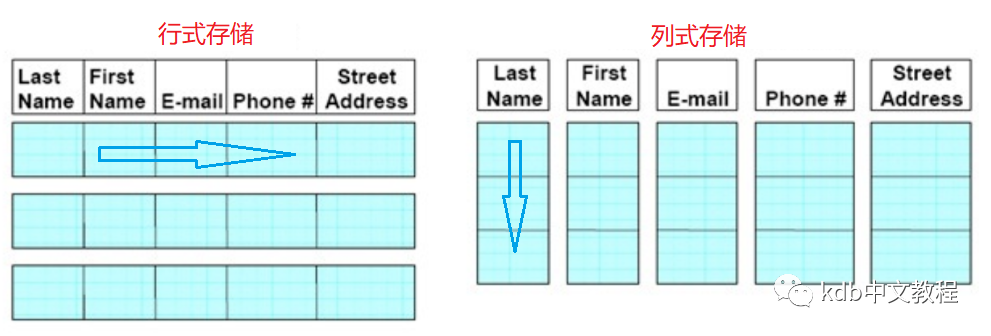
使用列式存储方式,许多操作会更高效。特别是,需要访问指定列的一系列值的操作要快得多。如果列中的所有值都具有相同的大小,那么情况会更好。这种访问模式是使用kdb+应用程序的典型代表。
为便于理解,我们看一列64位浮点数:
q).Q.w[] `used696768q)t: ([] f: 1000000 ? 1.0)q).Q.w[] `used9085488
可以看出,保存一百万个8字节float型数值所需的内存仅略超过8MB。那是因为数据是按顺序存储在数组中的。为进一步确认,我们创建另一个表:
q)u: update g: 1000000 ? 5.0 from tq).Q.w[] `used17474272
t和u共享f列,内存只增加了8MB多。如果kdb+是行式存储的,则内存使用量将再增加8MB。
接下来我们看看将表写入磁盘时会发生什么:
q)`:d:/t set t`:d:/tq)hcount `:d:/t8000025
25字节的开销。显然,所有数值都按顺序存储在磁盘上。效率是要避免不必要的工作,在这里我们看到kdb+确实完成了读取和写入列时需要做的事情——不多也不少。因此这种方法节省空间。那么,这种数据存储方式如何转化为速度?如果我们要求kdb+对所有100万个数值求和,那么将整个数组以列式组织相对于行式组织来说是一个巨大的优势,具体原因涉及到高速缓存命中和页面错误等技术问题,就不展开了。
参考:https://www.jianshu.com/p/ad2533e5cfaa,
https://kdbfaq.com/what-exactly-does-column-oriented-mean
