总第507篇
2022年 第024篇

1 现状与问题
1.1 规模增长与运维能力发展之间的不平衡问题凸显
1.2 理想很丰满,现实很骨感
2 解决的思路
2.1 既解决短期矛盾,也立足长远发展
2.2 夯实基础能力,赋能上层业务,实现数据库自治
2.3 建立科学的评估体系,持续的跟踪产品质量
3 技术方案
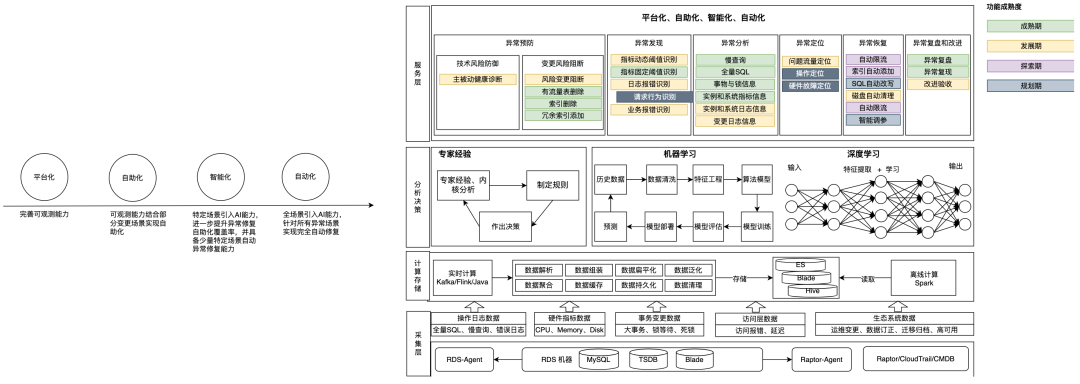
3.1 技术架构的顶层设计
3.2 数据采集层的设计
3.3 计算存储层的设计
3.4 分析决策层的设计
4 建设成果
4.2 用户案例
5 总结与未来展望
1 现状与问题
1.1 规模增长与运维能力发展之间的不平衡问题凸显
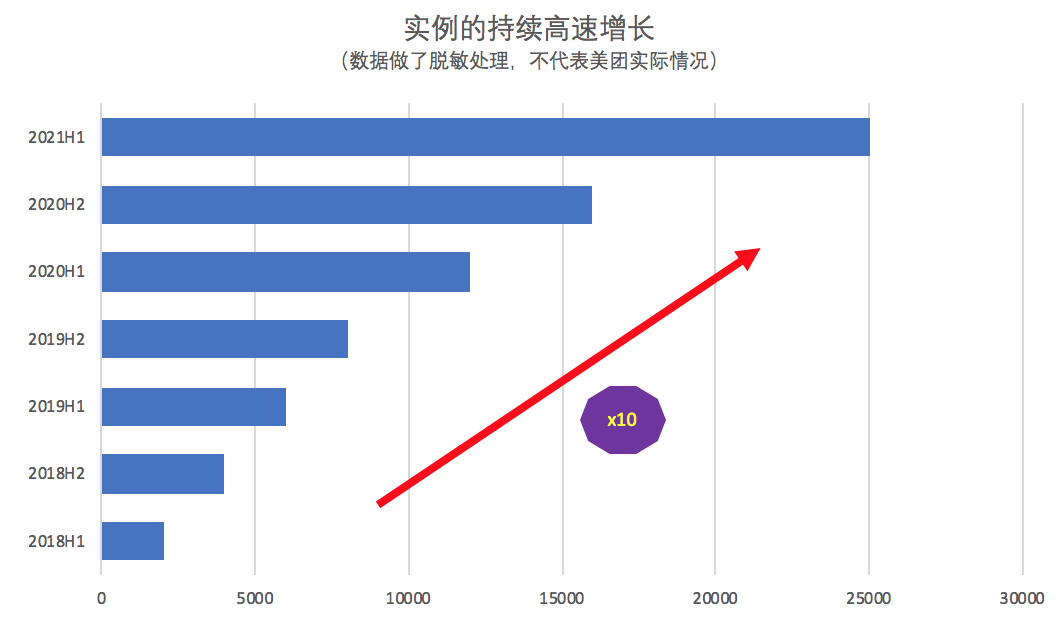
1.2 理想很丰满,现实很骨感
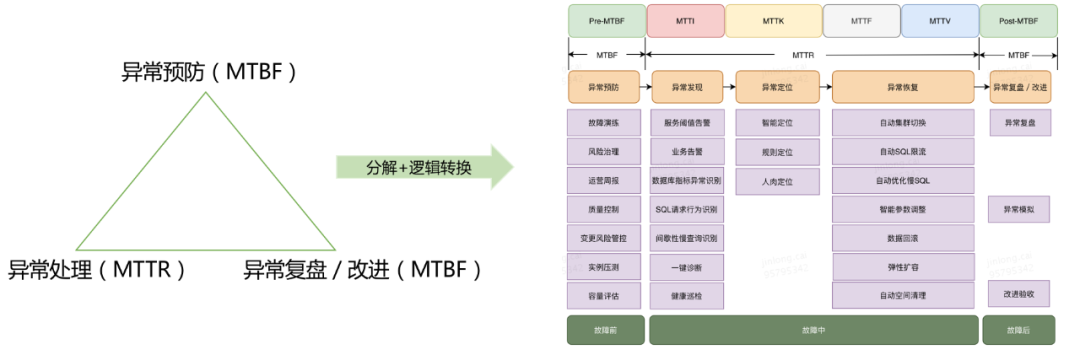
每个环节我们都有相关的工具支撑,但能力又不够强,相比头部云厂商大概20%~30%左右的能力,短板比较明显。 自助化和自动化能力也不足,工具虽多,但整个链条没有打通,未形成合力。
2 解决的思路
2.1 既解决短期矛盾,也立足长远发展
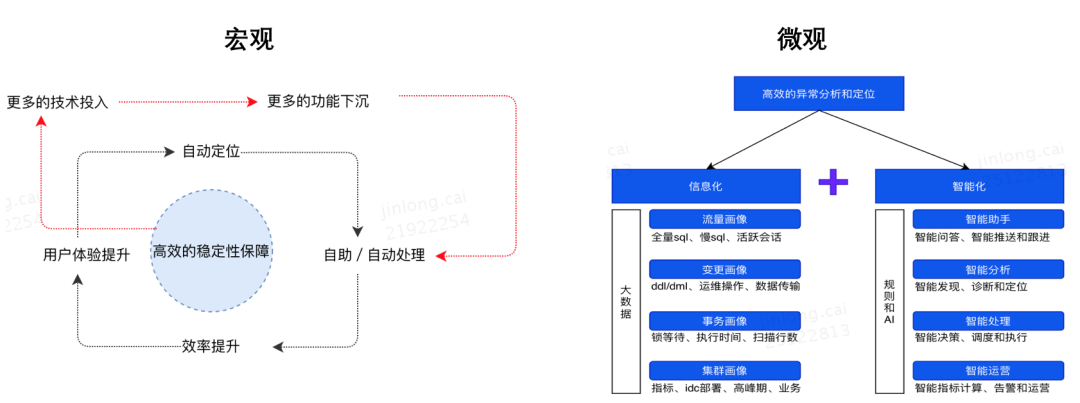
2.2 夯实基础能力,赋能上层业务,实现数据库自治

2.3 建立科学的评估体系,持续的跟踪产品质量
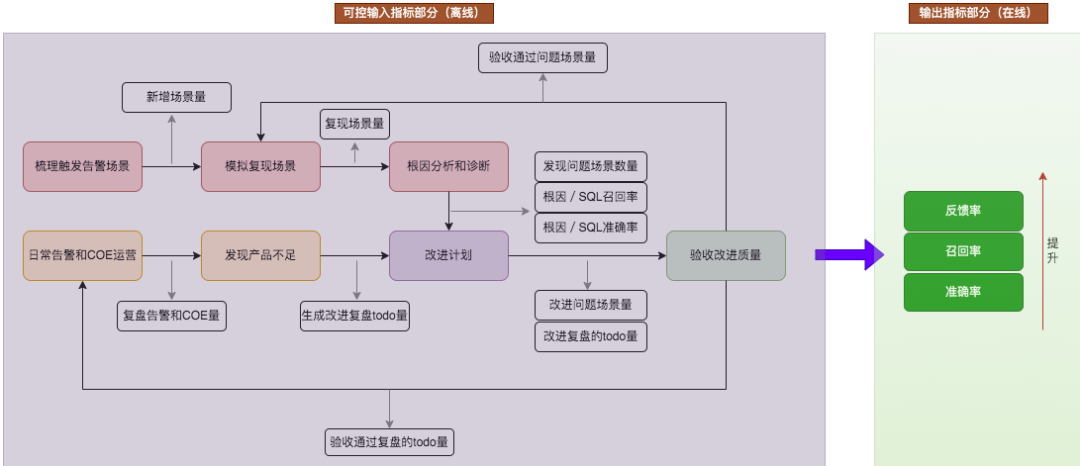

3 技术方案
3.1 技术架构的顶层设计
3.2 数据采集层的设计
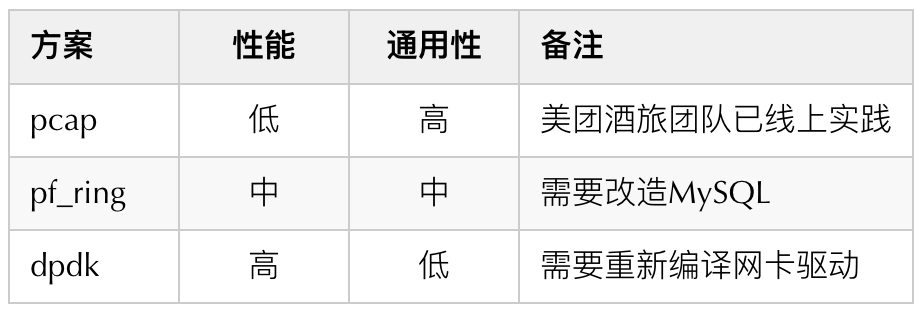
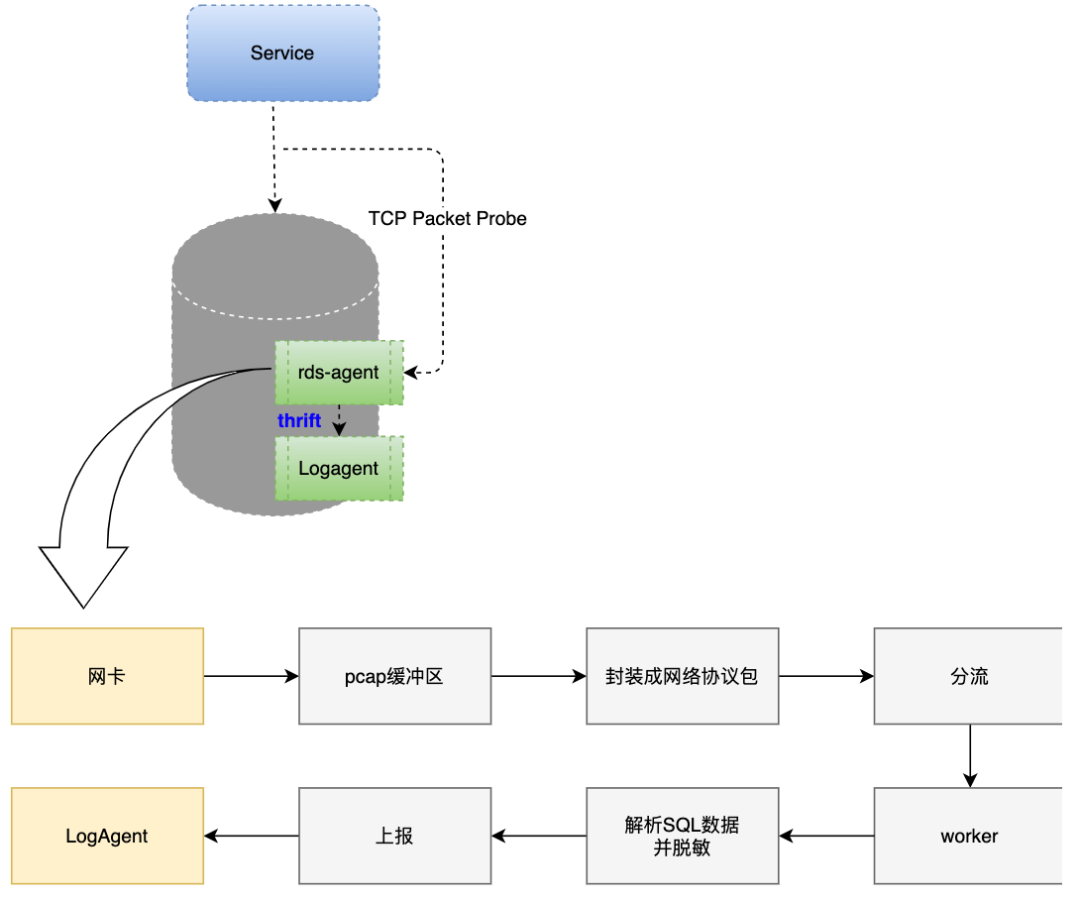

图9 Agent对数据库的影响测试
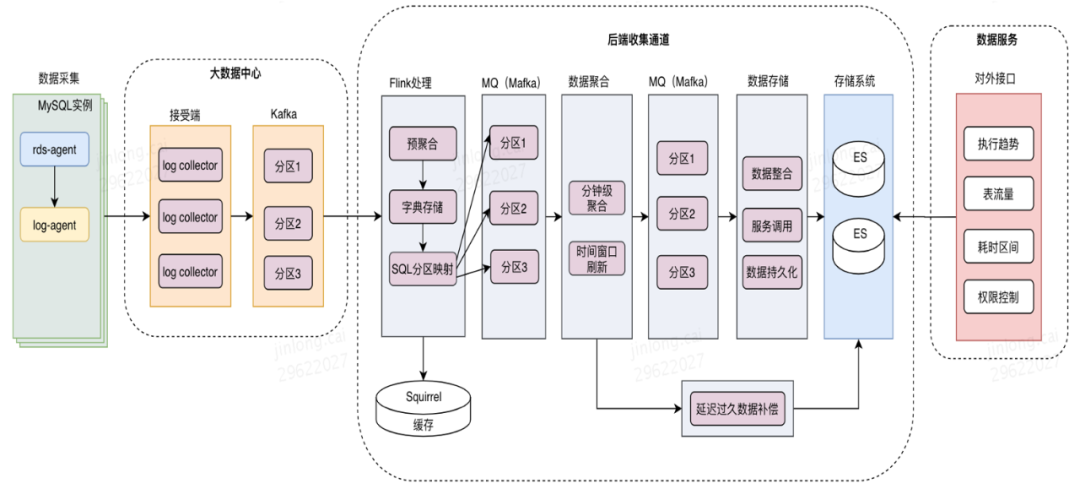
3.3 计算存储层的设计
全内存计算:确保所有的计算都在单线程内或单进程内做纯内存的操作,追求性能跟吞吐量的。
上报原始数据:MySQL实例上报的数据尽量维持原始数据状态,不做或者尽量少做数据加工。
数据压缩:由于上报量巨大,需要保障上报的数据进行的压缩。内存消耗可控:通过理论和实际压测保障几乎不可能会发生内存溢出。
小化对MySQL实例的影响:计算尽量后置,不在Agent上做复杂计算,确保不对RDS实例生产较大影响。以下是具体的架构图:
3.3.1 全量SQL的聚合方式
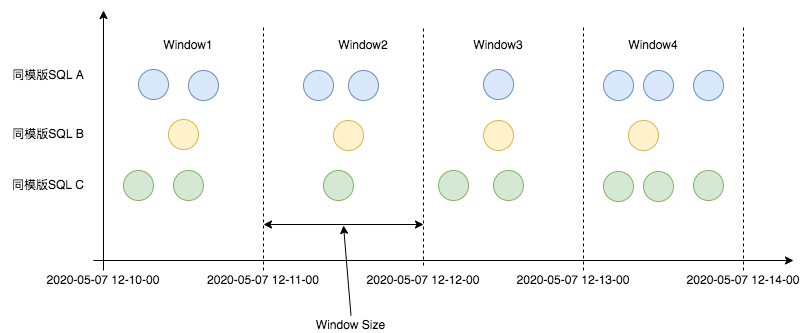
图11 SQL模版聚合设计
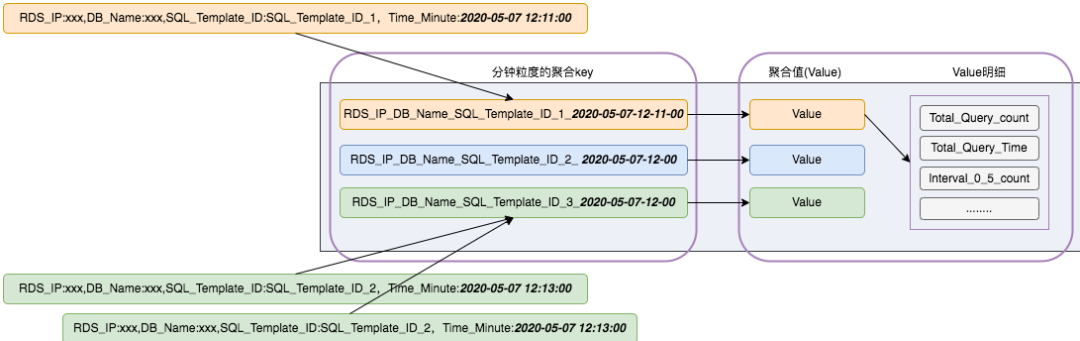
3.3.2 全量SQL数据聚合和压缩的效果

3.3.3 全量SQL数据补偿机制

3.4 分析决策层的设计
阶段:完全以规则为主,积累领域经验,探索可行的路径。
第二阶段:探索AI场景,但以专家经验为主,在少量低频场景上使用AI算法,验证AI能力。
第三阶段:在专家经验和AI上齐头并进,专家经验继续在已有的场景上迭代和延伸,AI在新的场景上进行落地,通过双轨制保证原有能力不退化。
第四阶段:完成AI对大部分专家经验的替换,以AI为主专家经验为辅,发挥AI能力。
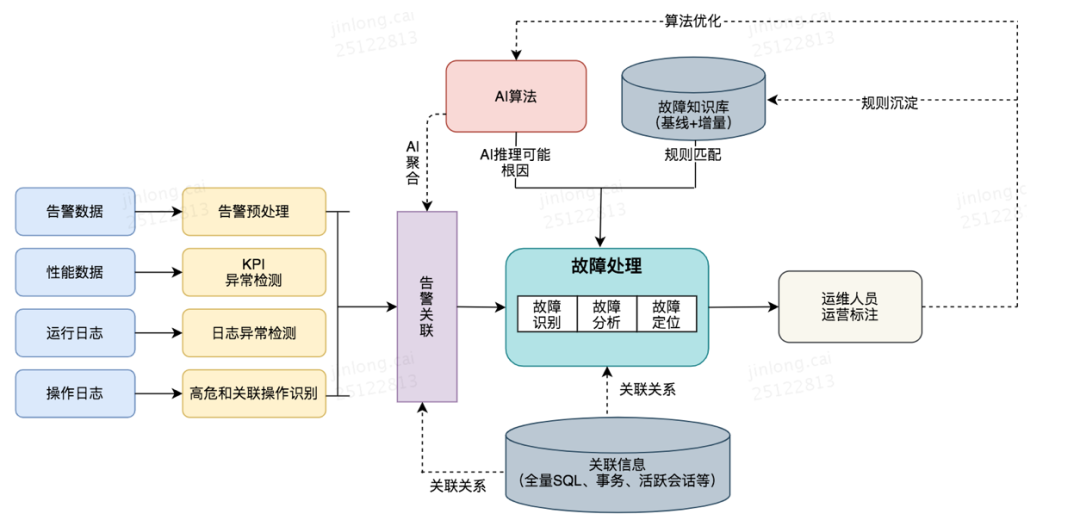
3.4.1 基于规则的方式

3.4.2 基于AI算法的方式


数据采集:采集数据库性能指标、数据库状态抓取、系统指标、硬件问题、日志、记录等数据。
特征提取:从各类数据中提取特征,包括算法提取的时序特征、文本特征以及利用数据库知识提取的领域特征等。
根因分类:包括特征预处理、特征筛选、算法分类、根因排序等部分。
根因扩展:基于根因类别进行相关信息的深入挖掘,提高用户处理问题的效率。具体包括SQL行为分析、专家规则、指标关联、维度下钻、日志分析等功能模块。
4 建设成果


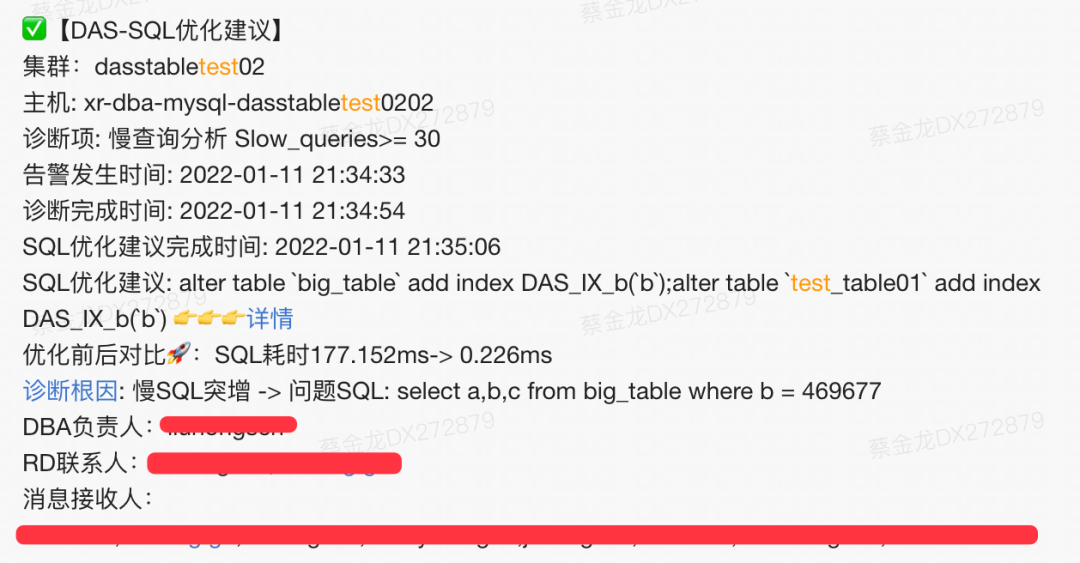
4.2 用户案例


5 总结与未来展望
步:建立根因诊断和SOP文档的关联,将诊断和处理透明化; 第二步:SOP文档平台化,将诊断和处理流程化; 第三步:部分低风险无人干预,将诊断和处理自动化,逐步实现数据库自治。
