гҖҖгҖҖеҲҶеёғејҸжһ¶жһ„жҳҜMdbClusterзҡ„ж ёеҝғе…ій”®пјҢдёҡз•ҢжңүеҫҲеӨҡзӣёе…ізҡ„е®һзҺ°пјҢеҚҙеҫҲе°‘жңүж–Үз« иҜҰз»Ҷзҡ„и§ЈйҮҠжҜҸдёӘжһ¶жһ„е®һзҺ°иғҢеҗҺзҡ„з»ҶиҠӮе’Ңиҝҷд№ҲеҒҡзҡ„еҺҹеӣ гҖӮеңЁMdbClusterж•ҙдёӘз ”еҸ‘е’ҢжөӢиҜ•зҡ„иҝҮзЁӢдёӯпјҢжҲ‘们дёҚж–ӯзҡ„йҒҮеҲ°еҗ„з§Қеҗ„ж ·зҡ„й—®йўҳпјҢеҲҶжһҗй—®йўҳзҡ„еҺҹеӣ пјҢдҝ®ж”№зӣёеә”зҡ„и®ҫи®Ўе’Ңе®һзҺ°пјҢеҶҚеӣһеҪ’жөӢиҜ•гҖӮеҫҲеӨҡеңЁи®ҫи®Ўзҡ„ж—¶еҖҷдёҖдәӣйўҮдёәеҫ—ж„Ҹзҡ„trickпјҢеҚҙйҖ жҲҗжөӢиҜ•ж—¶ж•ҙдёӘзі»з»ҹиҝҗиЎҢзҡ„зҒҫйҡҫгҖӮж— ж•°ж¬Ўзҡ„жҺЁеҲ°йҮҚжқҘиӯҰйҶ’жҲ‘们вҖ”вҖ”еңЁжІЎжңүиҜҰз»Ҷзҡ„жөӢиҜ•ж•°жҚ®ж”Ҝж’‘зҡ„жғ…еҶөдёӢпјҢдёҚиҰҒеңЁи®ҫи®Ўйҳ¶ж®өд»ҘеўһеҠ зі»з»ҹеӨҚжқӮеәҰдёәд»Јд»·жқҘиҝӣиЎҢжҹҗдәӣжғіиұЎзҡ„дјҳеҢ–гҖӮиҷҪ然жҲ‘们дёҖзӣҙзҹҘйҒ“иҝҷжҳҜдёҖжқЎзңҹзҗҶпјҢдҪҶжҖ»жңүеҝҚдёҚдҪҸгҖҒиҮӘдҪңиҒӘжҳҺзҡ„ж—¶еҖҷгҖӮзҺ°е®һжҖ»иғҪдёҖж¬Ўж¬Ўең°е°ҶжҲ‘们жӢүеӣһеҺҹең°вҖ”вҖ”Keep it simple,stupid! жң¬ж–ҮиҜ•еӣҫжҖ»з»“иҝҷдёҖе№ҙжқҘжҲ‘们дәӨзҡ„з»ҸйӘҢзЁҺпјҢжқҘиҜҰз»Ҷйҳҗиҝ°йӮЈдәӣзңӢдјјз®ҖеҚ•жһ¶жһ„и®ҫи®ЎиғҢеҗҺзҡ„еӨҚжқӮз»ҶиҠӮгҖӮ
гҖҖгҖҖжҺҘжҲ‘们дёҠдёҖз« еҚ•иҠӮзӮ№зҡ„жһ¶жһ„еӣҫпјҢдёӨдёӘиҠӮзӮ№зҡ„жһ¶жһ„еӣҫеҰӮдёӢпјҡ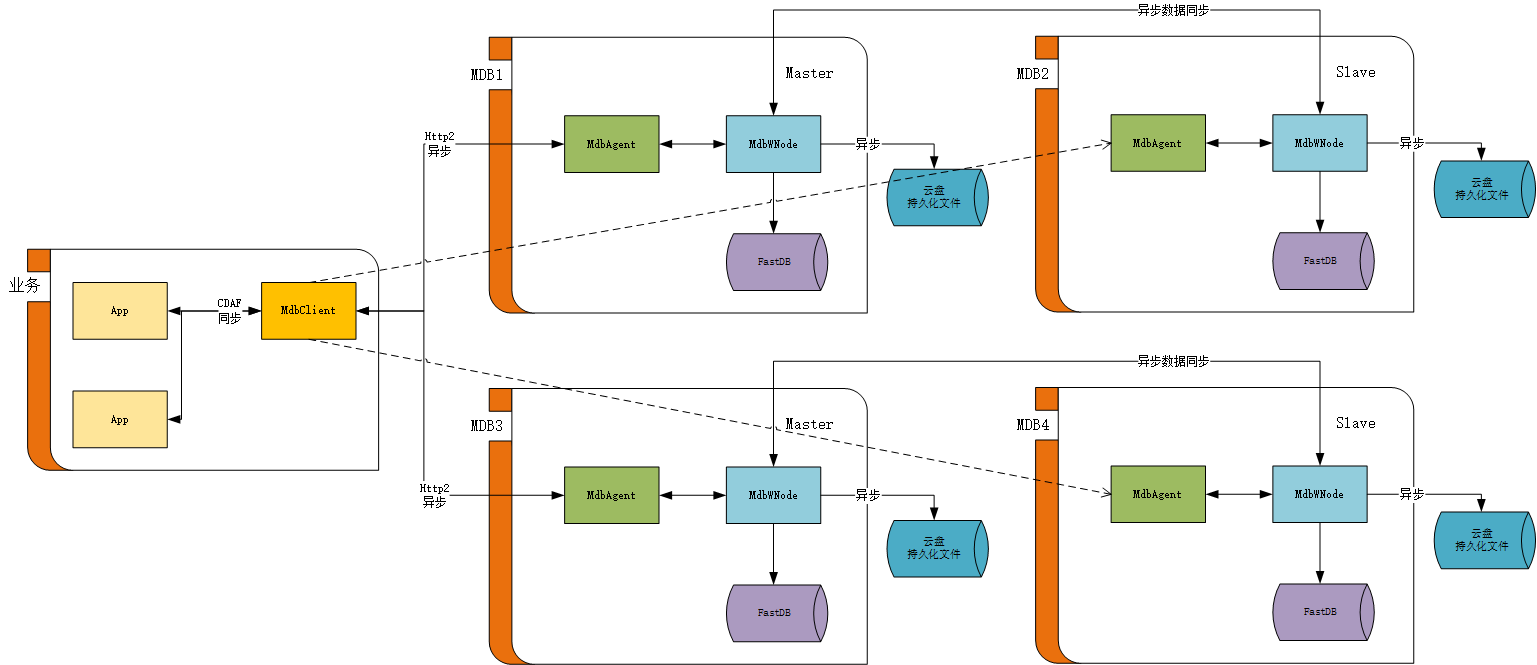
гҖҖгҖҖMdbClientдёҺжҜҸдёӘиҠӮзӮ№зҡ„MdbAgentе»әз«ӢиҝһжҺҘпјҢдҪҶеҸӘдёҺMasterиҠӮзӮ№иҝӣиЎҢдёҡеҠЎйҖҡи®ҜгҖӮиҝҷдёӘжһ¶жһ„жң¬иә«еҫҲз®ҖеҚ•пјҢеҮ д№ҺеҸҜд»Ҙд»Һ1-Nж— йҷҗеӨҚеҲ¶пјҢжҳҜдёҖдёӘе®Ңе…Ёзҡ„еҲҶеёғејҸжһ¶жһ„пјҢж— еҚ•зӮ№ж•…йҡңгҖӮдёӢйқўжҲ‘们йҖҡиҝҮеҒҮи®ҫиҜ»иҖ…зҡ„й—®йўҳпјҢжқҘдёҖжӯҘжӯҘзҡ„д»Ӣз»Қж•ҙдёӘжһ¶жһ„гҖӮ
гҖҖгҖҖ1. ж•°жҚ®жҳҜж №жҚ®д»Җд№Ҳзӯ–з•ҘжқҘиҝӣиЎҢеҲҶзүҮзҡ„?
гҖҖгҖҖ2. ж•ҙдёӘдёҡеҠЎзҡ„дәӨдә’жөҒзЁӢжҳҜжҖҺд№Ҳж ·зҡ„пјҹ
гҖҖгҖҖ3. еҪ“жҹҗдёӘиҠӮзӮ№зҠ¶жҖҒе’Ңж•°йҮҸеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢе…¶е®ғиҠӮзӮ№еҰӮдҪ•ж„ҹзҹҘпјҹ
гҖҖгҖҖ4. жү©е®№е’Ңзј©е®№ж—¶пјҢеҲҶзүҮжҳҜеҰӮдҪ•и°ғж•ҙзҡ„пјҹгҖҖ
гҖҖгҖҖ5. дёҡеҠЎж¶ҲжҒҜжҳҜеҰӮдҪ•ж ЎйӘҢгҖҒй”ҷиҜҜж¶ҲжҒҜеҰӮдҪ•йҮҚе®ҡеҗ‘гҖҒи¶…ж—¶ж¶ҲжҒҜеҰӮдҪ•еӨ„зҗҶпјҹ
гҖҖгҖҖдёҖгҖҒ ж•°жҚ®жҳҜж №жҚ®д»Җд№Ҳзӯ–з•ҘжқҘиҝӣиЎҢеҲҶзүҮзҡ„?
гҖҖгҖҖе…ідәҺMdbClusterзҡ„Shardingзӯ–з•ҘпјҢжҲ‘们зӣҙжҺҘйҮҮз”ЁдәҶRedisзҡ„зӯ–з•ҘгҖӮRedis Cluster йҮҮз”ЁиҷҡжӢҹе“ҲеёҢж§ҪеҲҶеҢәпјҢжүҖжңүзҡ„й”®ж №жҚ®е“ҲеёҢеҮҪж•°жҳ е°„еҲ° 0 ~ 16383 ж•ҙж•°ж§ҪеҶ…пјҢи®Ўз®—е…¬ејҸпјҡslot = CRC16(key) & 16383гҖӮжҜҸдёҖдёӘиҠӮзӮ№иҙҹиҙЈз»ҙжҠӨдёҖйғЁеҲҶж§Ҫд»ҘеҸҠж§ҪжүҖжҳ е°„зҡ„й”®еҖјж•°жҚ®гҖӮ

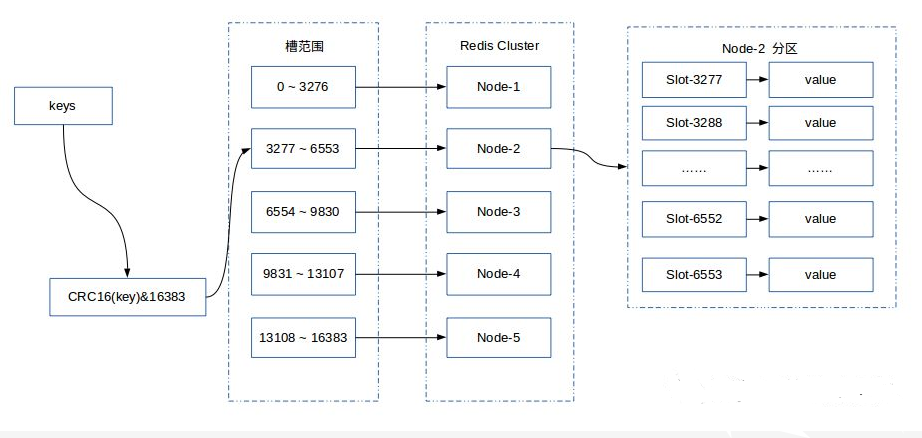
гҖҖгҖҖ
гҖҖгҖҖд»ҺжҲ‘们项зӣ®е®һйҷ…дҪҝз”ЁиҝҮзЁӢпјҢжқҘиҜҙиҜҙиҝҷдёӘеҲҶзүҮ规еҲҷзҡ„еҘҪеӨ„гҖӮ
гҖҖгҖҖ1. йҖҡиҝҮ keys -> slot -> nodeзҡ„жҳ е°„е…ізі»пјҢи§ЈеҶідәҶд»ҺиЎЁзҡ„partitionidеҲ°MdbclusterеҲҶзүҮnodeidзҡ„еҜ№еә”е…ізі»гҖӮ
гҖҖгҖҖ2. дёәд»Җд№ҲдёҚжҳҜkeys->nodeзӣҙжҺҘжҳ е°„пјҹеңЁжү©е®№е’Ңзј©е®№зҡ„иҝҮзЁӢдёӯпјҢиҝҷз§Қи§ЈиҖҰе°ҶеёҰжқҘиҝҒ移зҡ„дҫҝеҲ©гҖӮеҲ©з”ЁдёҠеӣҫдёҫдёӘз®ҖеҚ•дҫӢеӯҗпјҢеҰӮжһңиҰҒе°ҶиҠӮзӮ№д»Һ5дёӘжү©еҲ°10дёӘзҡ„ж—¶еҖҷпјҢдёҠиҝ°еҲҶзүҮзӯ–з•ҘпјҢеҸӘиҰҒе°Ҷnode1зҡ„slot(1638-3276)жҢӘеҲ°node6гҖӮnode2зҡ„slot(4914-6553)жҢӘеҲ°node7гҖӮдҫқжӯӨзұ»жҺЁвҖҰвҖҰеҸӘиҰҒиҝӣиЎҢ5ж¬ЎиҠӮзӮ№й—ҙзҡ„ж•°жҚ®иҝҒ移гҖӮдҪҶеҰӮжһңжҳҜзӣҙжҺҘжҳ е°„пјҢеҲҶзүҮзӯ–з•Ҙд»Һkeys%5->node иҪ¬дёә keys%10->nodeпјҢе°ұдјҡйқўдёҙnode1->(node2, 3, 4, 5, 6, 7, 8, 9,10)йғҪиҰҒжҢӘж•°жҚ®зҡ„еңәжҷҜпјҢжҖ»е…ұйңҖиҰҒиҝҒ移зҡ„ж¬Ўж•°дёә9*5=45гҖӮеҸҚд№ӢпјҢзј©е®№д№ҹдёҖж ·гҖӮ
гҖҖгҖҖ3. дёәд»Җд№Ҳslotзҡ„ж•°йҮҸжҳҜ16384пјҹ 2зҡ„14ж¬Ўж–№гҖӮзҪ‘дёҠжңүеҫҲеӨҡиҜҙжі•пјҢдҪҶжҲ‘们зҡ„з»ҸйӘҢжҳҜпјҡеңЁжү©зј©е®№еҒҡж•°жҚ®иҝҒ移зҡ„ж—¶еҖҷпјҢйңҖиҰҒеҜ№иҝҷдёӘslotзҡ„ж•°жҚ®иҝӣиЎҢеҠ й”ҒгҖӮеҰӮжһңslotж•°йҮҸеӨӘе°‘пјҢй”Ғе®ҡзҡ„ж•°жҚ®йҮҸеӨӘеӨ§пјҢд»ҺиҖҢйҖ жҲҗиҝҒ移иҝҮзЁӢдёӯдёҡеҠЎиҜ·жұӮеӨұиҙҘеӨӘеӨҡгҖӮеҰӮжһңslotж•°йҮҸеӨӘеӨҡпјҢиҝҒ移зҡ„жү№ж¬ЎиҝҮеӨҡпјҢжҜҸж¬ЎиҝҒ移зҡ„ж•°жҚ®жқЎж•°еӨӘе°‘пјҢйҖ жҲҗиҝҒ移жҖ§иғҪеҸ—еҪұе“ҚгҖӮжүҖд»ҘиҝҷдёӘж•°еӯ—зҡ„еӨ§е°Ҹе…¶е®һжҳҜи·ҹдёҡеҠЎжҜҸеј иЎЁзҡ„ж•°жҚ®йҮҸжңүзӣҙжҺҘе…ізі»зҡ„гҖӮ
гҖҖгҖҖдәҢгҖҒж•ҙдёӘдёҡеҠЎзҡ„дәӨдә’жөҒзЁӢжҳҜжҖҺд№Ҳж ·зҡ„пјҹ
гҖҖгҖҖ
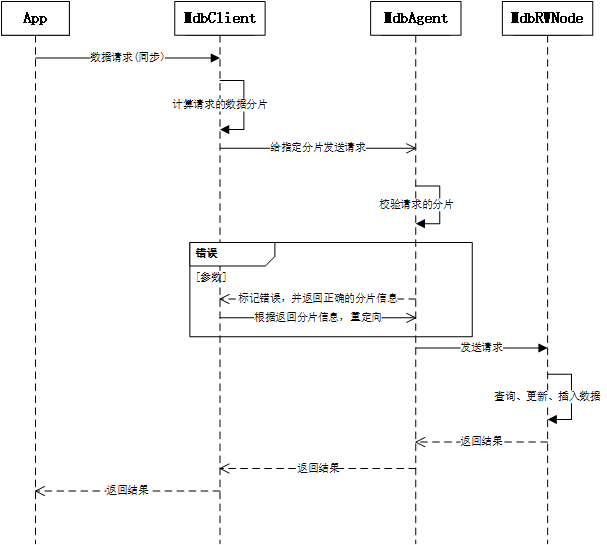

гҖҖгҖҖжңүдёӨзӮ№йңҖиҰҒзү№еҲ«иҜҙжҳҺпјҢжҳҜAppзҡ„й©ұеҠЁеҲ°MdbClientжҳҜеҗҢжӯҘиҜ·жұӮпјҢжңүи¶…ж—¶з®ЎзҗҶгҖӮиҝҷж ·еҒҡзҡ„еҘҪеӨ„жҳҜз®ҖеҢ–дёҡеҠЎйҖ»иҫ‘гҖӮе…¶е®ғзҡ„зҺҜиҠӮеқҮдёәејӮжӯҘж¶ҲжҒҜпјҢдёәдәҶеӨ§еҢ–зҡ„жҸҗй«ҳжҖ§иғҪгҖӮ第дәҢжҳҜMdbClientеҲ°MdbAgentд№Ӣй—ҙе…·еӨҮж¶ҲжҒҜйҮҚе®ҡеҗ‘зҡ„иғҪеҠӣгҖӮиҝҷж ·еҒҡзҡ„еҘҪеӨ„жҳҜпјҢеңЁжү©зј©е®№зҡ„ж—¶еҖҷпјҢеҸҜд»ҘеҮҸе°‘Appдҫ§иҝ”еӣһй”ҷиҜҜж¶ҲжҒҜзҡ„ж•°йҮҸгҖӮ
