Azure Data Explorer жҢҮеҚ—
AzureеңЁ2018е№ҙжҺЁеҮәдәҶData Explorerдә§е“ҒпјҢжҸҗдҫӣе®һж—¶жө·йҮҸжөҒж•°жҚ®зҡ„еҲҶжһҗжңҚеҠЎпјҲйқһжөҒи®Ўз®—пјүпјҢйқўеҗ‘еә”з”ЁгҖҒзҪ‘з«ҷгҖҒ移еҠЁз«Ҝзӯүи®ҫеӨҮгҖӮ
з”ЁжҲ·еҸҜд»ҘжҹҘиҜўпјҢ并дәӨдә’ејҸең°еҜ№з»“жһңиҝӣиЎҢеҲҶжһҗпјҢд»ҘиҫҫеҲ°жҸҗеҚҮдә§е“ҒгҖҒеўһејәз”ЁжҲ·дҪ“йӘҢгҖҒзӣ‘жҺ§и®ҫеӨҮгҖҒз”ЁжҲ·еўһй•ҝзӯүзӣ®зҡ„гҖӮе…¶дёӯжҸҗдҫӣдёҖдәӣжңәеҷЁеӯҰд№ еҮҪж•°пјҢиғҪеӨҹиҝӣиЎҢејӮеёёгҖҒжЁЎејҸиҜҶеҲ«гҖҒ并且еҸ‘зҺ°ж•°жҚ®дёӯзҡ„и¶ӢеҠҝгҖӮ
иҜҘжңҚеҠЎйқўеҗ‘з§’-еҲҶй’ҹзә§жӢҝеҲ°з»“жһңзҡ„еңәжҷҜпјҢзұ»OLAPпјҢеҜ№TPеңәжҷҜдёҚж•Ҹж„ҹгҖӮ
дә§е“Ғиө·жәҗ
Azure Data ExplorerпјҲADEпјүеҶ…йғЁд»ЈеҸ·еҸ«KustoпјҢеңЁKustoд№ӢеүҚпјҢAzureеҜ№зӣ‘жҺ§е’ҢеҲҶжһҗеңәжҷҜж•ЈиҗҪеңЁеҗ„дә§е“ҒдёӯпјҢдҫӢеҰӮпјҡLog AnalyticsгҖҒApplication InsightпјҢAzure MonitorпјҢTime Series InsightпјҢиҝҷдәӣдә§е“ҒеңЁз”ЁдёҚеҗҢзҡ„жҠҖжңҜжһ¶жһ„жқҘи§ЈеҶідёҚеҗҢж•°жҚ®жәҗзӯүй—®йўҳпјҢдҫӢеҰӮпјҡ
- йҖҡиҝҮPerfCounterе’ҢEventйҖҡиҝҮжөҒж•°жҚ®иҝӣиЎҢиҒҡеҗҲе‘ҠиӯҰ
- еҲ©з”ЁйҖҡз”Ёи®Ўж•°еҷЁеҶҷе…Ҙж—¶еәҸж•°жҚ®еә“пјҢй…ҚзҪ®е®һж—¶Dashboard
- жҠҠеә”з”Ёж•°жҚ®еҶҷеҲ°ж•°д»“еҒҡж·ұе…ҘеҲҶжһҗ
ADEзҡ„зӣ®ж ҮжҳҜеҜ№дёҠеұӮйў„е®ҡд№үи®Ўз®—гҖҒеҗҺи®Ўз®—еҒҡдёҖеұӮжҠҪиұЎпјҡе°ҶеҺҹе§Ӣж•°жҚ®иҝӣиЎҢйҖҡз”ЁеӯҳеӮЁпјҢдҝқз•ҷдёҖж®өж—¶й—ҙпјҲдҫӢеҰӮеҮ дёӘжңҲпјүпјҢеҜ№иҝҷдәӣеӨҡж ·еҢ–ж•°жҚ®иҝӣиЎҢеҝ«йҖҹзҡ„еӨҡз»ҙеҲҶжһҗгҖӮ
ADEеңЁеҫ®иҪҜзҡ„еҶ…йғЁд»ЈеҸ·дёәKustoпјҢз”ұд»ҘиүІеҲ—з ”еҸ‘еӣўйҳҹжҸҗдҫӣгҖӮAzure Log AnalyticsејҖе§ӢйҖүеһӢжҳҜElastic SearchпјҢжҜҸе№ҙд»ҳ1M$з”ЁжқҘиҺ·еҫ—ж”ҜжҢҒпјҢдҪҶж•ҲжһңдёҚеҘҪпјҢеӣ жӯӨеңЁ2015е№ҙж—¶еҜ№ж—Ҙеҝ—гҖҒMetricеңәжҷҜдҪҝз”ЁKustoжқҘжҸҗдҫӣпјҢеҢ…жӢ¬д№ӢеүҚеңЁcosmosDBдёӯзҡ„еҲҶжһҗе·ҘдҪңгҖӮ
жҲӘжӯў September 2018 зҡ„ж•°жҚ®пјҡ hundreds of teams within Microsoft 41 Azure regions as 2800 Engine+DM cluster pairs about 23000 VMs. overall data size stored in Kusto and available for query is 210 petabytes 6 petabytes ingested daily. around 10 billion queries per month.
еҸҜд»ҘжҺЁжөӢе№іеқҮеӯҳеӮЁж—¶й—ҙдёәпјҡ210 пјҲPBпјү / 6 пјҲPBпјү = 35 еӨ©
дә§е“Ғе®ҡд№ү
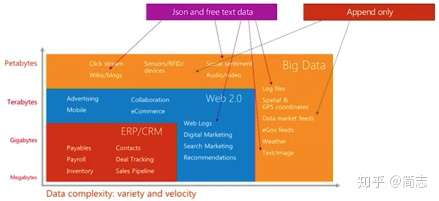
йқўеҗ‘ж•°жҚ®зұ»еһӢжҳҜImmutable DataпјҢзү№зӮ№жҳҜAppendOnlyпјҢ并且еӨ§йғЁеҲҶйғҪжҳҜSemi-Structure DataпјҢдҫӢеҰӮUser Click LogпјҢAccess LogзӯүгҖӮBig DataзҗҶи®әдёӯ90%йғҪжҳҜиҝҷзұ»ж•°жҚ®пјҢиҝҷд№ҹжҳҜBig DataзҗҶи®әж•°еӯ—еҢ–并жҙһеҜҹзү©зҗҶж—¶й—ҙзҡ„еҹәзЎҖгҖӮ
д»ҺFacebookзӯүж•°жҚ®жқҘзңӢпјҢ2017е№ҙж—¶жҜҸеӨ©з”ЁжҲ·дә§з”ҹзҡ„и§Ҷйў‘пјҲUGCпјүеӨ§зәҰеңЁ10PBпјҢдҪҶз”ЁжҲ·зӮ№еҮ»дә§з”ҹзҡ„ж—Ҙеҝ—йҮҸе·Із»Ҹиҝңиҝңи¶…иҝҮ10PBиҝҷйҮҸпјҢеҜ№и§Ҷйў‘зҪ‘з«ҷиҖҢиЁҖпјҢеҶ…е®№ж•°жҚ®еўһйҮҸе°‘дәҺзӮ№еҮ»ж—Ҙеҝ—зҡ„еўһйҮҸе·ІжҲҗдёәйҖҡз”Ёзҡ„规еҫӢгҖӮ
AzureеңЁе®Јдј ж—¶иҝҷж ·е®ҡд№үиҮӘе·ұзҡ„дә§е“Ғпјҡ
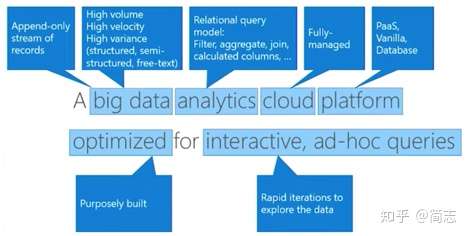
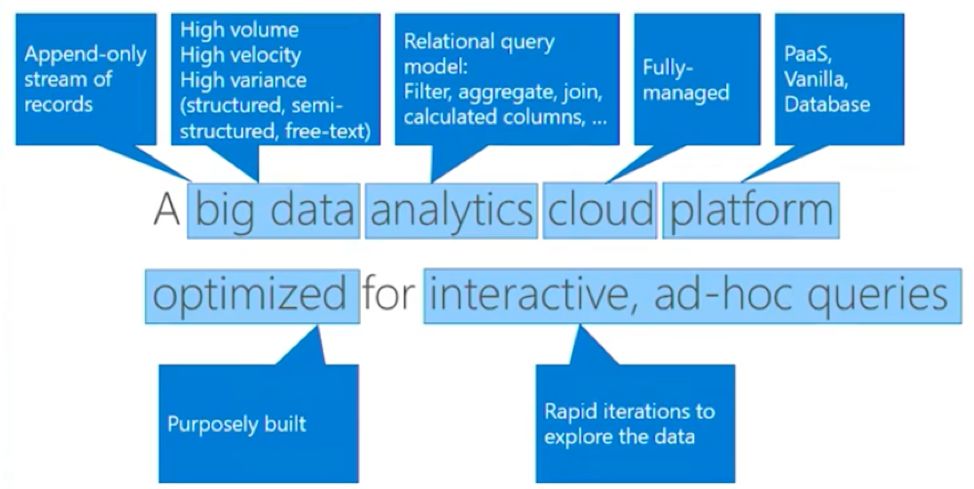
fast, fully managed data analytics service for real-time analysis on large volumes of data streaming from applications, websites, IoT devices, and more.
дә§е“Ғдё»иҰҒи§ЈеҶідёүзұ»й—®йўҳпјҡ Customer Query пјҲAdvance Huntingпјү Interactive UI пјҲеүҚиҖ…е°ҒиЈ…пјү * Background AutomationпјҲе®ҡж—¶д»»еҠЎпјү
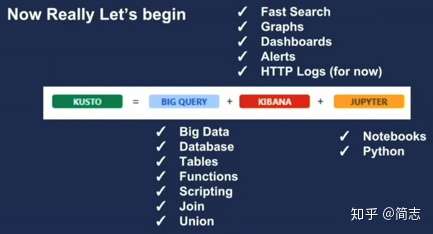
д№ҹжңүдёҖдәӣи§ЈйҮҠеҹәдәҺеҮ дёӘдәӨдә’ејҸдә§е“ҒжқҘи§ЈйҮҠпјҡеә•еұӮжҳҜе®һж—¶OLAPпјҢдёҠеұӮжҳҜJupiterпјҲдәӨдә’ејҸпјү + KibanaпјҲеҸҜи§ҶеҢ–пјү
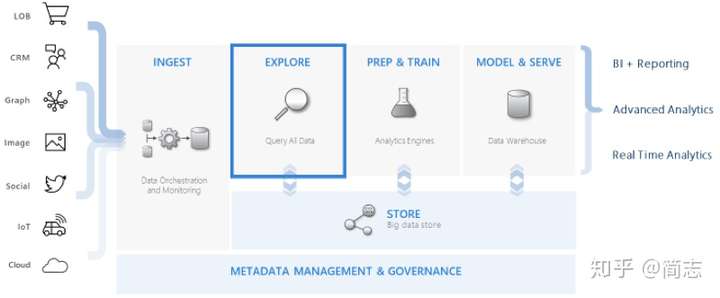
д»Һдә§е“Ғе®ҡдҪҚи§’еәҰиҖғиҷ‘пјҢADEеӨ„дәҺдёӯй—ҙеұӮж¬ЎпјҲеҲ©з”Ёдәәзҡ„дәӨдә’ејҸеҲҶжһҗиғҪеҠӣиҝӣиЎҢеҸ‘жҺҳдёҺжҺўзҙўпјүпјҡ integrates with other major services to provide an end-to-end solution pivotal role in the data warehousing flow by executing the EXPLORE step of the flow on terabytes of diverse raw data
йҷӨжӯӨд№ӢеӨ–ADEпјҲKustoпјүжҳҜ azure application insight, log analytics еҹәзЎҖ дёәAzure Monitor, Azure Time Series Insights, and Windows Defender Advanced Threat ProtectionжҸҗдҫӣж•°жҚ®жңҚеҠЎ * жҸҗдҫӣREST API, MS-TDS, and Azure Resource Manager service endpoints and several client libraries
ж•°жҚ®жЁЎеһӢдёҺAPI
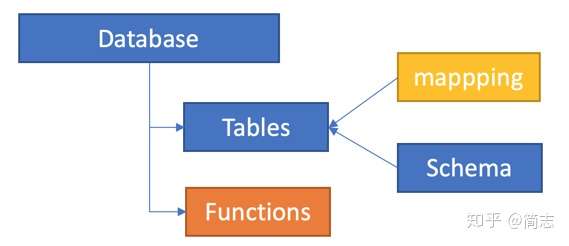
ADEд»Ҙе®һдҫӢж–№ејҸз»ҷз”ЁжҲ·д»ҳиҙ№пјҢз”ЁжҲ·иҙӯд№°дёҖз»„е®һдҫӢеҗҺеҸҜд»ҘеҲӣе»әпјҡ Database TableпјҡеӯҳеӮЁе®һдҫӢпјҢеҢ…еҗ«SchemaпјҲиЎЁз»“жһ„е’Ңеӯ—ж®өзұ»еһӢпјүпјҢMappingпјҲеҰӮдҪ•д»ҺCSVгҖҒAvroзӯүж јејҸжҳ е°„пјү * FunctionsпјҡиҮӘе®ҡд№үеҮҪж•°пјҢеҲ©з”ЁscalarиҜӯиЁҖеҸҜд»Ҙе®ҡд№үиҮӘе®ҡд№үж–№жі•пјҢж–№дҫҝеҗҺжңҹеӨ„зҗҶ
ж•ҙдёӘAPIеҸӘжңүдёҖз»„жҺҘеҸЈпјҢйҖҡиҝҮзұ»KQLж–№жі•жқҘз®ЎзҗҶжҺ§еҲ¶жөҒдёҺж•°жҚ®жөҒпјҢжҺ§еҲ¶жөҒд»Ҙ"."дҪңдёәејҖеӨҙпјҢдҫӢеҰӮ ".create table"гҖӮж•°жҚ®еҲҶжһҗиҜӯиЁҖйҷӨдәҶKQLеӨ–иҝҳж”ҜжҢҒSQLпјҡ TSQLпјҡhttps://docs.microsoft.com/en-us/azure/kusto/api/tds/t-sql KQLпјҡhttps://docs.microsoft.com/en-us/azure/kusto/query/index
д»ҘдёӢжҳҜдёҖдәӣжЎҲдҫӢпјҡ
еҲӣе»әпјҡ
.create table MyLogs ( Level:string, Timestamp:datetime, UserId:string, TraceId:string, Message:string, ProcessId:int32 )
еҲӣе»әжҲ–иҝҪеҠ пјҡ
.create-merge tables MyLogs (Level:string, Timestamp:datetime, UserId:string, TraceId:string, Message:string, ProcessId:int32), MyUsers (UserId:string, Name:string)
.alter column ['Table'].['ColumnX'] type=string
жӣҙж”№еҲ—иЎҢдёәеҗҺпјҢд№ӢеүҚж•°жҚ®дјҡеҸҳжҲҗNullпјҢе»әи®®жҠҠж•°жҚ®зӯӣйҖүеҮәжқҘеҶҷе…Ҙж–°зҡ„Table
жҳ е°„е…ізі»пјҡ
.create table MyTable ingestion csv mapping "Mapping1" '[{ "Name" : "rownumber", "DataType":"int", "Ordinal" : 0},{ "Name" : "rowguid", "DataType":"string", "Ordinal" : 1 }]вҖҷ
.create table MyTable ingestion json mapping "Mapping1" '[{ "column" : "rownumber", "datatype" : "int", "path" : "$.rownumber"},{ "column" : "rowguid", "path" : "$.rowguid" }]'ж•°жҚ®еҶҷе…ҘпјҲingestionпјүдёҺеҜјеҮәпјҲExportпјү
ж•°жҚ®еҶҷе…Ҙжңүдёүз§Қж–№ејҸпјҡ 1. е…¶д»–ж•°жҚ®жәҗпјҢдҫӢеҰӮCSVпјҲEvent Hubзӯүпјү
.ingest into table T ('adl://contoso.azuredatalakestore.net/Path/To/File/file1.ext;impersonate') with (format='csvвҖҷ)- йҖҡиҝҮQueryд»ҺдёҖдёӘTableиҫ“еҮә пјҢжңүеӣӣз§ҚжЁЎејҸ(set, append, set-or-replace, set-or-append)пјҢжҸҗдҫӣејӮжӯҘжҺҘеҸЈ
.set RecentErrors <| LogsTable | where Level == "Error" and Timestamp > now() - time(1h)- Inlineж–№ејҸпјҢзӣҙжҺҘйҖҡиҝҮз®—еӯҗз”ҹжҲҗ
.ingest inline into table Purchases <| Shoes,1000 Wide Shoes,50 "Coats, black",20 "Coats with ""quotes""",5ж•°жҚ®еҜјеҮәжңү2дёӘеӨ§зұ»пјҡ 1. еҜјеҮәеҲ°еӯҳеӮЁпјҲStorageпјүпјҡ
.export async compressed to csv ( h@"https://storage1.blob.core.windows.net/containerName;secretKey", h@"https://storage1.blob.core.windows.net/containerName2;secretKey" ) with ( sizeLimit=100000, namePrefix=export, includeHeaders=all, encoding =UTF8NoBOM )
<| myLogs | where id == "moshe" | limit 10000- еҜјеҮәеҲ°еҸҰеӨ–дёҖдёӘиЎЁпјҲTableпјү:
.export async to sql MySqlTable
h@"Server=tcp:myserver.database.windows.net,1433;Database=MyDatabase;Authentication=Active Directory Integrated;Connection Timeout=30;"
<| print Id="d3b68d12-cbd3-428b-807f-2c740f561989", Name="YSO4", DateOfBirth=datetime(2017-10-15)жҺ§еҲ¶жөҒ
Cursor жҰӮеҝө
ж•°жҚ®еҜје…Ҙж—¶дјҡжңүдёҖдёӘеҢәеқ—зҡ„жҰӮеҝөпјҢд»ЈиЎЁеҗҢдёҖжү№ж•°жҚ®пјҢе…¶дёӯдјҡжңүдёҖдёӘйЎәеәҸзҡ„жёёж ҮпјҲCursorпјү,зұ»дјјKafkaдёӯжҜҸдёӘPartitionдёӯж•°жҚ®зҡ„дҪҚзҪ®гҖӮйҖҡиҝҮCursorеҸҜд»ҘиҺ·еҫ—ж•°жҚ®зҡ„дҪҚзҪ®пјҢCursorд»ҘIngestion Timeдёәдё»пјҲдёҺеӯ—ж®өж— е…іпјүпјҢеҰӮжһңйңҖиҰҒдҪҝз”ЁCursorеҠҹиғҪеҝ…йЎ»жү“ејҖIngestionTimeиҝҷдёӘFeatureгҖӮ
д»ҘдёӢдҫӢеӯҗе°ұиЎЁзӨәеҶҚеҖ’е…ҘеүҚеҗҺиҺ·еҸ–еҲ°жҹҗдёҖдёӘCursorпјҢеңЁеҶҷе…Ҙжҹҗдәӣж•°жҚ®еҗҺпјҢеҸҜд»ҘйҖҡиҝҮCursorжү“еҚ°еҮәеҪ“еүҚдҪҚзҪ®еҗҺзҡ„ж•°жҚ®гҖӮ
.set table Employees policy ingestiontime true
Employees | where cursor_after('')
Employees | where cursor_after('636040929866477946') // -> 636040929866477950
Employees | where cursor_after('636040929866477950') // -> 636040929866479999
Employees | where cursor_after('636040929866479999') // -> 636040939866479000зі»з»ҹз®ЎзҗҶдёҺжҺ§еҲ¶
жҸҗдҫӣзҠ¶жҖҒжҹҘиҜўпјҢе°ұдёҚиөҳиҝ°дәҶпјҡ DiagnosticsпјҲCluster StatusпјҢCapacityпјү JournalпјҲmetadata operations performed on the Kusto databaseпјү QueriesпјҲ.show running queries пјү Commands Commands and Queries Ingestion Failure
еҪ“еүҚж”ҜжҢҒи§’иүІ
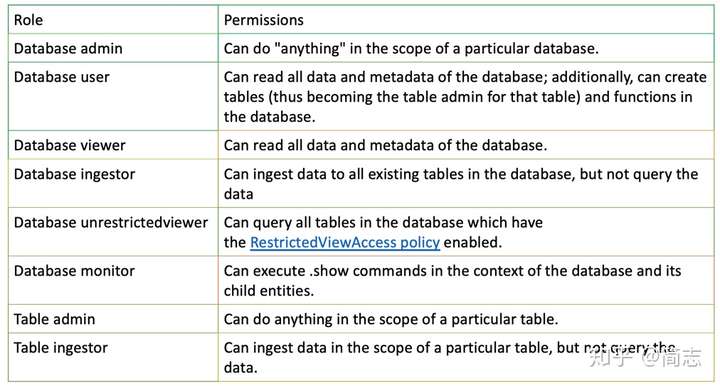
DataShardпјҲextent з®ЎзҗҶпјү
з”ұдәҺжҳҜеҲ—еӯҳеӮЁзі»з»ҹпјҢж•°жҚ®еҶҷе…Ҙж—¶йғҪд»ҘдёҖеӨ§ж®өж•°жҚ®DataShardпјҲExtentпјүж–№ејҸжқҘз»„з»ҮгҖӮжҜҸдёӘTableз”ұиӢҘе№ІExtentз»„жҲҗпјҢжҜҸдёҖжү№еҜје…Ҙж•°жҚ®йғҪдёәдёҖдёӘExtentгҖӮ
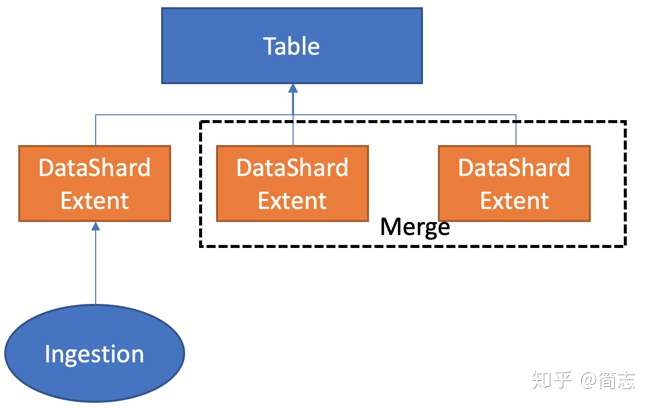
жҜҸдёӘExtentпјҡ йғҪжҳҜimmutableпјҢдёҚеҸҜжӣҙж”№ з”ұдёҖзі»еҲ—е®ҡд№үеҘҪзҡ„еҲ—з»„жҲҗ * жҜҸдёӘеҲ—еӯҳеӮЁеҸҜд»ҘеҲҮеҲҶдёәSegmentsпјҢSegmentsз”ұBlockз»„жҲҗ
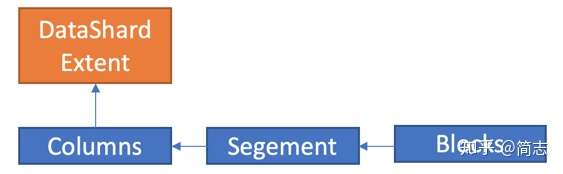
ExtentжңүеҰӮдёӢеұһжҖ§пјҡ Ingestion Timeпјҡд»ЈиЎЁз”ҹжҲҗж—¶й—ҙпјҢз”ҹе‘Ҫе‘ЁжңҹеҗҺзҡ„еӣһ收д№ҹд»ҘиҜҘж—¶й—ҙдёәеҮҶ Retentionпјҡз”ҹе‘Ҫе‘ЁжңҹпјҢе…ҲеҶҷе…Ҙзҡ„Extentдјҡиў«е…Ҳеӣһ收 ExtentжңүCacheиғҪеҠӣпјҢеҸҜд»Ҙи®ҫзҪ®пјҡй»ҳи®ӨCachingзӯ–з•Ҙдёӯж–°зҡ„ж•°жҚ®дјҡжӣҙзғӯ еҰӮжһңжү§иЎҢSamplingпјҡдјҳе…ҲдјҡйҖүжӢ©ж–°зҡ„Extent * ExtentеҜ№з”ЁжҲ·еҸҜд»Ҙи§ҒпјҢеҸҜд»ҘйҖҡиҝҮжү“ж Үж–№ејҸз®ЎзҗҶпјҢдҫӢеҰӮпјҡ
TaggingпјҲз”ЁжқҘз®ЎзҗҶExtentпјү
.ingest ... with @'{"tags":"[\"drop-by:2016-02-17\"]"}' .drop extents <| .show table MyTable extents where tags has "drop-by:2016-02-17"Purge
KustoеңЁеӨ©и®ҫи®Ўзҡ„ж—¶еҖҷпјҢй»ҳи®ӨдёҚж”ҜжҢҒеұҖйғЁеҲ йҷӨпјҢеҸӘж”ҜжҢҒRetentionгҖӮдҪҶGDPRеҮәзҺ°еҗҺеўһеҠ дәҶеұҖйғЁеҲ йҷӨеҠҹиғҪпјҢдҪҶдёҚе»әи®®з”ЁжҲ·дҪҝз”ЁпјҲе»әи®®з”ЁжҲ·йҖҡиҝҮеҖ’йғЁеҲҶж•°жҚ®иҝӣе…ҘеҸҰеӨ–Tableж–№ејҸи§ЈеҶіпјүпјҢд»ҺжҸҸиҝ°зңӢжҳҜзұ»дјјдёҖдёӘMergeиҝҮзЁӢгҖӮ
- Phase 1: йҖҡиҝҮжҹҘиҜўжқЎд»¶жҢҮе®ҡж•°жҚ®
- Phase 2: (Soft Delete) пјҡеҜ№зү№е®ҡж•°жҚ®ж Үи®°VersionпјҢж—¶й—ҙеңЁз§’зә§еҲ°е°Ҹж—¶зә§пјҢеҜ№зү№е®ҡж“ҚдҪңдјҡжңүVersionпјҲеҸҜд»Ҙж’Өй”Җпјү
- Phase 3: (Hard Delete) пјҡе®Ңе…ЁеҲ йҷӨпјҢ5еӨ©еҗҺиҝӣиЎҢпјҢй•ҝ30еӨ©
Policy
- Cache vs Retention
set query_datascope="hotcache"; T | union U | join (T datascope=all | where Timestamp < ago(365d) on X
SoftDeletePeriod = 56d
hot cache policy = 28d- Row Order
- Updateпјҡhttps://docs.microsoft.com/en-us/azure/kusto/concepts/updatepolicy
з”ҹжҖҒ
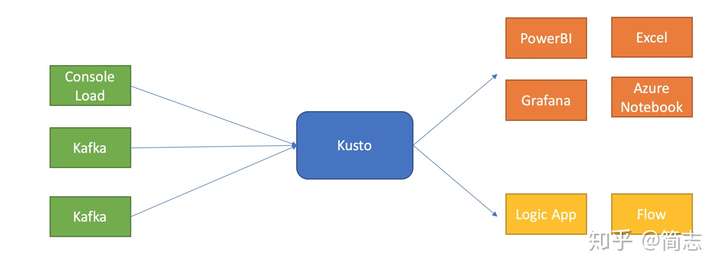
еҲҶжһҗжөҒ
еҢ…жӢ¬жҹҘиҜўиҜӯжі•дёҺжңәеҷЁеӯҰд№ еҮҪж•°пјҢд№ӢеүҚж•ҙзҗҶиҝҮдёҖдёӘPPTпјҲи§Ғйҷ„件пјүпјҢд»ҘPPTдёәдё»
жҠҖжңҜжһ¶жһ„
е»әи®®еҸӮи§ҒзҷҪзҡ®д№ҰпјҢйҮҢйқўиҜҰз»Ҷйҳҗиҝ°дәҶж•°жҚ®пјҢи®Ўз®—иғҪеҠӣе’ҢCacheзӣёе…ізҡ„еә•еұӮжҠҖжңҜгҖӮ
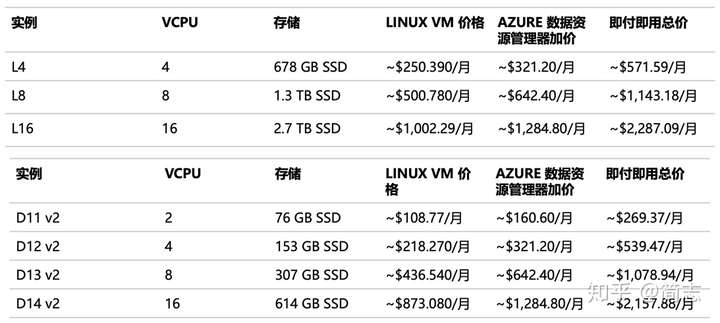
д»·ж јиҜҙжҳҺ
еӯҳеӮЁзҪ‘з»ңеҚ•зӢ¬и®Ўиҙ№пјҢи®Ўз®—йғЁеҲҶйҖҡиҝҮиҙӯд№°е®һдҫӢж–№ејҸиҝӣиЎҢпјҢжҸҗдҫӣдёӨз§Қзұ»еһӢпјҡеӯҳеӮЁдјҳеҢ–гҖҒи®Ўз®—дјҳеҢ–пјүгҖӮеқҰзҷҪжқҘиҜҙд»·ж јдёҚдҫҝе®ңпјҢ并且дёҚжҸҗдҫӣжҢүйҮҸзҡ„ж–№ејҸпјҲLogAnalyticsжҸҗдҫӣжҢүйҮҸд»ҳиҙ№жЁЎејҸпјҢеҸҜд»Ҙи®ӨдёәйңҖиҰҒдёӘжҖ§еҢ–ADEзҡ„з”ЁжҲ·дёҚе·®й’ұеҗ§пјүгҖӮ