我们先来看看这张图,这是某公司使用的大数据平台架构图,大部分公司应该都差不多:
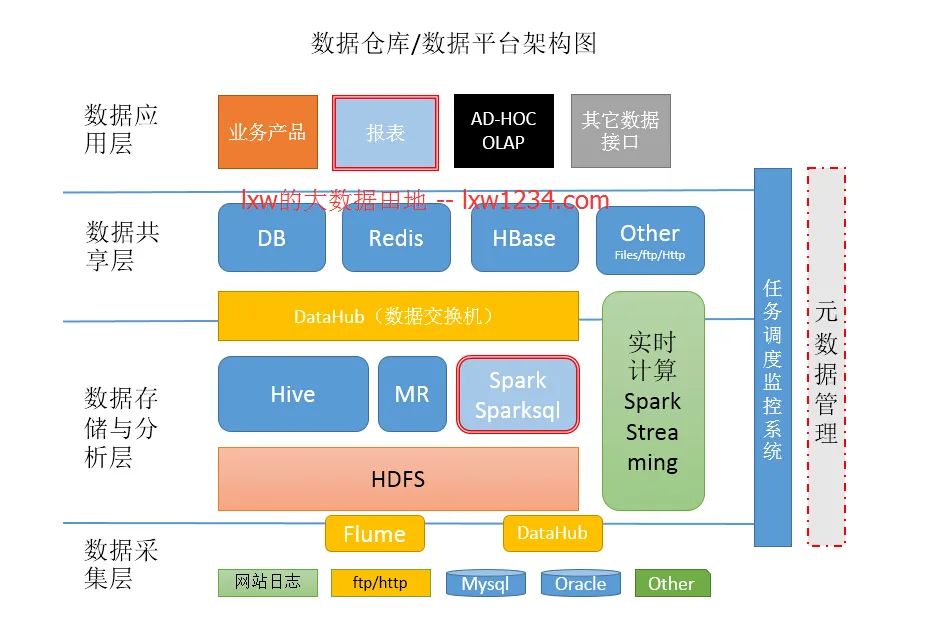
从这张大数据的整体架构图上看来,大数据的核心层应该是:数据采集层、数据存储与分析层、数据共享层、数据应用层,可能叫法有所不同,本质上的角色都大同小异。
所以我下面就按这张架构图上的线索,慢慢来剖析一下,大数据的核心技术都包括什么。
数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些简单的清洗。
数据源的种类比较多:
-
网站日志:
作为互联网行业,网站日志占的份额大,网站日志存储在多台网站日志服务器上,一般是在每台网站日志服务器上部署flume agent,实时的收集网站日志并存储到HDFS上; -
业务数据库:
业务数据库的种类也是多种多样,有Mysql、Oracle、SqlServer等,这时候,我们迫切的需要一种能从各种数据库中将数据同步到HDFS上的工具,Sqoop是一种,但是Sqoop太过繁重,而且不管数据量大小,都需要启动MapReduce来执行,而且需要Hadoop集群的每台机器都能访问业务数据库;应对此场景,淘宝开源的DataX,是一个很好的解决方案,有资源的话,可以基于DataX之上做二次开发,就能非常好的解决。
当然,Flume通过配置与开发,也可以实时的从数据库中同步数据到HDFS。 -
来自于Ftp/Http的数据源:
有可能一些合作伙伴提供的数据,需要通过Ftp/Http等定时获取,DataX也可以满足该需求; -
其他数据源:
比如一些手工录入的数据,只需要提供一个接口或小程序,即可完成。
毋庸置疑,HDFS是大数据环境下数据仓库/数据平台完美的数据存储解决方案。
离线数据分析与计算,也就是对实时性要求不高的部分,在笔者看来,Hive还是首当其冲的选择,丰富的数据类型、内置函数;压缩比非常高的ORC文件存储格式;非常方便的SQL支持,使得Hive在基于结构化数据上的统计分析远远比MapReduce要高效的多,一句SQL可以完成的需求,开发MR可能需要上百行代码。
当然,使用Hadoop框架自然而然也提供了MapReduce接口,如果真的很乐意开发Java,或者对SQL不熟,那么也可以使用MapReduce来做分析与计算。
Spark是这两年非常火的,经过实践,它的性能的确比MapReduce要好很多,而且和Hive、Yarn结合的越来越好,因此,必须支持使用Spark和SparkSQL来做分析和计算。因为已经有Hadoop Yarn,使用Spark其实是非常容易的,不用单独部署Spark集群。
这里的数据共享,其实指的是前面数据分析与计算后的结果存放的地方,其实就是关系型数据库和NOSQL数据库;前面使用Hive、MR、Spark、SparkSQL分析和计算的结果,还是在HDFS上,但大多业务和应用不可能直接从HDFS上获取数据,那么就需要一个数据共享的地方,使得各业务和产品能方便的获取数据;和数据采集层到HDFS刚好相反,这里需要一个从HDFS将数据同步至其他目标数据源的工具,同样,DataX也可以满足。
另外,一些实时计算的结果数据可能由实时计算模块直接写入数据共享。
-
业务产品(CRM、ERP等) 业务产品所使用的数据,已经存在于数据共享层,直接从数据共享层访问即可; -
报表(FineReport、业务报表)
同业务产品,报表所使用的数据,一般也是已经统计汇总好的,存放于数据共享层; -
即席查询 即席查询的用户有很多,有可能是数据开发人员、网站和产品运营人员、数据分析人员、甚至是部门老大,他们都有即席查询数据的需求; 这种即席查询通常是现有的报表和数据共享层的数据并不能满足他们的需求,需要从数据存储层直接查询。 即席查询一般是通过SQL完成,大的难度在于响应速度上,使用Hive有点慢,可以用SparkSQL,它的响应速度较Hive快很多,而且能很好的与Hive兼容。 当然,你也可以使用Impala,如果不在乎平台中再多一个框架的话。推荐一个 Spring Boot 基础教程及实战示例:https://github.com/javastacks/spring-boot-best-practice -
OLAP 目前,很多的OLAP工具不能很好的支持从HDFS上直接获取数据,都是通过将需要的数据同步到关系型数据库中做OLAP,但如果数据量巨大的话,关系型数据库显然不行; 这时候,需要做相应的开发,从HDFS或者HBase中获取数据,完成OLAP的功能;比如:根据用户在界面上选择的不定的维度和指标,通过开发接口,从HBase中获取数据来展示。 -
其它数据接口 这种接口有通用的,有定制的。比如:一个从Redis中获取用户属性的接口是通用的,所有的业务都可以调用这个接口来获取用户属性。
现在业务对数据仓库实时性的需求越来越多,比如:实时的了解网站的整体流量;实时的获取一个广告的曝光和点击;在海量数据下,依靠传统数据库和传统实现方法基本完成不了,需要的是一种分布式的、高吞吐量的、延时低的、高可靠的实时计算框架;Storm在这块是比较成熟了,但我选择Spark Streaming,原因很简单,不想多引入一个框架到平台中,另外,Spark Streaming比Storm延时性高那么一点点,那对于我们的需要可以忽略。
我们目前使用Spark Streaming实现了实时的网站流量统计、实时的广告效果统计两块功能。
做法也很简单,由Flume在前端日志服务器上收集网站日志和广告日志,实时的发送给Spark Streaming,由Spark Streaming完成统计,将数据存储至Redis,业务通过访问Redis实时获取。
在数据仓库/数据平台中,有各种各样非常多的程序和任务,比如:数据采集任务、数据同步任务、数据分析任务等;
这些任务除了定时调度,还存在非常复杂的任务依赖关系,比如:数据分析任务必须等相应的数据采集任务完成后才能开始;数据同步任务需要等数据分析任务完成后才能开始;
这就需要一个非常完善的任务调度与监控系统,它作为数据仓库/数据平台的中枢,负责调度和监控所有任务的分配与运行。
来源:http://lxw1234.com/archives/2015/08/471.htm
版权申明:内容来源网络,版权归原创者所有。除非无法确认,都会标明作者及出处,如有侵权,烦请告知,我们会立即删除并致歉!
