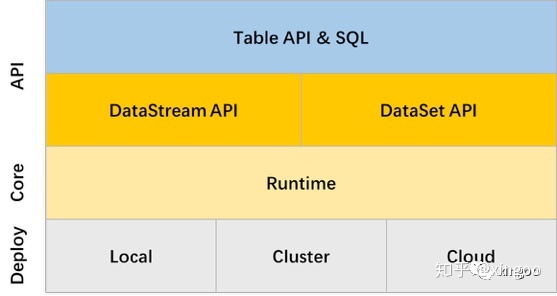
导读
Flink Table & SQL API是在DataStream和DataSet之上封装的一层API。由于DataStream和DataSet有各自的API,开发起来又有些困难,如果只是应对一些相对通用的需求会有点麻烦。而Flink Table & SQL API,通过关系型的API简化了内部的复杂实现。
通过SQL开发人员可以只关注业务逻辑,学习成本低,容易理解,而且内置了很多的优化规则,可以简化开发复杂度,通过SQL还能在高层应用上实现真正的批流一体。
近带着对Flink SQL的无限向往做了一个需求(使用的1.8.2版本),差点没把自己弄哭(期待1.10)。
1 基本使用
Table API 和SQL其实很像,在底层他们其实也都是一回事,因此文档、技术文章通常都会把他们放在一起(稍后会说一下他们的区别)。就目前的版本一般都会Table API和SQL,甚至Dataset、DataStream混用。这里不得不吐槽下,Table API竟然没有print()!!!想要打印的时候需要转成DataSet,再调用print()。
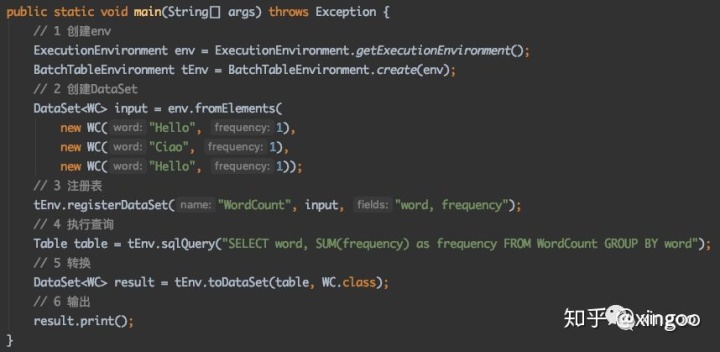
一般在使用的时候需要分别注册Source表 和 Sink表,分别对应数据的输入和输出。对于注册Source表,可以从内部的catalog注册;也可以从TableSource注册;还可以通过DataSet转换注册。对于SInk表,一般就直接通过TableSink注册了。查询时可以通过Table API执行select或者filter之类,也可以通过env.sqlQuery执行查询。写入时可以通过table.insertInto()执行写操作,也可以通过env.sqlUpdate()执行写入。这里还要吐槽下:弄一个sql()自动判断查询和写入不好么,为什么要区分update和insert?
2 SQL原理
Table & SQL API基于scala和java编写,内部基于calcite实现标准sql的解析和校验。跟spark不一样,flink直接基于开源的calcite编写。calcite本身是一个apache的开源项目,它独立于存储和执行,专门负责sql的解析优化、语法树的校验等,并且通过插件的方式可以很方便的扩展优化规则,广泛的应用在hive、solr、flink等中。
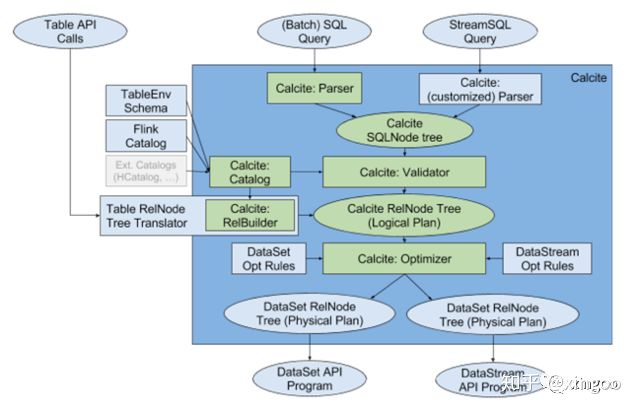
在Flink中通过tableEnv.sqlQuery和tableEnv.sqlUpdate可以看到具体的calcite使用流程。query与update的操作其实内部差不多,都是解析、校验、转换,不过sqlUpdate后会基于内部的Table增加一个insertInto的操作。
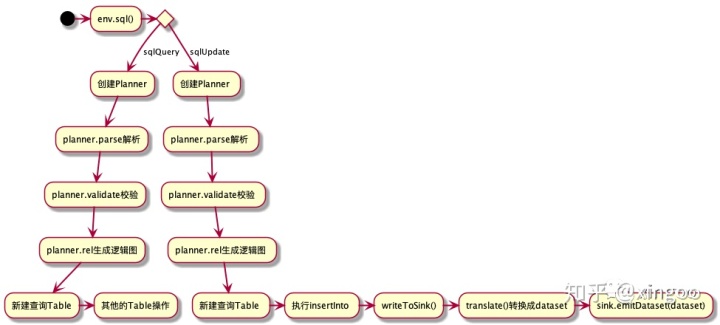
以sqlQuery为例,先来看看整体的流程:
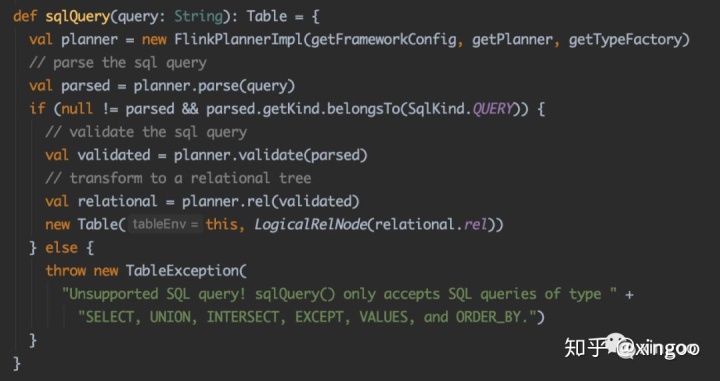
首先创建FlinkPlannerImpl的执行计划,然后调用parse方法,内部直接使用calcite的SqlParser形成语法树。此时的语法树其实是一个个的SqlNode,这个SqlNode是calcite中定义,不同的sql有不同的sqlNode实现。比如常见的SqlSelect,SqlJoin,SqlInsert等。每个类中会有自己的一些组件,比如SqlSelect会有group by, from, where, selectList等等。
获得语法树后,会通过一个简单的校验,判断是否为QUERY或者INSERT。然后经过一个通用的validate校验,粗略的看了下有catalog、表达式等的校验。后通过rel把calcite的SqlNode转换成RelNode即逻辑执行计划。
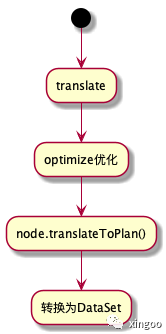
Table后续在使用时会通过translate转换成一个DataSet,内部会先进行优化(优化过程既包括calcite提供的默认优化规则,也有Flink扩展的规则),后生成物理执行计划。物理执行计划会按照node类型的不同将node转换成dataset或datastream的API。

总结来说,Flink SQL通过calcite实现:
解析(字符串SQL转AST抽象语法树)
校验(语法、表达式、表信息)
优化(剪枝、谓词下推)
转换(逻辑计划转换成物理执行计划=Node转换成DataSet\DataStream API)
终把SQL转换成DataSet或DataStream的API。
3 案例分析
以WordCount为例,为了增加sql的复杂度,在外层增加了filter:
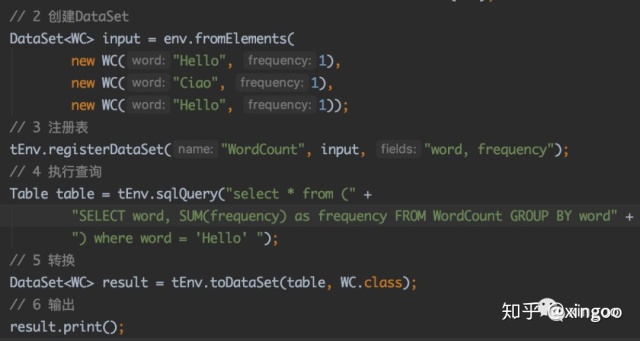
使用System.out.println(tEnv.explain(table));可以输出执行计划:
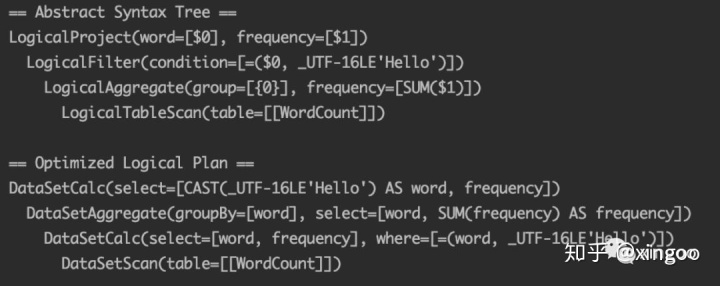
通过parse方法获得到抽象语法树,显示一个filter节点,然后跟着Agg和scan。经过优化后,查询条件优化到底层。后转换生成真正的物理执行计划。
后续会继续研究下calcite以及optimize部分,到时再做分享。
参考:
https://matt33.com/2019/03/07/apache-calcite-process-flow/https://matt33.com/2019/03/17/apache-calcite-planner/https://blog.csdn.net/super_wj0820/article/details/95623380