
在分布式环境下,如何对某对象做标识是个很常规的问题。本文讨论几种常见做法,供大家参考。
UUID是可以生成时间、空间上都独一无二的值,其本质是随机+规则组合而成的。即使在两个独立的服务器上生成UUID,其预期值也是不同的。以MySQL为例,说明下UUID。
❖ 格式

在MySQL中,UUID值是一个128位的数字,表示为以下格式的十六进制数字的utf8字符串:aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee。其得到的随机值由5个部分组成,且分隔符位为:中划线。其各部分含义如下:
前三组值是时间戳换算过来的;
第四组值是暂时性保持时间戳的性。例如,使用夏令时;
第五组值是一个IEE 802的节点标识值,它是空间上的。若后者不可用,则用一个随机数字替换。假如主机没有网卡,或者我们不知道如何在某系统下获得机器地址,则空间性就不能得到保证,即使这样出现重复值的几率还是非常小的。
在MySQL环境中多次调用或执行得到的后两组值相同,若把mysqld服务器关闭,重新启动之后,会发现第四组的组与未重启前的值发生变化,然后一直不变化,只要重新启动mysqld服务就会发生变化。另外,对于同一台机器,第五组值始终不会发生变化。
❖ 优点
使用UUID作为主键具有以下优点:
UUID值在表,数据库甚至在服务器上都是的,允许您从不同数据库合并行或跨服务器分发数据库。
UUID值不会公开有关数据的信息,因此在URL中使用更安全。
可以在避免往返数据库服务器的任何地方生成UUID值。它也简化了应用程序中的逻辑。
❖ 缺点
除了优势之外,UUID值也存在一些缺点:
存储UUID值(16字节)比整数(4字节)或甚至大整数(8字节)占用更多的存储空间。
调试似乎更加困难,想象一下WHERE id ='9d6212cf-72fc-11e7-bdf0-f0def1e6646c'和WHERE id = 10哪个舒服一点?
使用UUID值可能会导致性能问题,因为它们的大小和没有被排序。
❖ 数据库案例:MySQL
在MySQL中,就内置了对UUID的支持。在使用上需注意若干问题。
-
作为主键问题
UUID()函数产生的值,并不适合作为InnoDB引擎表的主键。因为格式无序,作为索引组织表存储会带来管理上的不小开销。
-
格式问题
在MySQL中,可以使用UUID()来生成主键,但是用MySQL的UUID()函数 ,生成的UUID是36位的,其中包含32个字符以及4个分隔符(-),往往这个分隔符对我们来说是没有用的,可以使用MySQL自带的REPLACE函数去掉分隔符。
-
内置函数支持
在MySQL中,可以以紧凑格式(BINARY)存储UUID值,并通过以下功能显示人机可读格式(VARCHAR):UUID_TO_BIN、BIN_TO_UUID、IS_UUID。需要注意,UUID_TO_BIN(),BIN_TO_UUID()和IS_UUID()函数仅在MySQL 8.0或更高版本中可用。
- UUID_TO_BIN()函数将UUID从人类可读格式(VARCHAR)转换成用于存储的紧凑格式(BINARY)格式
- BIN_TO_UUID()函数将UUID从紧凑格式(BINARY)转换为人类可读格式(VARCHAR)
- IS_UUID()函数则可用来判断参数是有效的字符串格式
UUID。
UUID 是软件开发中常用的通用标识符之一。然而,在过去的几年里,其他的竞品挑战了它的存在。其中,NanoID 是 UUID 的主要竞争对手之一。但是,这两者之间的主要区别很简单。它归结为键所使用的字母表。由于 NanoID 使用比 UUID 更大的字母表,因此较短的 ID 可以用于与较长的 UUID 相同的目的。

❖ 优点
-
更小
NanoID 只有 108 个字节那么大。与 UUID 不同,NanoID 的大小要小 4.5 倍,并且没有任何依赖关系。此外,大小限制已用于将大小从另外 35% 减小。大小减少直接影响数据的大小。例如,使用 NanoID 的对象小而紧凑,能够用于数据传输和存储。随着应用程序的增长,这些数字变得明显起来。
-
更安全
在大多数随机生成器中,它们使用不安全的 Math.random()。但是,NanoID 使用 crypto module 和 Web Crypto API,意味着 NanoID 更安全。此外,NanoID 在 ID 生成器的实现过程中使用了自己的算法,称为 统一算法,而不是使用“随机 % 字母表” random % alphabet。
-
更快
NanoID既快速又紧凑,NanoID 比 UUID 快 60%。与 UUID 字母表中的 36 个字符不同,NanoID 只有 21 个字符。
-
更多语言
NanoID 支持 14 种不同的编程语言,它们分别是:C#、C++、Clojure 和 ClojureScript、Crystal、Dart & Flutter、Deno、Go、Elixir、Haskell、Janet、Java、Nim、Perl、PHP、带字典的 Python、Ruby、Rust、Swift。
-
更好兼容性
它还支持 PouchDB、CouchDB WebWorkers、Rollup 以及 React 和 Reach-Native 等库。我们可以使用 npx nanoid 在终端中获得 ID。在 JavaScript 中使用 NanoID 的要求是要先安装 NodeJS。
-
自定义字母
NanoID 的另一个现有功能是它允许开发人员使用自定义字母表。我们可以更改文字或 id 的大小。在下面的示例中,我将自定义字母表定义为 ABCDEF1234567890,并将 Id 的大小定义为 12。
import { customAlphabet } from 'nanoid';
const nanoid = customAlphabet('ABCDEF1234567890', 12);
model.id = nanoid();
-
没有第三方依赖
由于 NanoID 不依赖任何第三方依赖,随着时间的推移,它能够变得更加稳定自治。从长远来看,这有利于优化包的大小,并使其不太容易出现依赖项带来的问题。
❖ 数据库案例-ShardingSphere
原生数据库产品,大多没有支持NanoID,但可通过外部方式引用进来。例如在开源项目 Apache ShardingSphere 中可通过规则的配置,在其分片表中使用 NanoID作为主键生成器。参考如下配置
CREATE SHARDING TABLE RULE t_order(
RESOURCES(ds_3307,ds_3308),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=4)),
KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME=NanoID,PROPERTIES("worker-id"=123)))
);
CREATE TABLE t_order (
order_id varchar(50) NOT NULL,
user_id int NOT NULL,
status varchar(50) DEFAULT NULL,
PRIMARY KEY (order_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
分布式系统中ID生成方案,比较简单的是UUID(Universally Unique Identifier,通用识别码),但是其存在两个明显的弊端:一、UUID是128位的,长度过长;二、UUID是完全随机的,无法生成递增有序的UUID。而现在流行的基于 Snowflake 雪花算法的ID生成方案就可以很好地解决了UUID存在的这两个问题。
❖ 原理
Snowflake 雪花算法,由Twitter提出并开源,可在分布式环境下用于生成ID的算法。该算法生成的是一个64位的ID。在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如 MySQL 的 Innodb 存储引擎的主键。
❖ 格式
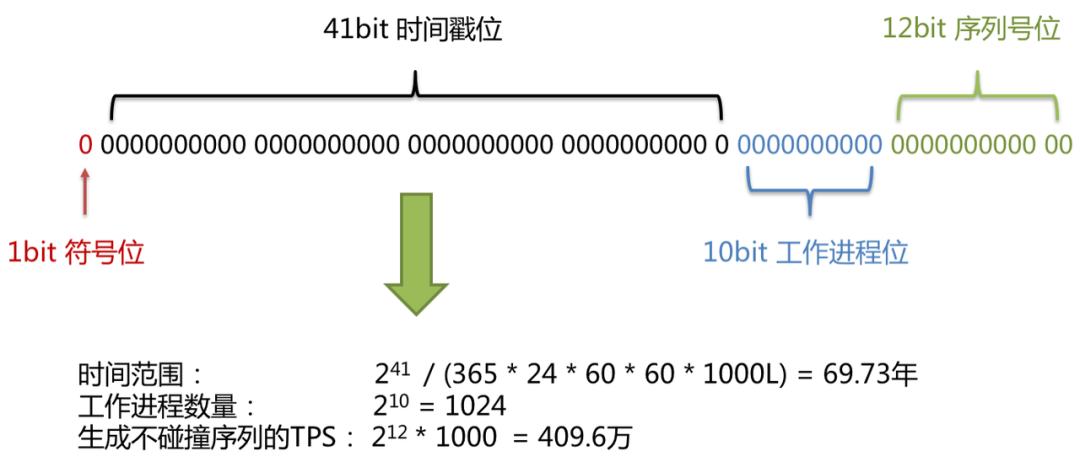
使用雪花算法生成的主键,二进制表示形式包含 4 部分,从高位到低位分表为:1bit 符号位、41bit 时间戳位、10bit 工作进程位以及 12bit 序列号位。
-
符号位(1bit)
预留的符号位,恒为零。
-
时间戳位(41bit)
41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); 结果约等于 69.73 年。Apache ShardingSphere 的雪花算法的时间纪元从 2016 年 11 月 1 日零点开 始,可以使用到 2086 年,相信能满足绝大部分系统的要求。
-
工作进程位(10bit)
该标志在 Java 进程内是的,如果是分布式应用部署应保证每个工作进程的 id 是不同的。该值默认为0,可通过属性设置。
-
序列号位(12bit)
该序列是用来在同一个毫秒内生成不同的 ID。如果在这个毫秒内生成的数量超过 4096 (2 的 12 次幂),那么生成器会等待到下个毫秒继续生成。
❖ 优点
使用SnowFlake的优点是其空间占用更小,且具备一定有序性,这对于类似MySQL数据库是比较友好的。
❖ 缺点
因为其生成策略需参考当前时间,当服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个大容忍的时钟回拨毫秒数。如果时钟回拨的时间超过大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到后一次主键生成的时间后再继续工作。大容忍的时钟回拨毫秒数的默认值为 0,可通过属性设置。
❖ 数据库案例-ShardingSphere
原生数据库产品,大多没有支持SnowFlake,但可通过外部方式引用进来。例如在开源项目 Apache ShardingSphere 中可通过规则的配置,在其分片表中使用 SnowFlake作为主键生成器。参考如下配置
CREATE SHARDING TABLE RULE t_order(
RESOURCES(ds_3307,ds_3308),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=4)),
KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME= Snowflake,PROPERTIES("worker-id"=123)))
);
CREATE TABLE t_order (
order_id varchar(50) NOT NULL,
user_id int NOT NULL,
status varchar(50) DEFAULT NULL,
PRIMARY KEY (order_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
