本文由极客时间整理自微博研发中心基础架构部系统架构开发工程师臣勇在 QCon+ 案例研习社的演讲《微博 KV 服务探索与实践》。
你好,我是来自新浪微博的臣勇,我目前负责 KV 缓存与存储相关的工作,今天和您交流分享的是微博在 KV 服务上的探索与实践。
首先介绍一下目前 Redis 和 Memcached 在微博里的应用情况,我们遇到的问题以及如何解决这些问题。接下来会介绍几个落地案例,后做一个总结。其中重点在我们的解决方案上。

Redis / Memcached 在微博应用的现状
Redis 和 Memcached 在互联网的应用非常广泛,微博从 2010 年开始引入 Redis 和 Memcached,在社区版基础上做了大量的定制化开发,广泛应用于 Feed 流、用户关系、转发、评论、赞记数等场景。目前 Redis 和 Memcached 的实例数量在万级,数据量在 PB 级,每天的调用量在 10 万亿级。大部分业务对性能的要求是 P99 要在 10ms 以内,所以带来的问题是管理的复杂度较高。
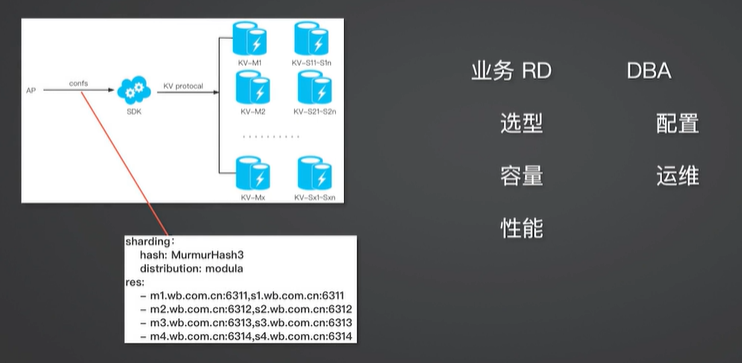
典型使用姿势
业务的典型使用姿势是什么样的呢?首先,业务 RD 会做选型,是用 Redis 还是 Memcached 或者其他的一些 KV 存储,根据自己的业务情况做容量估算和性能上的估算,然后和 DBA 一起做相应的配置的规划,比如分成多少个端口。

对资源的访问
接着把配置交给业务方,业务 RD 把配置文件配置给自己的业务 SDK,由 SDK 实现对后端资源的连接。这种情况下有时候会出现问题,其中一个典型的场景就是随着业务的增长,原来的单个分片的容量可能不够,比如说读容量不够,写达到容量上限,或者单个分片的数据太大达到单实例的上限,给后来的运维带来很大的麻烦。我们一般会考虑业务扩容,但是扩容时怎么扩、扩多少都是问题,谁参与、怎么参与也是问题。
扩多少通常根据具体情况来确定,比如写量有了瓶颈可能会做相应端口的拆分。拆分时具体去怎么拆分?有两种拆分方式:离线的方式和在线的方式。而对于线上的场景来说,离线的方式比较少,因此一般会做在线的拆分。如何做在线的拆分呢?业务方根据拆分前后的资源情况做双写,或者当情况比较复杂时使用专用拆分工具。
作为基础服务的研发人员,我们要考虑能不能减轻业务 RD 的负担。业务 RD 只是想要使用 KV 的缓存或服务,而拆分时,他要考虑资源的拆分情况和分布情况,做相应的资源评估,对他来说这会引入额外的负担。对于 DBA 来说也可能会增加负担,因为他要时刻关注资源的性能情况。
能不能减轻业务 RD 和 DBA 的负担呢?为什么会有这些问题?其实根源还是在于业务 RD 和 DBA 看到的是组件,它是通过一组域名或者端口去访问资源的,所以在使用前、使用中都需要去关注这些资源的细节。比如说容量,初始容量如果评估很准确,可能后面资源浮动会比较平稳。如果说初始容量不准确或者容量增长比较快,后续容量就需要做变更。然后是分片的数量,如果单个分片的数据量比较大,可能后面就要重新做分片。读写能力亦是如此,需要根据业务上线后的情况随时去做人工跟踪和调整。
那么能不能从资源后端屏蔽这些资源细节,让业务 RD 和 DBA 不用去关注这些细节?对外不提供组件,而是提供服务,让服务自己内部去消化资源上的管理细节。

系统架构示意图
这是我们现在做的一个架构的示意图,资源服务是由两个部分组成,一部分是资源访问,一部分是资源管理。资源管理由逻辑上的 Manager 实现,资源访问由资源 Mesh 实现。资源管理和资源访问交互的界面是 Config server, 也就是配置中心。
资源 Mesh 的定位是资源访问,在 Service Mesh 架构里面属于 Sidecar 模式。资源 Mesh 的核心功能有四点。是服务发现,这是基础功能。第二是流量协议请求和响应路由。第三是连接管理和优化。连接管理优化很重要,因为后端资源能承载的连接数有限,如果连接数设置较少,前端应用可能会有性能上的问题。如果设置的过多,后端资源可能会对连接数产生竞争,例如扩容前端应用时没有连接数可用往往会导致扩容失败。第四是特定协议的个性化需求。我们针对 MC 的 Memacached 协议做了一些定制化的开发,实现了跨机房的数据同步。
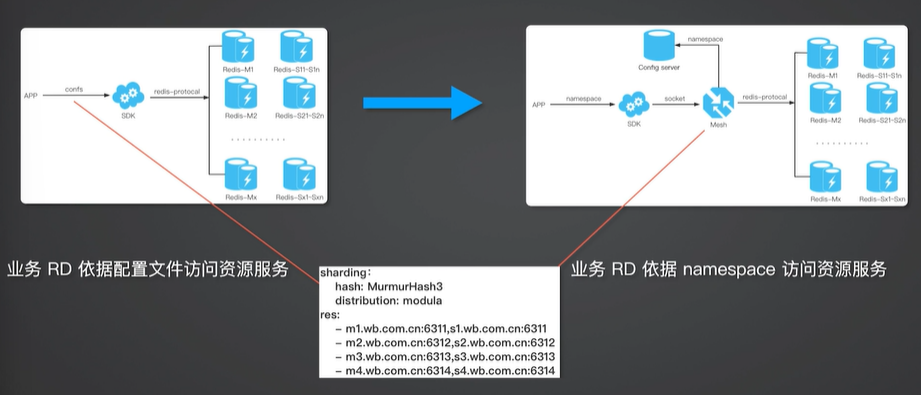
资源 Mesh 屏蔽资源使用细节
另外一个需要考虑的重点是性能,主要体现在耗时方面,资源 Mesh 引入的耗时不能太多。资源 Mesh 怎么去屏蔽资源的使用细节?以前的模式是业务 RD 根据配置文件访问资源,SDK 通过这种配置文件直接访问后端的资源连接,通过 Mesh 业务只看到一个 namespace,通过 namespace 和资源 Mesh 建立连接,由资源 Mesh 具体实现和后端的资源连接。这样在整个业务的生命周期里 namespace 不变,所以业务方访问的资源是不变的。
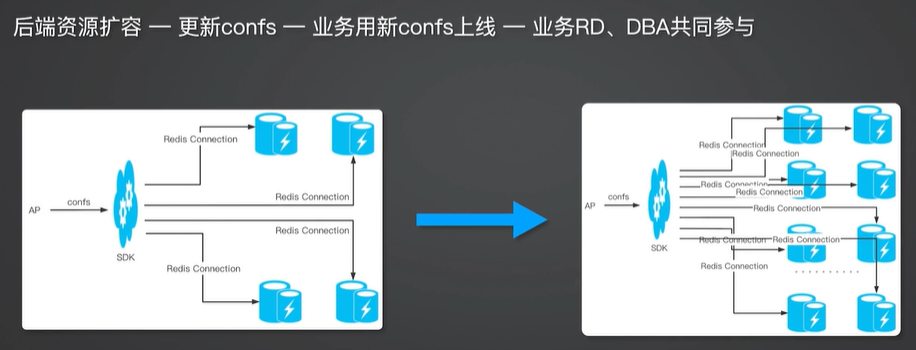
端口扩容的常规做法
这时后端资源的这种变化就由资源 Mesh 来屏蔽了,比如说端口扩容。端口扩容的常规做法是先进行后端资源扩容,接着业务方更新相应的 confs 文件,然后使用新的 confs 文件上线,这时需要业务 RD 和 DBA 共同参与。
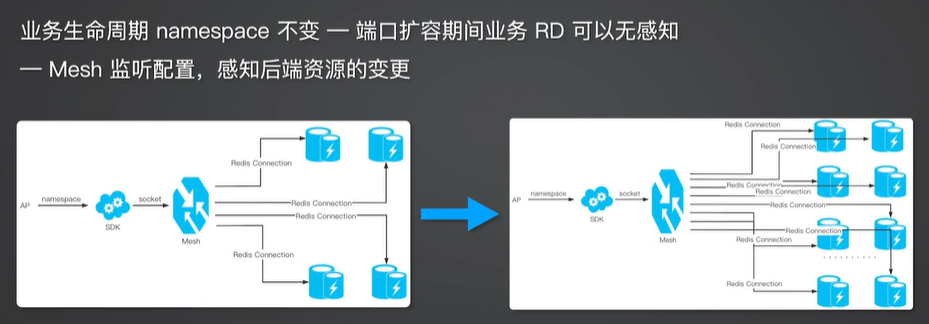
资源 Mesh 配合
如果资源 Mesh 来实现这个扩容要怎么做?应用这边通过 namespace 去访问资源 Mesh,因为整个生命周期里面 namespace 不变,所以端口扩容期间业务 RD 也是无感知的,Mesh 这边监听后端资源的变化,当资源发生变更之后就会连接新的一套资源列表。这样就实现了业务和 DBA 都无感知的场景。
资源管理服务还有一些其他功能,比如内置的扩缩容服务。刚才介绍的是资源 Mesh 的服务,现在介绍一下资源管理相关的服务,其中之一是内置的平滑扩缩容服务。

传统的垂直扩容
传统的垂直扩缩容是这样的,业务方准备一些代码变更,要兼容扩容前后数据分片情况,接着 DBA 进行拆分前后资源数据准备,再做数据的拆分。我们之前的模式采用的是在线拆分,就是针对线上的一个资源数据做一个伪装的从实例,然后从伪装的从上面把数据给拆到新的资源列表上面去。数据拆分完成后业务方校验,如果拆分前后的数据校验没问题,就会做流量切换。
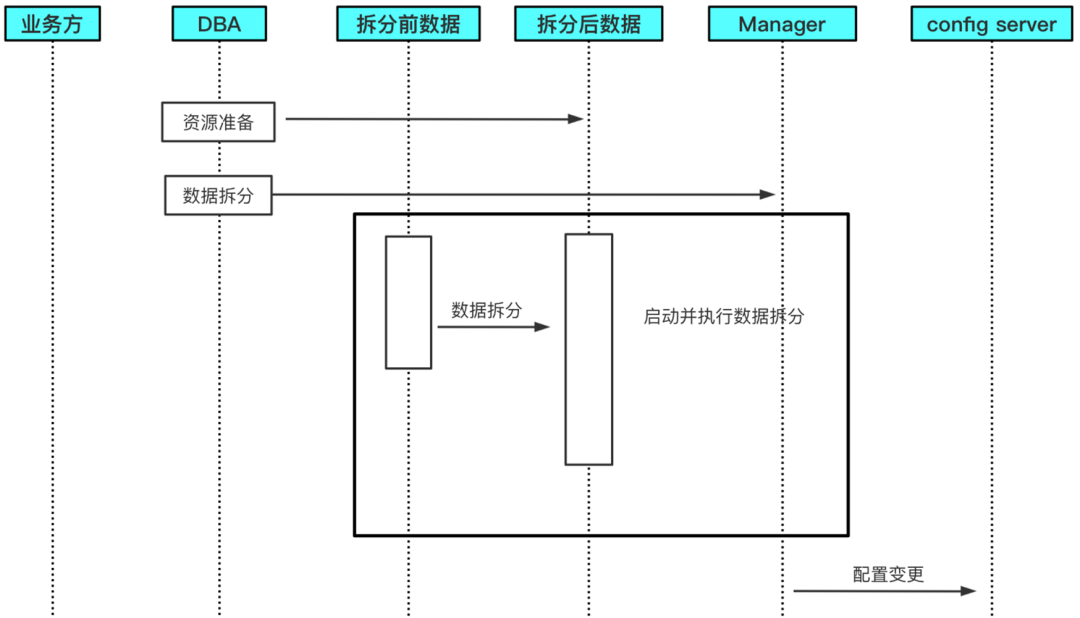
内置扩容服务
内置的扩缩容服务相对来说更简单一些,只需要先把资源和拆分后的数据准备好,资源管理服务可以通过 API 启动,通过资源 API 调用资源管理服务的接口就可以实现数据拆分。以前的扩容模式持续时间需要数周,现在通过这种内置扩容服务仅需几天就可以完成。
资源管理服务还有一些其他的功能,比如常见的一些自动故障处理。一个场景是实例宕机。资源管理服务实际上内部也是拆分成多个小的模块,它在每一个宿主机上或者说在 Kubernetes 里面每一个 Pod 上会部署一个执行的角色,它实现资源状况的信息汇报,二进制程序的安装以及实例的启动,会有一个资源管理的角色执行资源服务。比如实例宕机场景,Executor 监测到实例宕机就会把它汇报给资源管理,资源管理这边识别之后会自动寻找有空闲的主机资源 ,去部署一个新的实例,挂到线上的服务里面去。
实例 SLA 异常与之类似,Excutor 采取的策略是定时地 Ping 相应的资源,如果实例异常了,比如 Hang 长时间不响应就会对它进行处理,把它从服务池里面摘掉,扩建一个新区域去提供相应的服务。
接下来讲一下我们的案例。其实落地的时候就会有一些策略,首先会涉及到的一个问题是选择谁去落地?是选择核心业务,还是边缘业务去落地?如果选核心业务,优势在于推广时很容易推广,劣势在于如果出现问题再想推广就会很麻烦。如果选边缘业务,优势是如果它出现问题不会影响到大局,可以很容易地把它恢复过来。
我们的策略是选核心业务,因为后续推广时比较好推广。既然选定了对象就涉及到怎么去落地,涉及到一些准备,要提前做一些预案。事先要充分验证服务功能,比如从现场拷贝一些流量做上线前的准备验证。还要做预案,出现问题之后怎么回滚?要有回滚的策略,要有怎么去发现问题的策略。
上线涉及到替换,替换原有的服务是全量替换还是少量替换?功能方面是全部的功能替换还是部分功能替换?在开发时我们就定了一些策略,可以只替换一部分功能,可以逐步打开资源 Mesh 相应的功能,所以我们选取的策略是先替换部分功能,做少量实例的替换,也就是说业务在落地的时候是逐步放量的,这样有利于控制风险。上线之后会涉及到监控指标和预警,从业务层面和资源 Mesh 服务层面都要做相应的监控,要有相应的预警指标和应对方案。

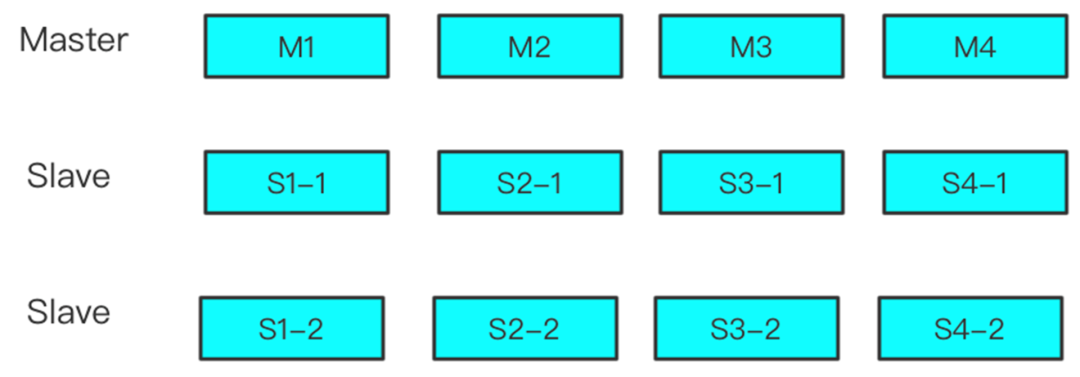
Memcached 资源数据拓扑示意图
这是 Memcached 资源数据拓扑示意图,上面有两个机房,中间竖线两侧是两个机房,一个 IDC 永丰, 一个 IDC 土城。微博针对 Memcached 做了一个缓存预热和跨地域同步方案,由 Mesh 来实现这里的逻辑。其逻辑是这样的,竖轴方向也就是 Y 轴方向将数据分成四片,横轴方向是横向分层,看到有 L1 层、Master 层、Slave 层。层间的数据有一个同步策略,也由资源 Mesh 实现。
这种跨机房数据同步是怎么实现的?IDC 永丰机房的 Master 在逻辑上是 IDC 土城机房的 Slave。这样在有数据需要回种时,数据访问的顺序是先访问 L1,如果 L1Miss 会访问 Master,如果 Master 有,会回写到 L1 和其他层。如果 Master 也 Miss 了可能要通过 DB 回种。这种场景就是通过 Master 对于各层间数据的回写来实现跨机房数据同步。
为什么需要这种方式呢?比如单片数据上的访问量是 100 万 QPS,假设有 1% 的访问 Miss,折算下来就是 1 万 QPS。如果后端 DB 用的 MySQL,1 万的访问量很可能会把 MySQL 打死。在微博场景下,尤其是有热点时,访问量可能会飙升至千万 QPS,如果 Cache Miss 的量比较大,会导致后端的资源访问回穿 DB,把 DB 打穿,那么整个服务可能会崩掉。
所以我们采取固定分片的方式,通过多层 Cache 实现数据的缓存同步以及缓存预热。当出现急速热点时,我们会扩几层 L1,通过多层 L1 分担读的压力,这就是数据分片。
还有一种策略是一致性 Hash。比如有一片数据宕掉,它的访问会打到它临近的 Hash 节点上去,在量特别大的场景下会使得单个节点的数据量也变得很大,那么一方面单片资源数据量容易出现内存溢出之类的问题,另一方面读量可能也无法承担。所以微博采取固定分片的方式做数据拆分,通过多级 Cache 一致性实现数据的缓存和预热以及跨机房的数据同步。整个逻辑是在 Mesh 这边实现的,这是 Memcached 的落地情况,目前应用在信息流分发的一些场景里。
资源数据拓扑示意图竖轴方向
这是 Redis 的落地情况,Redis 也采取固定分片的方式落地,Mesh 主要实现读写连接管理策略。单片数据的同步通过 Redis 自己的主从实现同步机制,因为 Memcached 是没有主从概念的,所以 Mesh 自己实现主从同步机制。
基础服务的出发点和落脚点都是易用可靠,让业务 RD 和 DBA 用起来简单。此外,我们在实现这个系统时针对系统服务侧的资源访问和资源管理都做了功能上的解耦,如果一个服务特别大,把这个服务的多个功能适当解耦有利于项目的推进和质量控制。
关于 Memcached 落地的场景,我的经验就是在大流量高并发的场景下资源的固定分片策略比一致性 Hash 策略更有优势。从落地的情况来看,对于存量项目的架构改造需要循序渐进,可以从小的功能点着手替代,再逐步推进项目。
复盘一下整个项目,如果从头再来有什么能做得更好的地方?比如业务分片规则,我们在推广时发现不同的业务使用不同的分片规则,那么资源 Mesh 就要做相应的适配。实际上业务上线时可能随意地选了一个分片规则,如果上线时统一分片规则或者定量地描述分片规则,就会给后续的架构改造和升级省很多事。
此外,在系统上线服务的运行当中我们发现在故障管理方面还有很多优化空间。管理的资源数量实例非常多,现在是基于规则的检测,人工根据经验或者常见问题制定相应的规则,基于这种规则去报警并做出应对措施。如此一来就会存在误报风险,给运维工作带来干扰。如何引入和细化 AIOps 也是一个不小的课题,这需要多方的力量共同推进。
日拱一卒
后来分享一个我非常喜欢的词:“日拱一卒”。我为什么会喜欢这个词呢?在项目管理领域,如果有一个大项目,把大项目拆解成小项目或者小目标,能够阶段性地实现这些目标一方面能够鼓舞团队士气,另一方面也为达成大目标提供了路线图,这样会更容易达成整体目标。
另外在学习领域,我们常常会定一个比较大的学习目标,比如要学习一种新的语言,可以把这个大目标拆解成小目标,再逐步实现这些小的目标,累积起来之后就会实现整体的大目标。前段时间有个定律很流行,叫一万小时定律,在一个领域持续累积一万个小时,你很可能会成为这个领域的专家。我们对于制定自己的学习目标也是如此,通过小目标的累积去实现大目标通常会有非常可观的收获。
作者简介
臣勇微博研发中心基础架构部系统架构开发工程师目前就职于微博基础架构部,主要从事缓存、计数、发号、KV 存储、消息队列、数据备份与恢复等基础服务的研发工作。拥有丰富的高并发、高性能、高可用基础服务架构与开发经验。
