Greenplum数据库基于PostgreSQL开源技术。它本质上是几个PostgreSQL数据库实例,它们共同作为一个有凝聚力的数据库管理系统(DBMS)。它基于PostgreSQL 8.2.15,在大多数情况下与PostgreSQL在SQL支持,功能,配置选项和终用户功能方面非常相似。数据库用户与Greenplum数据库进行交互,就像常规的PostgreSQL DBMS一样。
PostgreSQL的内部结构已经过修改或补充,以支持Greenplum数据库的并行结构。例如,系统目录,优化程序,查询执行程序和事务管理器组件已经过修改和增强,可以在所有并行PostgreSQL数据库实例中同时执行查询。Greenplum互连(网络层)支持不同的PostgreSQL实例之间的通信,并允许系统表现为一个逻辑数据库。
Greenplum数据库还包括旨在优化PostgreSQL以实现商业智能(BI)工作负载的功能。例如,Greenplum添加了并行数据加载(外部表),资源管理,查询优化和存储增强功能,这些功能在标准PostgreSQL中找不到。
一、Greenplum数据库简介
Greenplum(以下简称GPDB)是一款开源数据仓库。基于开源的PostgreSQL改造,主要用来处理大规模数据分析任务,相比Hadoop,Greenplum更适合做大数据的存储、计算和分析引擎。
GPDB是典型的Master/Slave架构,在Greenplum集群中,存在一个Master节点和多个Segment节点,其中每个节点上可以运行多个数据库。
1、特性
1)完善的标准支持:GPDB完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;从应用编程接口上讲,它支持ODBC和JDBC。
2)支持分布式事务,支持ACID。保证数据的强一致性。
3)做为分布式数据库,拥有良好的线性扩展能力。在国内外用户生产环境中,具有上百个物理节点的GPDB集群都有很多案例。
4)GPDB是企业级数据库产品,全球有上千个集群在不同客户的生产环境运行。这些集群为全球很多大的金融、政府、物流、零售等公司的关键业务提供服务。
5)GPDB是Greenplum(现在的Pivotal)公司十多年研发投入的结果。GPDB基于PostgreSQL 8.2,PostgreSQL 8.2有大约80万行源代码,而GPDB现在有130万行源码。相比PostgreSQL 8.2,增加了约50万行的源代码。
6)Greenplum有很多合作伙伴,GPDB有完善的生态系统,可以与很多企业级产品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多种开源软件集成,譬如Pentaho,Talend 等。
2、Greenplum的几个关键词
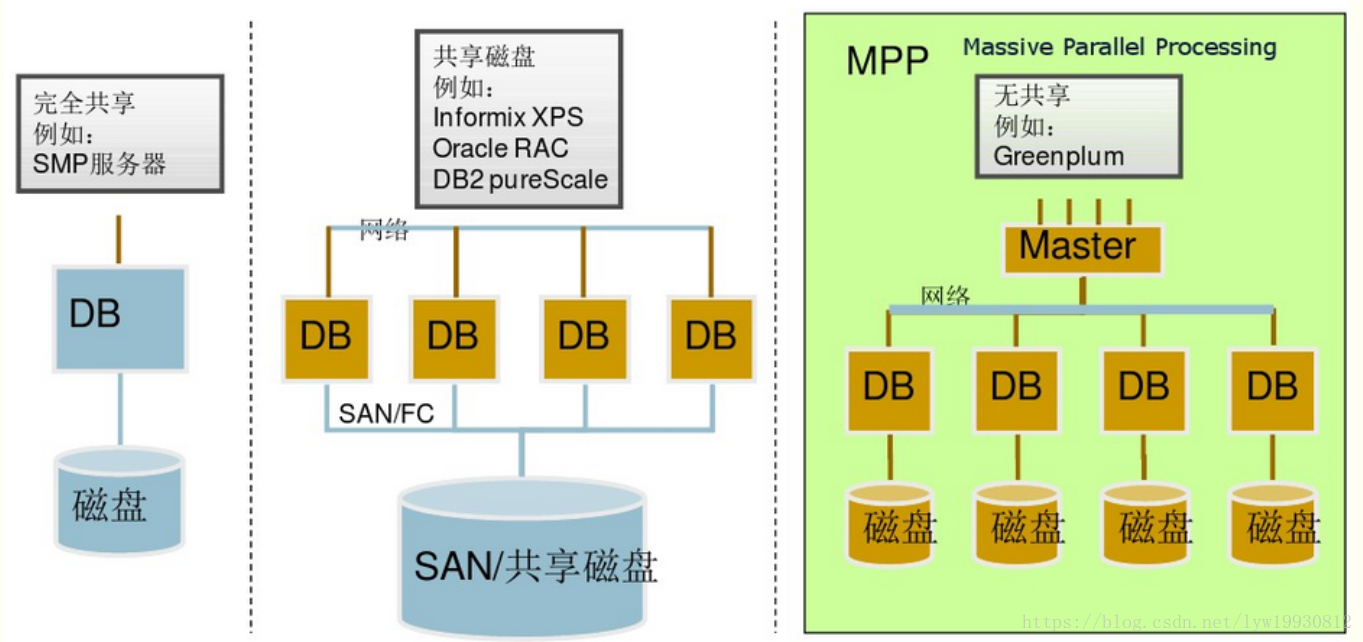
Shared Nothing:各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。Share-Nothing架构在扩展性和成本上都具有明显优势。
MPP:大规模并行处理系统是由许多松耦合处理单元组成的,借助MPP这种高性能的系统架构,Greenplum可以将TB级的数据仓库负载分解,并使用所有的系统资源并行处理单个查询。
MVCC:与事务型数据库系统通过锁机制来控制并发访问的机制不同, GPDB使用多版本控制(Multiversion Concurrency Control/MVCC)保证数据一致性。 这意味着在查询数据库时,每个事务看到的只是数据的快照,其确保当前的事务不会看到其他事务在相同记录上的修改。据此为数据库的每个事务提供事务隔离。
MVCC以避免给数据库事务显式锁定的方式,大化减少锁争用以确保多用户环境下的性能。在并发控制方面,使用MVCC而不是使用锁机制的大优势是, MVCC对查询(读)的锁与写的锁不存在冲突,并且读与写之间从不互相阻塞。
二、Greenplum架构
1、整体架构

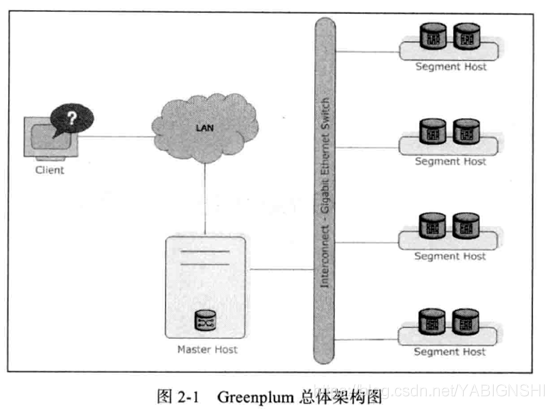
数据库由Master Severs和Segment Severs通过Interconnect互联组成。
Master主机负责:建立与客户端的连接和管理;SQL的解析并形成执行计划;执行计划向Segment的分发收集Segment的执行结果;Master不存储业务数据,只存储数据字典。
Segment主机负责:业务数据的存储和存取;用户查询SQL的执行。
1)Greenplum Master
Master只存储系统元数据,业务数据全部分布在Segments上。其作为整个数据库系统的入口,负责建立与客户端的连接,SQL的解析并形成执行计划,分发任务给Segment实例,并且收集Segment的执行结果。正因为Master不负责计算,所以Master不会成为系统的瓶颈。
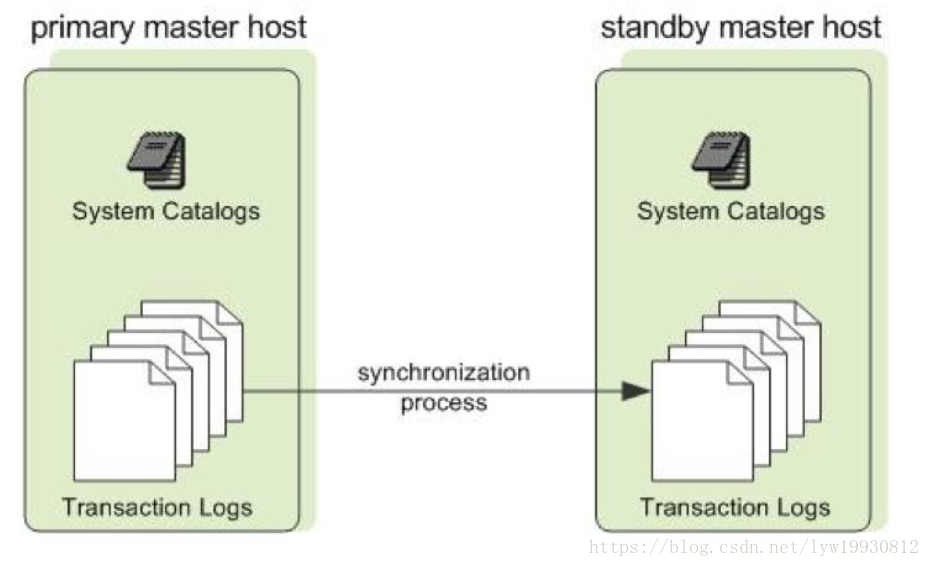
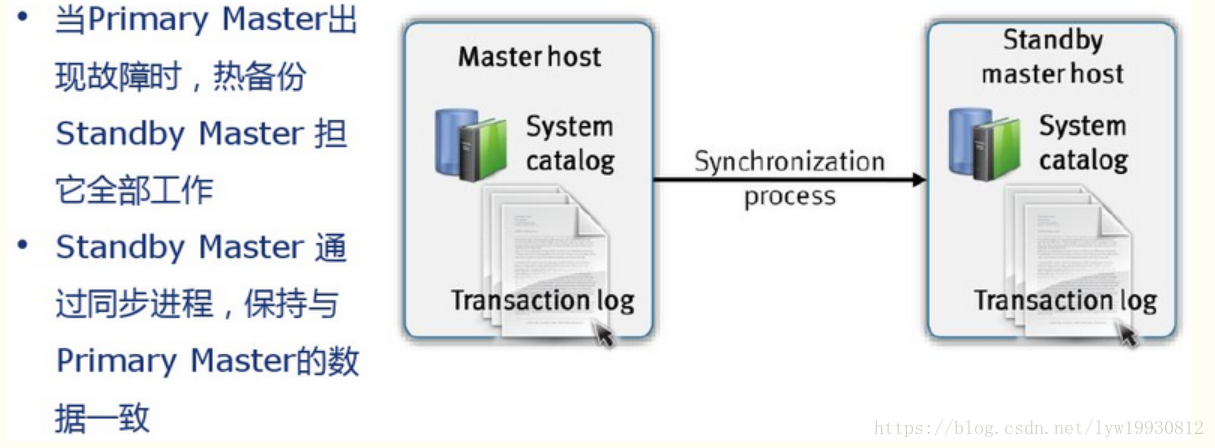
Master节点的高可用,类似于Hadoop的NameNode HA,如上图,Standby Master通过synchronization process,保持与Primary Master的catalog和事务日志一致,当Primary Master出现故障时,Standby Master承担Master的全部工作。
2)Greenplum Segment
Greenplum中可以存在多个Segment,Segment主要负责业务数据的存储和存取,用户查询SQL的执行,每个Segment存放一部分用户数据,但是用户不能直接访问Segment,所有对Segment的访问都必须经过Master。进行数据访问时,所有的Segment先并行处理与自己有关的数据,如果需要关联处理其他Segment上的数据,Segment可以通过Interconnect进行数据的传输。Segment节点越多,数据就会打的越散,处理速度就越快。因此与Share All数据库集群不同,通过增加Segment节点服务器的数量,Greenplum的性能会成线性增长。
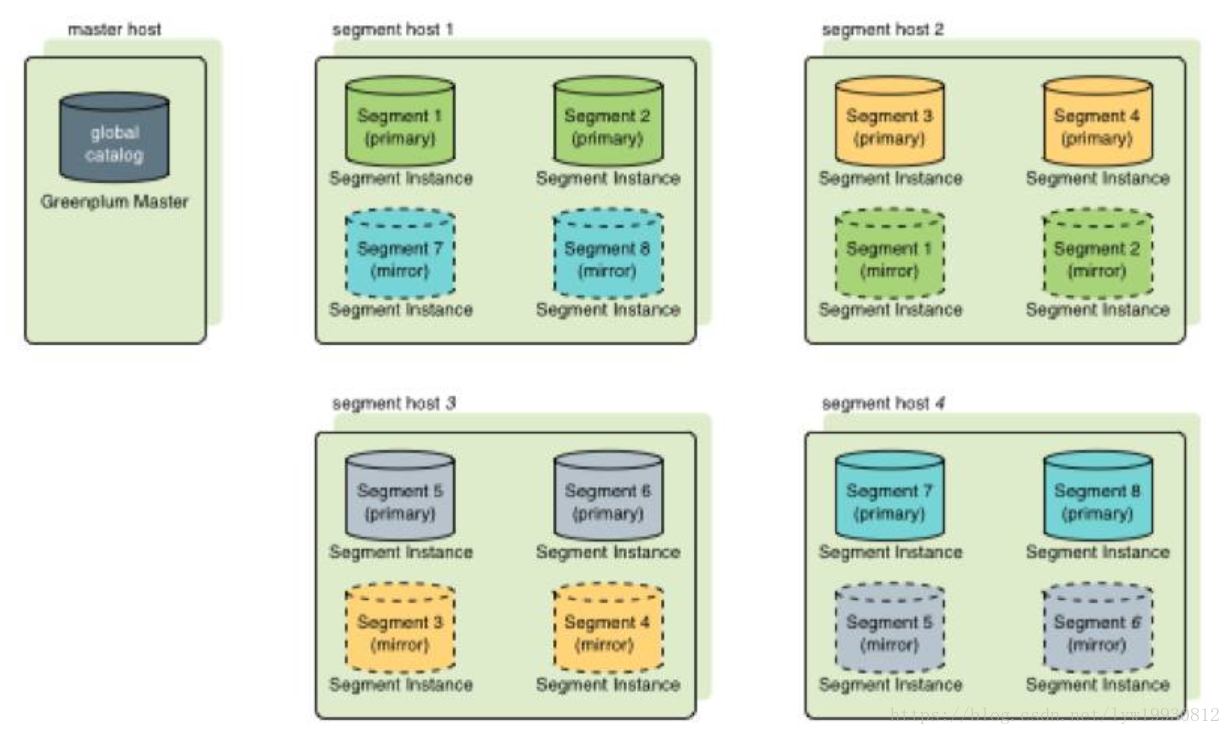
每个Segment的数据冗余存放在另一个Segment上,数据实时同步,当Primary Segment失效时,Mirror Segment将自动提供服务,当Primary Segment恢复正常后,可以很方便的使用gprecoverseg -F工具来同步数据。
3)Interconnect
Interconnect是Greenplum架构中的网络层,是GPDB系统的主要组件,默认情况下,使用UDP协议,但是Greenplum会对数据包进行校验,因此可靠性等同于TCP,但是性能上会更好。在使用TCP协议的情况下,Segment的实例不能超过1000,但是使用UDP则没有这个限制。
2、mpp架构图
3、基本体系架构
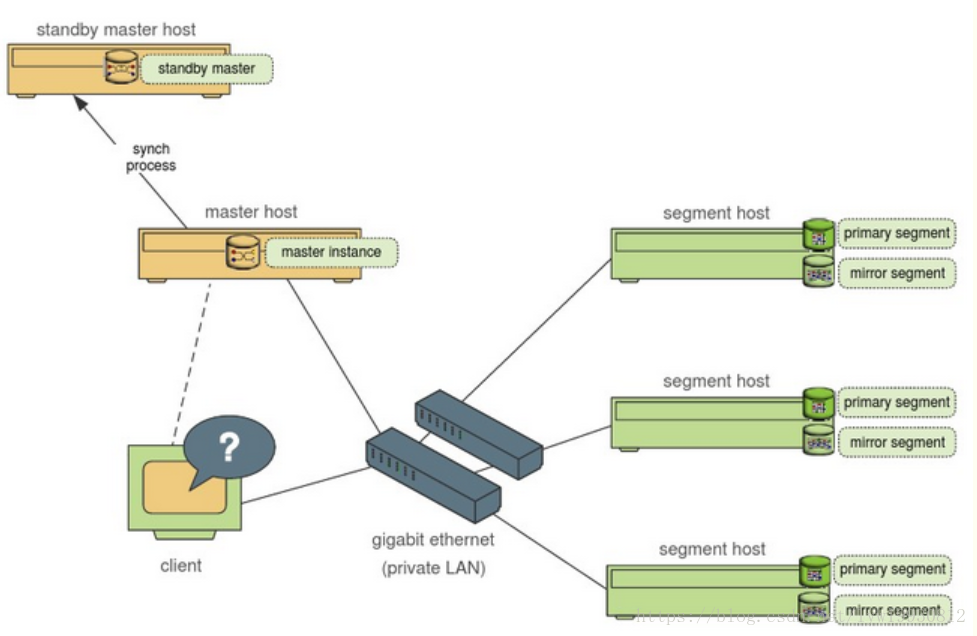
master作用:访问系统的入口,处理所有用户连接,生成查询计划,协调工作处理过程,管理工具,系统目录表和元数据(数据字典),不存放任何用户数据。
master node高可用:
segments作用:每个segment存放一部分用户数据,一个系统可以有多哥segment,用户不能直接存取访问,所有对segment的访问都必须经过master,数据库监听进程(postgres)监听来自master的链接。
4、并行查询计划和执行
下图为一个简单SQL语句,从两张表中找到2008年的销售数据。图中右边是这个SQL的查询计划。从生成的查询计划树中看到有三种不同的颜色,颜色相同表示做同一件事情,我们称之为分片/切片(Slice)。下层的橙色切片中有一个重分发节点,这个节点将本节点的数据重新分发到其他节点上。中间绿色切片表示分布式数据关联(HashJoin)。上面切片负责将各个数据节点收到的数据进行汇总。
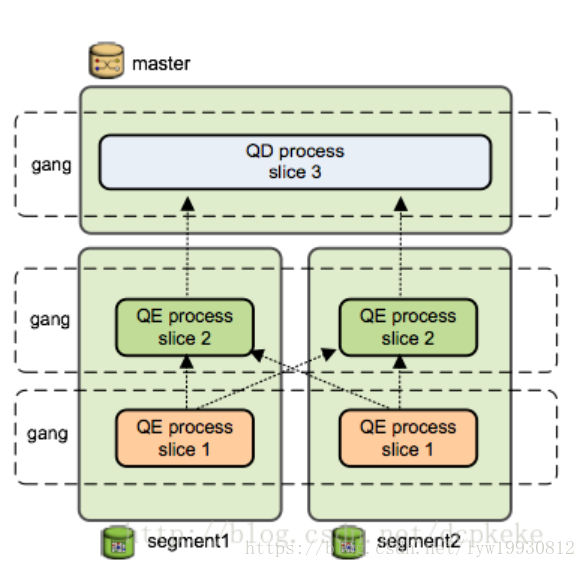
然后看看这个查询计划的执行。主节点(Master)上的调度器(QD)会下发查询任务到每个数据节点,数据节点收到任务后(查询计划树),创建工作进程(QE)执行任务。如果需要跨节点数据交换(例如上面的HashJoin),则数据节点上会创建多个工作进程协调执行任务。不同节点上执行同一任务(查询计划中的切片)的进程组成一个团伙(Gang)。数据从下往上流动,终Master返回给客户端。
三、Greenplum分布存储
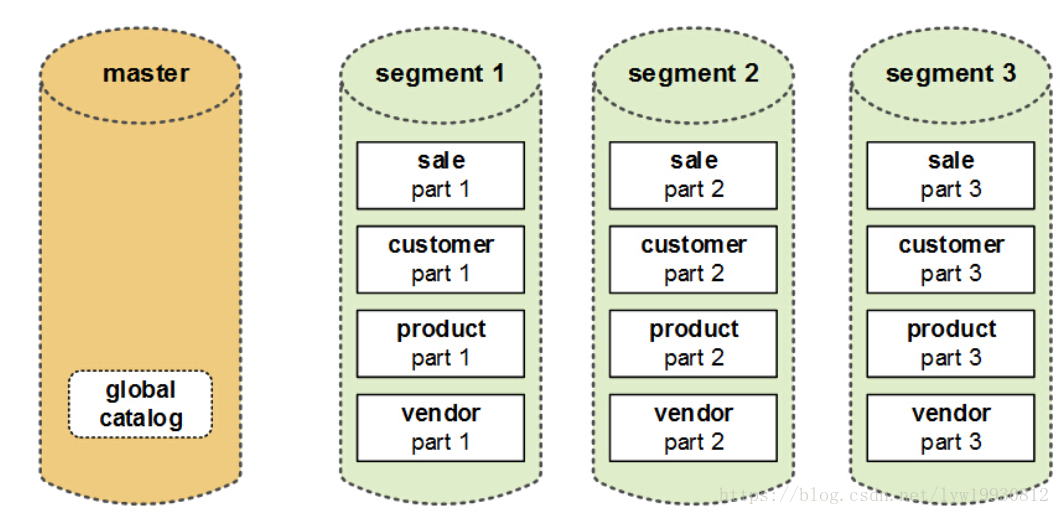
Greenplum是一个分布式数据库系统,因此其所有的业务数据都是物理存放在集群的所有Segment实例数据库上;在Greenplum数据库中所有表都是分布式的,所以每一张表都会被切片,每个Segment实例数据库都会存放相应的数据片段。在下图中sale、customer、vendor、product四张表的数据都会切片存放在所有的Segment上,所有Segment实例同时工作,由于每个Segment只需要计算一部分数据,所以计算效率会大大提升。
由于Greenplum是一个分布式数据库,所以建表时需要指定分布键,将数据平均分布到各个Segment上。Greenplum有两种数据分布策略:
1)Hash分布
当选择Hash分布策略时,可以指定表的一列或者多列组合。greenplum会根据指定的Hash key列计算每一行数据对应的Hash值,并映射到相应的segment实例。当选择的Hash key列的值唯-一时,数据会均匀的分散至所有segment实例。
对于分布键的选择,有以下方式及行为:
1.指定分布键,分布键可以是表的一列或者多列组合,但不建议组合分布键的列数超过两列。
2.若表中存在主键,不能指定其他单列作为唯-一主键,且对于组合分布键,其中必须要包含主键,且主键必须要位于组合分布键的列,否则会报错。
3.若没有指定分布键,且表中没有主键及唯-一键,则默认使用列作为分布键。
4.若没有指定分布键,且表中存在主键或唯-一键(二者不能同时存在),则选择主键或唯-一键作为分布键。
sql例子:CREATE TABLE … DISTRIBUTED BY (column [,…])
2)随机分布
当选择随机分布时,数据将会随机分布至segment,相同值的数据行不一定会分发至同一个segment。虽然随机分布可以确保数据平均分散至所有segment,但是在进行表关联分析时,仍然会按照关联键重分布数据,所以随机分布策略通常不是一个明智的选择(除非你的SQL只有对单表进行全局的聚合操作,即没有group by或者join等需要数据重分部的操作)。
sql例子:CREATE TABLE … DISTRIBUTED RANDOMLY
Greenplum有两种数据存储方式,比如是行存储,还是列存储,是普通的heap表,还是append optimized表。
行存储是行为单位存储数据,一行中越是靠后的列,那么查询需要的cost相对越大,这个以前oracle做过相应比较,都是一样的道理,行存储更适合OLTP的系统。
列存储是以列为单位存储数据,物理上一列会对应一个或者多个数据文件,而且列存储的压缩比比较高,但是如果查询的时候,如果返回的列很多,那么效率不如行存储,列存储更适合对某一列做相关统计,列存储更适合OLAP的系统。
堆表,我们普通的创建的表默认都是堆表,适合频繁的更新删除操作的小表,适合OLTP系统。
AO表,适合批量数据写入,不适合单行的insert,适合大表使用,所以一般用在数据仓库系统,适合OLAP系统。
创建一个heap表
CREATE TABLE foo (a int, b text) DISTRIBUTED BY (a);
不带压缩的ao表
CREATE TABLE bar (a int, b text)
WITH (appendonly=true)
DISTRIBUTED BY (a);
创建列存储表
CREATE TABLE bar (a int, b text)
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (a);四、Greenplum数据库表分区
分区并不会改变表数据在Segment之间的物理分布。表分布是物理的:Greenplum数据库会在物理上把分区表和未分区表划分到多个Segment上来启用并行查询处理。表分区是逻辑的:Greenplum数据库在逻辑上划分大表来提升查询性能并且有利于数据仓库维护任务,例如把旧数据滚出数据仓库。
Greenplum数据库支持:
范围分区:基于一个数字型范围划分数据,例如按照日期或价格划分。
列表分区:基于一个值列表划分数据,例如按照销售范围或产品线划分。
两种类型的组合。
官方分区文档:https://gp-docs-cn.github.io/docs/admin_guide/ddl/ddl-partition.html
本文来源:https://blog.csdn.net/lyw19930812/article/details/83309918
