1. 摘要
本文演示了使用外部表集成 Vertica 和 Apache Hudi。在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访问这些数据。
2. Apache Hudi介绍
Apache Hudi 是一种变更数据捕获 (CDC) 工具,可在不同时间线将事务记录在表中。Hudi 代表 Hadoop Upserts Deletes and Incrementals,是一个开源框架。Hudi 提供 ACID 事务、可扩展的元数据处理,并统和批处理数据处理。以下流程图说明了该过程。使用安装在 Apache Spark 上的 Hudi 将数据处理到 S3,并从 Vertica 外部表中读取 S3 中的数据更改。

3. 环境准备
•Apache Spark 环境。使用具有 1 个 Master 和 3 个 Worker 的 4 节点集群进行了测试。按照在多节点集群上设置 Apache Spark 中的说明安装 Spark 集群环境[1]。启动 Spark 多节点集群。•Vertica 分析数据库。使用 Vertica Enterprise 11.0.0 进行了测试。•AWS S3 或 S3 兼容对象存储。使用 MinIO 作为 S3 存储桶进行了测试。•需要以下 jar 文件。将 jar 复制到 Spark 机器上任何需要的位置,将这些 jar 文件放在 /opt/spark/jars 中。•Hadoop - hadoop-aws-2.7.3.jar•AWS - aws-java-sdk-1.7.4.jar•在 Vertica 数据库中运行以下命令来设置访问存储桶的 S3 参数:SELECT SET_CONFIG_PARAMETER('AWSAuth', 'accesskey:secretkey');
SELECT SET_CONFIG_PARAMETER('AWSRegion','us-east-1');
SELECT SET_CONFIG_PARAMETER('AWSEndpoint',’<S3_IP>:9000');
SELECT SET_CONFIG_PARAMETER('AWSEnableHttps','');
endpoint可能会有所不同,具体取决于 S3 存储桶位置选择的 S3 对象存储。
4. Vertica和Apache Hudi集成
要将 Vertica 与 Apache Hudi 集成,首先需要将 Apache Spark 与 Apache Hudi 集成,配置 jars,以及访问 AWS S3 的连接。其次,将 Vertica 连接到 Apache Hudi。然后对 S3 存储桶执行 Insert、Append、Update 等操作。按照以下部分中的步骤将数据写入 Vertica。 在 Apache Spark 上配置 Apache Hudi 和 AWS S3[2] 配置 Vertica 和 Apache Hudi 集成[3]
4.1 在 Apache Spark 上配置 Apache Hudi 和 AWS S3
在 Apache Spark 机器中运行以下命令。这会下载 Apache Hudi 包,配置 jar 文件,以及 AWS S3
/opt/spark/bin/spark-shell \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"\--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1导入Hudi的读、写等所需的包:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._使用以下命令根据需要配置 Minio 访问密钥、Secret key、Endpoint 和其他 S3A 算法和路径。
spark.sparkContext.hadoopConfiguration.set("fs.s3a.access.key", "*****")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.secret.key", "*****")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.endpoint", "http://XXXX.9000")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.path.style.access", "true")
sc.hadoopConfiguration.set("fs.s3a.signing-algorithm","S3SignerType")创建变量来存储 MinIO 的表名和 S3 路径。
val tableName = “Trips”
val basepath = “s3a://apachehudi/vertica/”准备数据,使用 Scala 在 Apache spark 中创建示例数据
val df = Seq(
("aaa","r1","d1",10,"US","20211001"),
("bbb","r2","d2",20,"Europe","20211002"),
("ccc","r3","d3",30,"India","20211003"),
("ddd","r4","d4",40,"Europe","20211004"),
("eee","r5","d5",50,"India","20211005"),
).toDF("uuid", "rider", "driver","fare","partitionpath","ts")将数据写入 AWS S3 并验证此数据
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)使用 Scala 运行以下命令以验证是否从 S3 存储桶中正确读取数据。
spark.read.format("hudi").load(basePath).createOrReplaceTempView("dta")
spark.sql("select _hoodie_commit_time, uuid, rider, driver, fare,ts, partitionpath from dta order by uuid").show()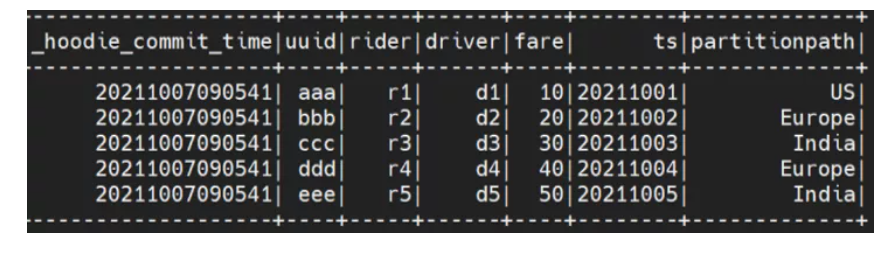
4.2 配置 Vertica 和 Apache HUDI 集成
在 vertica 中创建一个外部表,其中包含来自 S3 上 Hudi 表的数据。我们创建了“旅行”表。
CREATE EXTERNAL TABLE Trips
(
_hoodie_commit_time TimestampTz,
uuid varchar,
rider varchar,
driver varchar,
fare int,
ts varchar,
partitionpath varchar
)
AS COPY FROM
's3a://apachehudi/parquet/vertica/*/*.parquet' PARQUET;运行以下命令以验证正在读取外部表:

4.3 如何让 Vertica 查看更改的数据
以下部分包含为查看 Vertica 中更改的数据而执行的一些操作的示例。
4.3.1 写入数据
在这个例子中,我们使用 Scala 在 Apache spark 中运行了以下命令并附加了一些数据:
val df2 = Seq(
("fff","r6","d6",50,"India","20211005")
).toDF("uuid", "rider", "driver","fare","partitionpath","ts")运行以下命令将此数据附加到 S3 上的 Hudi 表中:
df2.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)4.3.2 更新数据
在这个例子中,我们更新了一条 Hudi 表的记录。需要导入数据以触发并更新数据:
val df3 = Seq(
("aaa","r1","d1",100,"US","20211001"),
("eee","r5","d5",500,"India","20211001")
).toDF("uuid", "rider", "driver","fare","partitionpath","ts")运行以下命令将数据更新到 S3 上的 HUDI 表:
df3.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)以下是 spark.sql 的输出:
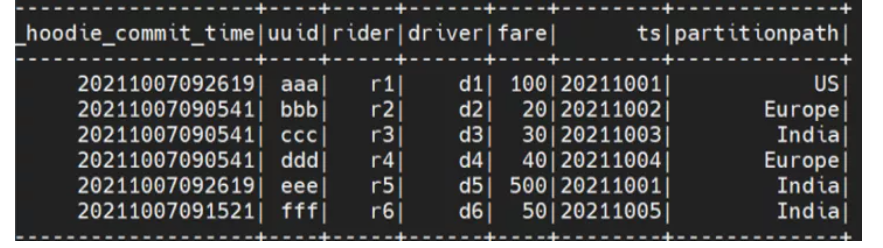
以下是 Vertica 输出:

4.3.3 创建和查看数据的历史快照
执行以下指向特定时间戳的 spark 命令:
val dd = spark.read
.format("hudi")
.option("as.of.instant", "20211007092600")
.load(basePath) 使用以下命令将数据写入 S3 中的 parquet:
dd.write.parquet("s3a://apachehudi/parquet/p2")在此示例中,我们正在读取截至“20211007092600”日期的 Hudi 表快照。
dd.show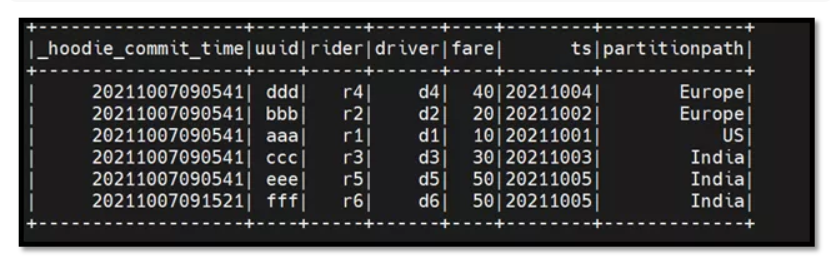
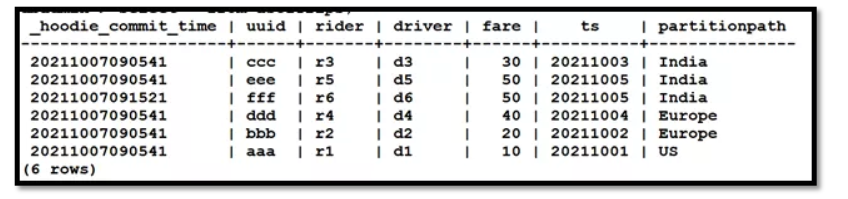
通过在 parquet 文件上创建外部表从 Vertica 执行命令。
来源 https://mp.weixin.qq.com/s?src=11×tamp=1644996161&ver=3623&signature=q07KVpRQKnOKwso3fILmPM0xvsB*gXS5nfwOU3rU0DaNk*Hq-0i*nTq9vJUJI0yL7C*-q-DGzugpNLMLueu67koJAWIo9lisqgJ2GruweY5xkq8Zovbp6ecfrkiuw3UW&new=1
