行格式(row format)决定了我们插入的一行数据,是如何存储在数据库中的,MySQL有4种行格式,分别是REDUNDANT,COMPACT,DYNAMIC,COMPRESSED。
不同行格式区别:
| 行格式 | 紧凑存储 | 增强可变长度列存储 | 大索引键前缀 | 压缩支持 | 支持的表空间类型 | 所需文件格式 |
|---|---|---|---|---|---|---|
| REDUNDANT | 否 | 否 | 否 | 否 | system, file-per-table, general | Antelope or Barracuda |
| COMPACT | 是 | 否 | 否 | 否 | system, file-per-table, general | Antelope or Barracuda |
| DYNAMIC | 是 | 是 | 是 | 否 | system, file-per-table, general | Barracuda |
| COMPRESSED | 是 | 是 | 是 | 是 | file-per-table, general | Barracuda |
MySQL 5.7默认使用的是Dynamic的行格式。
我们可以在创建表的时候指定字符集和行格式。
字符集表示我们插入的字符是用几个字节编码的,比如ASCII用一个字节,GB2312用2个字节,utf8使用3个字节,utf8mb4用4个字节(如果存储emoj表情就要用这个字符集)
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`price` int(11) NOT NULL,
`code` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=Dynamic;
在讲下面行格式的时候,我们使用这个表进行讲解
CREATE TABLE record_format_demo (
c1 VARCHAR(10),
c2 VARCHAR(10) NOT NULL,
c3 CHAR(10),
c4 VARCHAR(10)
) CHARSET=ascii ROW_FORMAT=Redundant;
INSERT INTO record_format_demo(c1, c2, c3, c4) VALUES
('aaaa', 'bbb', 'cc', 'd'),
('eeee', 'fff', NULL, NULL);
Redundant行格式
Redundant行格式是一个比较老的行格式了,现在也就只有MySQL的一些系统表会使用它了,平常咱们一般不用,但是这个行格式我觉得是能搞明白其他行格式的基础。
行格式结构
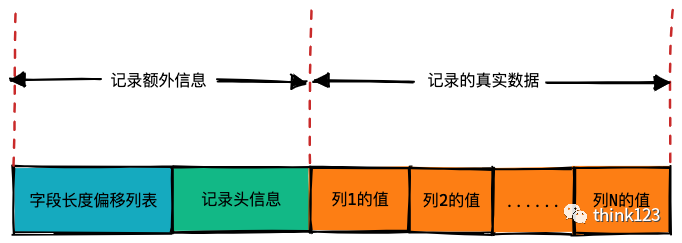
如上图所示,整个行格式分为记录的额外信息和记录的真实数据两部分,其中记录的额外信息又分为字段长度偏移列表和记录头信息两部分。
字段长度偏移列表
在Redundant行格式中,会把所有字段的真实数据占⽤的字节长度都存放在记录的开头部位,从⽽形成⼀个字段长度偏移列表,字段长度占⽤的字节数按照列的顺序逆序存放,逆序存放,逆序存放!
记录头信息 Redundant⾏格式的记录头信息占⽤6字节,48个⼆进制位,这些⼆进制位代表的意思如下
| 名称 | 大小(bit) | 描述 |
|---|---|---|
| 预留位1 | 1 | 未使用 |
| 预留位2 | 1 | 未使用 |
| delete_mask | 1 | 该记录是否删除 |
| min_rec_mask | 1 | B+树每层非叶子节点小记录都会添加该标记 |
| n_owned | 4 | 当前记录组拥有记录数 |
| heap_no | 13 | 当前记录在页面堆位置信息 |
| n_field | 10 | 记录中列数量 |
| 1byte_offs_flag | 1 | 字段长度偏移列表中每个列对应的偏移量是使⽤1字节还是2字节表⽰的 |
| next_record | 16 | 下一条记录的相对位置 |
真实数据
对于record_format_demo表来说,记录的真实数据除了c1、c2、c3、c4这⼏个我们⾃⼰定义的列的数据以外,MySQL会为每个记录默认的添加⼀些列(也称为隐藏列),具体的列如下
DB_ROW_ID(row_id) : 当表没有定义主键,则选择unique键作为主键,如果仍没有,则默认添加一个名为DB_ROW_ID的隐藏列作为主键,占用6个字节。也就是说这个列只有当没有主键也没有索引时才存在 DB_TRX_ID(transaction_id): 事务id,占用6字节 DB_ROLL_PTR(roll_pointer): 占用7个字节,回滚指针(后面MVCC的时候会用到)
所以,对我们的数据来讲,其行格式数据如下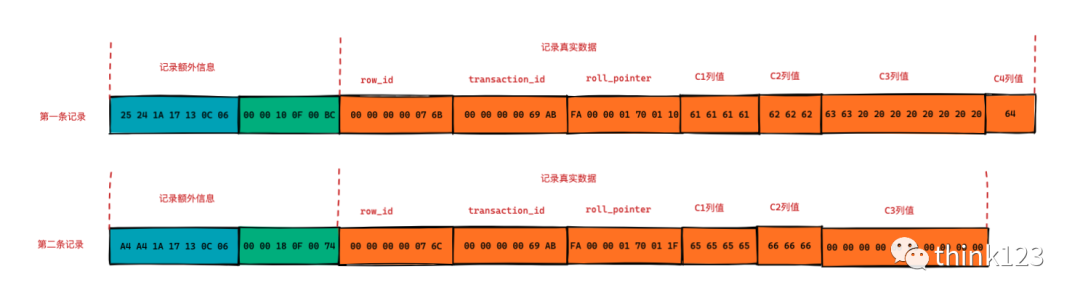
列长度如何计算
⽐如第⼀条记录的字段⻓度偏移列表就是:
25 24 1A 17 13 0C 06
因为它是逆序排放的,所以按照列的顺序排列就是:
06 0C 13 17 1A 24 25
计算各个列长度则按照以下方法(字符集是ascii,一个字符占用1个字节):第⼀列(row_id)的⻓度就是 0x06个字节,也就是6个字节。
第⼆列(transaction_id)的⻓度就是 (0x0C - 0x06)个字节,也就是6个字节。
第三列(roll_pointer)的⻓度就是 (0x13 - 0x0C)个字节,也就是7个字节。第四列(c1)的⻓度就是 (0x17 - 0x13)个字节,也就是4个字节。
第五列(c2)的⻓度就是 (0x1A - 0x17)个字节,也就是3个字节。
第六列(c3)的⻓度就是 (0x24 - 0x1A)个字节,也就是10个字节。
第七列(c4)的⻓度就是 (0x25 - 0x24)个字节,也就是1个字节。
在记录头信息中的1byte_offs_flag用于表示 字段长度偏移列表中每个列对应的偏移量是使⽤1字节还是2字节表⽰的 ,这个值是如何计算的呢?
当记录的真实数据占⽤的字节数不⼤于127(⼗六进制0x7F,⼆进制01111111)时,每个列对应的偏移量占⽤1个字节。 当记录的真实数据占⽤的字节数⼤于127,但不⼤于32767(⼗六进制0x7FFF,⼆进制0111111111111111)时,每个列对应的偏移量占⽤2个字节。 当记录大于32767的时候,此时的记录已经存放到了溢出页中,在本页中只保留前768个字节和20个字节的溢出页⾯地址(当然这20个字节中还记录了⼀些别的信息)。因为字段⻓度偏移列表处只需要记录每个列在本页⾯中的偏移就好了,所以每个列使⽤2个字节来存储偏移量就够了。
我们的条记录真实数据总长度 = 37(6+6+7+4+3+10+1),小于127,所以采用1字节记录偏移量。
为了在解析记录的时候知道列偏移量是采用1字节还是2字节表示,因此使用1byte_offs_flag来决定,当它的值为1时,表明使用1个字节存储,当值为0时,表明使用2字节存储。
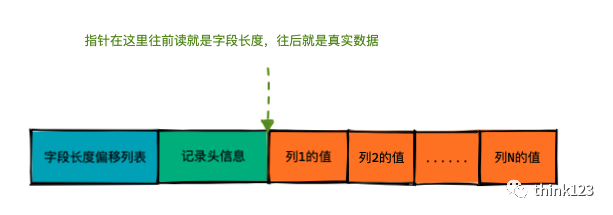
需要注意下记录头信息的next_record,你可以把它理解为指针,通过它我们可以指向下一条记录的位置(多条记录是如何连接的会在下一篇文章讲到哈),当我们指针在这个位置的时候往后读是真实数据的位置,往前读就是字段的长度列表,所以我们长度列表逆序存放就能和真实数据一一对应。
Redundant行格式对NULL值的处理
列对应偏移量值的个比特位作为列值是否为NULL的依据,当解析一条记录某个列时,首先查看这个比特位的值是否为1,如果是1,那么该列的值就是NULL,否则则不是NULL。(现在你知道为什么记录数据长度为什么会有127和32767这两个临界点了吧)
这个bit位也可以称为NULL比特位
对于值为NULL的列,如果是定长类型,NULL值也将占用记录的真实数据部分,数据采用0x00字节填充。如果是变长数据类型,则不在记录的真实数据处占用任何存储空间。
如上图我们的第二条数据, C3列的值是NULL,类型是CHAR(10),占⽤记录的真实数据部分10字节(,所以我们看到在Redundant⾏格式中使⽤0x00000000000000000000来表⽰NULL值。
C3列长度偏移量是0xA4,二进制是 10100100,高位是1,表明该列值是NULL,将高位去掉变成 0100100(十进制的36), C2列对应偏移量是0x1A(十进制的26),因此其长度是36-26=10
C4列是Varchar类型,对应偏移量是0xA4,C3列偏移量也是0XA4,表明其长度是0(不占用真实数据存储空间),而其二进制高位是1,表明该列值是NULL。
为什么定长类型NULL值也要占用固定空间呢?官方文档告诉我对于一个固定长度的列,该列的固定长度被保留在记录的数据部分。为NULL值保留的固定空间允许列从NULL值更新到非NULL值,而不会引起索引页的碎片化。
Compact行格式
Compact行格式是Dynamic和Compressed两种行格式的基础,了解了它就了解了其他两种结构
行格式结构
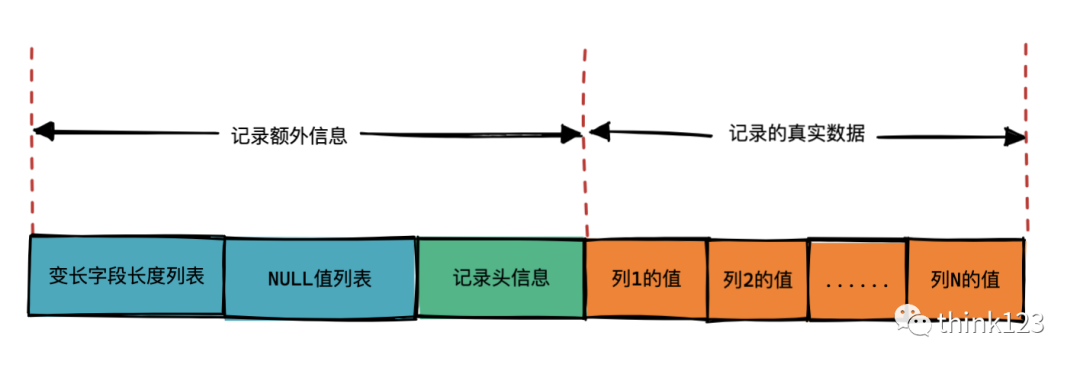
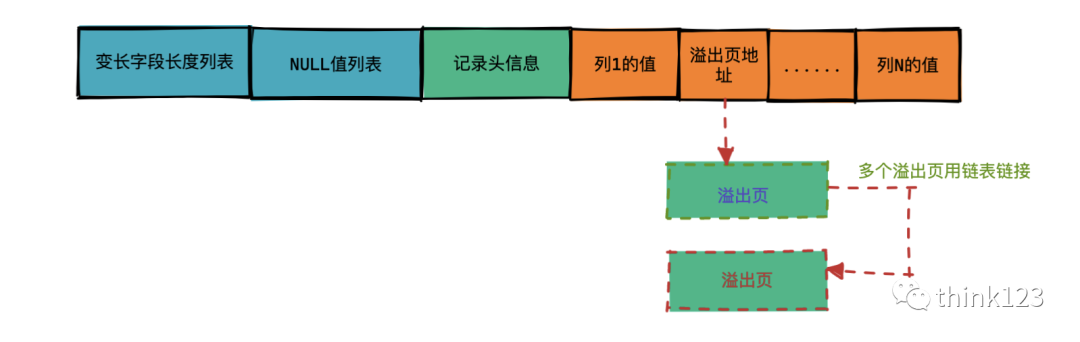
如上图,Compact行格式中记录额外信息分为变长字段长度列表,NULL值列表,记录头信息。
变长字段列表中存储的是非空的变长字段的数据长度,变长字段存储的数据是不固定的,所以我们需要将数据占用的字节数也存起来。同样的,这里占用的长度也是逆序存放,逆序存放,逆序存放的。
varchar(M),VARBINARY(M),各种TEXT以及各种BLOB类型,mysql把拥有这些数据类型的列称为变长字段
对NULL值的处理
Redundant是将列对应偏移量值的个比特位作为列值是否为NULL的依据,但是在Compact中是单独有一个NULL值列表来存储值为NULL的字段。NULL值列表是如何确认的呢?
首先统计表接口中允许为NULL值的列(主键和unique key是不允许为NULL的) 如果表中没有允许存储 NULL 的列,则 NULL值列表 也不存在了,否则将每个允许存储NULL的列对应⼀个⼆进制位,⼆进制位按照列的顺序逆序排列,逆序排列,逆序排列
⼆进制位的值为1时,代表该列的值为NULL。 ⼆进制位的值为0时,代表该列的值不为NULL。
MySQL规定NULL值列表必须⽤整数个字节的位表⽰,如果使⽤的⼆进制位个数不是整数个字节,则在字节的⾼位补0。
如果一个表中有9个允许为NULL的列,那么就需要用2个字节表示
对于我们上面的两条数据来说(c1,c3,c4允许为NULL)
('aaaa', 'bbb', 'cc', 'd'),
('eeee', 'fff', NULL, NULL);
条数据NULL值列表为 00000000(都不为空) 第二条数据NULL值列表为 00000110,c1不为null,所以是0,c3为null,所以是1,c4是null,所以是1,其倒序结果就是00000110
记录头
和Redundant不同,Compact的记录头信息使用了5个字节(40bit)来表示记录头信息,其具体信息如下
| 名称 | 大小(bit) | 描述 |
|---|---|---|
| 预留位1 | 1 | 未使用 |
| 预留位2 | 1 | 未使用 |
| delete_mask | 1 | 该记录是否删除 |
| min_rec_mask | 1 | B+树每层非叶子节点小记录都会添加该标记 |
| n_owned | 4 | 当前记录组拥有记录数 |
| heap_no | 13 | 当前记录在页面堆位置信息 |
| record_type | 3 | 表⽰当前记录的类型,0表⽰普通记录,1表⽰B+树⾮叶⼦节点记录,2表⽰⼩记录,3表⽰⼤记录 |
| next_record | 16 | 下一条记录的相对位置 |
可以看到相比Redundant,Compact多了一个record_type的字段,少了n_field和1byte_offs_flag两个字段。
我们之前提到过 1byte_offs_flag 是用来表示 字段长度偏移列表中每个列对应的偏移量是使⽤1字节还是2字节表⽰的, 但是Compact却没有,那变长字段长度列表中字段长度到底是用1个字节表示还是2个字节表示呢?
列长度如何计算
还记得Redundant将列对应偏移量值的个比特位作为列值是否为NULL的依据吗?Compact思路也是类似的,它使用字节的位来表示.
假设某个字符集中表⽰⼀个字符多需要使⽤的字节数为W,也就是使⽤SHOW CHARSET语句的结果中的Maxlen列,⽐⽅说utf8字符集中的W就是3,gbk字符集中的W就是2,ascii字符集中的W就是1。 对于变长类型VARCHAR(M)来说,这种类型表⽰能存储多M个字符(注意是字符不是字节),所以这个类型能表⽰的字符串多占⽤的字节数就是M×W。 假设它实际存储的字符串占⽤的字节数是L。所以确定使⽤1个字节还是2个字节表⽰真正字符串占⽤的字节数的规则就是这样:
如果M×W <= 255,那么使⽤1个字节来表⽰真正字符串占⽤的字节数。也就是说InnoDB在读记录的变长字段长度列表时先查看表结构,如果某个变长字段允许存储的⼤字节数不⼤于255时,可以认为只使⽤1个字节来表⽰真正字符串占⽤的字节数。 如果M×W > 255,则分为两种情况: 如果L <= 127,则⽤1个字节来表⽰真正字符串占⽤的字节数。 -
如果L > 127,则⽤2个字节来表⽰真正字符串占⽤的字节数。 InnoDB在读记录的变长字段长度列表时先查看表结构,如果某个变长字段允许存储的⼤字节数⼤于255时,该怎么区分它正在读的某个字节是⼀个单独的字段长度还是半个字段长度 呢? 该字节的第⼀个⼆进制位作为标志位:如果该字节的第⼀个位为0,那该字节就是⼀个单独的字段长度(使⽤⼀个字节表⽰不⼤于127(01111111)的⼆进制的第⼀个位都 为0),如果该字节的第⼀个位为1,那该字节就是半个字段长度。 对于⼀些占⽤字节数⾮常多的字段,⽐⽅说某个字段长度⼤于了16KB,那么如果该记录在单个页⾯中⽆法存储 时,InnoDB会把⼀部分数据存放到所谓的溢出页中,在变长字段长度列表处只存储留在本页⾯中的长度,所以使⽤两个字节也可以存放下来。 总结⼀下就是说:如果该可变字段允许存储的⼤字节数(M×W)超过255字节并且真实存储的字节数(L)超过127字节,则使⽤2个字节,否则使⽤1个字节。
上面的内容参考了小孩子大佬的<<MySQL是怎样运行的:从根儿上理解MYSQL>>,大家可以在掘金购买它的小册或者对应的实体书。他是从Compact讲到Redundant的,但是我觉得从Redundant的格式到Compact 格式其实更容易理解,过度更容易。这也是我的一个理解,供大家参考。
行溢出
在Compact和Reduntant⾏格式中,对于占⽤存储空间⾮常⼤的列,在记录的真实数据处只会存储该列的⼀部分数据,把剩余的数据分散存储在⼏个其他的页中,然后记录的真实数据处⽤20个字节存储指向这些页的地址(当然这20个字节中还包括这些分散在其他页⾯中的数据的占⽤的字节数),从⽽可以找到剩余数据所在的页。
对于Compact和Reduntant⾏格式来说,如果某⼀列中的数据⾮常多的话,在本记录的真实数据处只会存储该列的前768个字节的数据和⼀个指向其他页的地址(如果一个页都放不下,那么就会使用链表将多个页链接起来),然后把剩下的数据存放 到其他页中,这个过程也叫做⾏溢出,存储超出768字节的那些页⾯也被称为溢出⻚。
需要注意的是并不仅仅只有变长字段的列才会发生行溢出,blob,text都有可能,甚至大于或等于768字节的固定长度的列也会被编码为可变长度的列,它可以被存储在页面外。例如,如果字符集的大字节长度大于3,一个CHAR(255)列可以超过768字节,正如utf8mb4那样。
Dynamic和Compressed⾏格式
Dynamic和Compressed⾏格式,现在使⽤的MySQL版本是5.7,它的默认⾏格式就是Dynamic,这俩⾏格式和Compact⾏格式挺像,只不过在处理⾏溢出数据时有点⼉分歧。
它们不会在记录的真实数据处存储字段真实数据的前768个字节,⽽是把所有的字节都存储到其他页⾯中,只在记录的真实数据处存储其他页⾯的地
参考文档
<<MySQL是怎样运行的:从根儿上理解MYSQL>> 官方文档: https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html 官方文档: https://dev.mysql.com/doc/internals/en/innodb-field-contents.html
原文链接:https://mp.weixin.qq.com/s/NFgV4gYcIqVglDeWB8mejA
