浅析数据库多表连接:ZNBase的分布式join计算
 2022-03-30 10:09:21
2022-03-30 10:09:21
Join 是 SQL 中的常用操作。在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时我们就可以使用 SQL 语句中的连接(join),在两个或多个数据表中查询数据。常用 Join 算法
常用的多表连接算法主要有三类,分别是 Nested-Loop Join、Hash Join 和 Sort Merge Join。Nested-Loop Join
Simple Nested-Loop Join 是简单粗暴的 Join 算法 ,即通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有 1 万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。在 Simple Nested-Loop Join 算法的基础上,延申出了 Index Nested-Loop Join 和 block Nested-Loop Join。前者通过减少内层表数据的匹配次数优化查询效率;后者则是通过一次性缓存外层表的多条数据,以此来减少内层表的扫表次数,从而达到提升性能的目的。 Batched Key Access Join (BKA Join) 可以看作是一个性能优化版的 Index Nested-Loop Join。之所以称为 Batched,是因为它的实现使用了存储引擎提供的 MRR(Multi-Range Read) 接口批量进行索引查询,并通过 PK 排序的方法,将随机索引回表转化为顺序回表,一定程度上加速了查索引的磁盘 IO。Hash Join
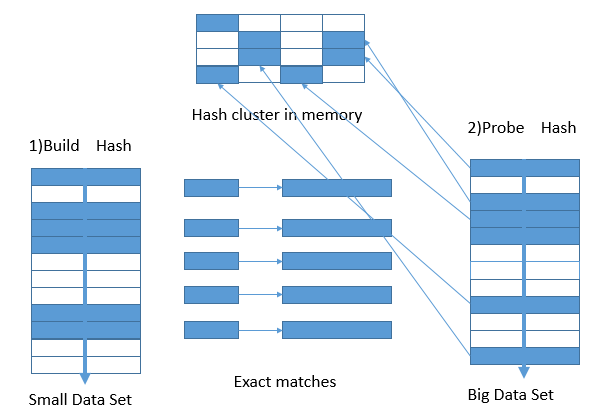
两个表若是元组数目过多,逐个遍历开销就很大,Hash Join(哈希连接)是一种提高连接效率的方法。哈希连接主要分为两个阶段:建立阶段(build phase)和探测阶段(probe phase)。在建立阶段,首先选择一个表(一般情况下是较小的那个表,以减少建立哈希表的时间和空间),对其中每个元组上的连接属性(join attribute)采用哈希函数得到哈希值,从而建立一个哈希表。在探测阶段,对另一个表,扫描它的每一行并计算连接属性的哈希值,与 bulid phase 建立的哈希表对比,若有落在同一个 bucket 的,如果满足连接谓词(predicate)则连接成新的表。在内存足够大的情况下,建立哈希表的整个过程都在内存中完成,完成连接操作后才放到磁盘里。因此这个过程也会带来很多的内存消耗。Merge Join
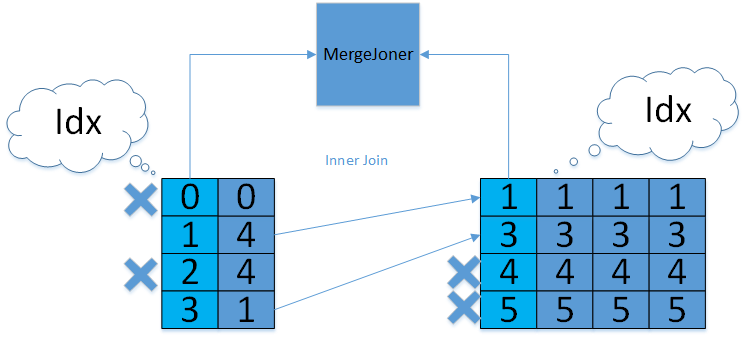
Merge join 个步骤是确保两个关联表都是按照关联的字段进行排序。如果关联字段有可用的索引,并且排序一致,则可以直接进行 merge join 操作;否则需要先对关联的表按照关联字段进行一次排序(就是说在 merge join 前的两个输入上,可能都需要执行一个排序操作,再进行 merge join)。 两个表都按照关联字段排序好之后,merge join 操作从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。Merge join 操作本身是非常快的,但是 merge join 前进行的排序可能会带来较大的性能损耗。ZNBase 采用的分布式 join 算子
ZNBase 是由浪潮开源的一款分布式 NewSQL 数据库,其采用的 Join 算法包括 Merge join、Hash join 和 Lookup join 。Merge join
在两个表索引排序相同的情况下,Merge joins 比 Hash joins 在计算和内存方面更高效,性能更好。Merge joins 要求在相等列上索引两个表,并且索引必须具有相同的顺序。如果不满足这些条件,ZNBase 才会转向较慢的 Hash joins。Merge joins 在两个表的索引列上执行,如下所示:ZNBase 检查相等列上的索引,并且它们的排序方式相同(即 ASC 或 DESC)。
ZNBase 从每个表中取一行并进行比较。
HashJoin
如果无法使用一个 Merge join,ZNBase 将使用一个 Hash join。Hash joins 的计算量很大,需要额外的内存。ZNBase 读取两个表并尝试选择较小的表。
ZNBase 在较小的表上创建内存中的哈希表。如果哈希表太大,它将溢出到磁盘存储(这可能会影响性能)。
然后,ZNBase 扫描大表,查找哈希表中的每一行。
Lookup Join
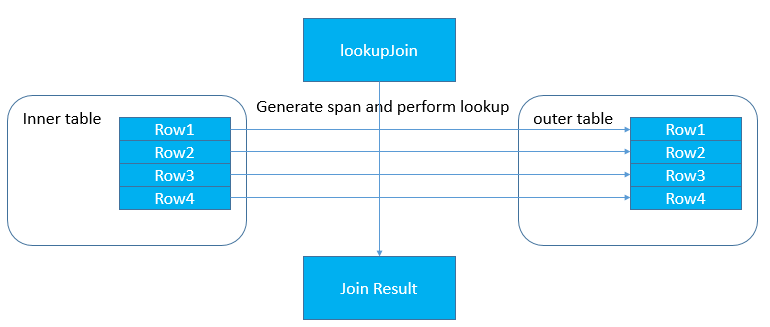
对于普通的 join 算法,我们注意到,没有必要对于 Outer 表中每行数据,都对 Inner 表进行一次全表扫操作,很多时候可以通过索引减少数据读取的代价,这就用到了 Lookup join。Lookup join 的适配前提是,在 join 的两个表中,Outer 表上的对应索引列存在索引。在执行过程中,首先读取小表的数据,然后去大表的索引中找到大概的 scan 范围,拿大表的数据与小表的数据比较,推进大表后就可以得出结果。其执行过程简述如下:从 Inner 表中取一批数据;
通过 join key 以及这一批数据构造在 outer 表的取值范围,只读取对应范围内的数据
对从 inner 表取出的每一行数据,都与 2 中取出的对应范围内的每一条数据执行 join 操作并输出结果交给上层处理
重复步骤 1.2.3 直到遍历完 Outer 表为止。
Lookup Join 在执行时会不断变更状态,在不同阶段进入不同的状态做 join 处理:这个阶段读取小表的一块块数据,并对每一行数据开始构建对于大表的 index scan 的范围(命名为 span),构建完成后进入下一个阶段。当小表的这一块数据被读完后会回到这个状态继续读取,重复直到小表被读完。阶段二:jrPerformingLookup 阶段这个阶段通过阶段一得到的 span,将这个 span 中的数据取出放在一个容器中,让小表读出的一块数据每一行去这个容器中的每一行数据做 lookup 查找,执行 join 操作并将结果存储在容器中。当数据匹配完成后进入下一阶段。从阶段二中的容器中取出 join 结果输出到上层。分布式 join 计算和数据重分布
与传统数据库相比,分布式数据库的架构有很大的不同。以 ZNBase 为例,数据库架构可以分为 SQL 层和存储层,SQL 层的计算节点需要计算数据所在的分片,然后从多个存储节点拉取所需的数据。目前 ZNBase 采用两种办法实现分布式计算时表的关联:重分布
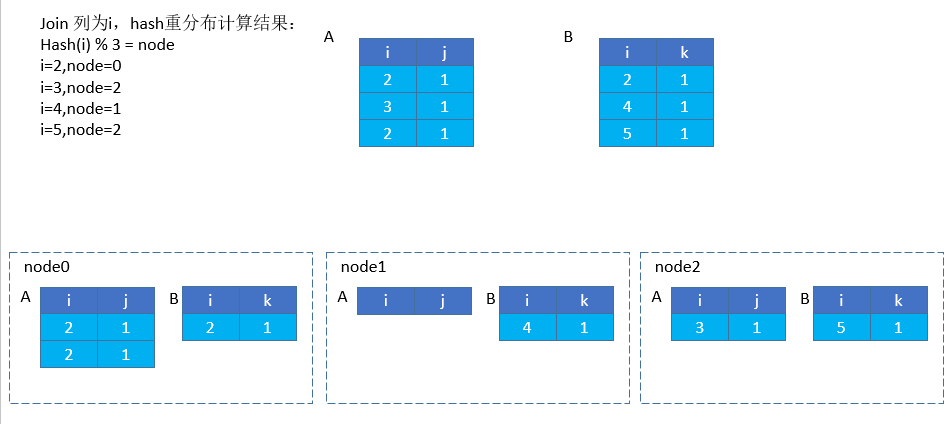
将两表按 join 的列,按 hash 特征重新分布到每个节点上。执行分布式的 join 时,如果各个执行节点的数据没有按照 join 列的特征进行分布,这个时候就会将数据进行 hash 重分布,具体操作如下:1)选取一个 hash 函数对该行数据进行 join 列的 hash 值计算根据取余结果将特定行数据分发至对应计算节点进行 join 计算。广播
M + N <= min(M,N) * L:重分布。M 和 N 分别为左右表的行数,L 为参与计算的节点个数。本文介绍了常用的多表连接 Join 算法,以及分布式数据库 ZNBase 采用的 Join 算法和分布式 Join 策略。对相关技术或产品有任何问题欢迎提 issue 或在社区中留言讨论。同时欢迎广大对分布式数据库感兴趣的开发者共同参与 ZNBase 项目的建设。