Table Partition
什么是 Table Partition
Table Partition 是指根据一定规则,将数据库中的一张表分解成多个更小的容易管理的部分。从逻辑上看只有一张表,但是底层却是由多个物理分区组成。相信对有关系型数据库使用背景的用户来说可能并不陌生。
TiDB 正在支持分区表这一特性。在 TiDB 中分区表是一个独立的逻辑表,但是底层由多个物理子表组成。物理子表其实就是普通的表,数据按照一定的规则划分到不同的物理子表类内。程序读写的时候操作的还是逻辑表名字,TiDB 服务器自动去操作分区的数据。
分区表有什么好处?
优化器可以使用分区信息做分区裁剪。在语句中包含分区条件时,可以只扫描一个或多个分区表来提高查询效率。
方便地进行数据生命周期管理。通过创建、删除分区、将过期的数据进行 高效的归档,比使用 Delete 语句删除数据更加优雅,打散写入热点,将一个表的写入分散到多个物理表,使得负载分散开,对于存在 Sequence 类型数据的表来说(比如 Auto Increament ID 或者是 create time 这类的索引)可以显著地提升写入吞吐。
分区表的限制
TiDB 默认一个表多只能有 1024 个分区 ,默认是不区分表名大小写的。
Range, List, Hash 分区要求分区键必须是 INT 类型,或者通过表达式返回 INT 类型。但 Key 分区的时候,可以使用其他类型的列(BLOB,TEXT 类型除外)作为分区键。
如果分区字段中有主键或者索引的列,那么有主键列和索引的列都必须包含进来。
TiDB 的分区适用于一个表的所有数据和索引。不能只对表数据分区而不对索引分区,也不能只对索引分区而不对表数据分区,也不能只对表的一部分数据分区。
常见分区表的类型
Range 分区:按照分区表达式的范围来划分分区。通常用于对分区键需要按照范围的查询,分区表达式可以为列名或者表达式 ,下面的 employees 表当中 p0, p1, p2, p3 表示 Range 的访问分别是 (min, 1991), [1991, 1996), [1996, 2001), [2001, max) 这样一个范围。
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), separated DATE NOT NULL ) PARTITION BY RANGE ( YEAR(separated) ) ( PARTITION p0 VALUES LESS THAN (1991), PARTITION p1 VALUES LESS THAN (1996), PARTITION p2 VALUES LESS THAN (2001), PARTITION p3 VALUES LESS THAN MAXVALUE );List 分区:按照 List 中的值分区,主要用于枚举类型,与 Range 分区的区别在于 Range 分区的区间范围值是连续的。
Hash 分区:Hash 分区需要指定分区键和分区个数。通过 Hash 的分区表达式计算得到一个 INT 类型的结果,这个结果再跟分区个数取模得到具体这行数据属于那个分区。通常用于给定分区键的点查询,Hash 分区主要用来分散热点读,确保数据在预先确定个数的分区中尽可能平均分布。
Key 分区:类似 Hash 分区,Hash 分区允许使用用户自定义的表达式,但 Key 分区不允许使用用户自定义的表达式。Hash 仅支持整数分区,而 Key 分区支持除了 Blob 和 Text 的其他类型的列作为分区键。
TiDB Table Partition 的实现
本文接下来按照 TiDB 源码的 release-2.1 分支讲解,部分讲解会在 source-code 分支代码,目前只支持 Range 分区所以这里只介绍 Range 类型分区 Table Partition 的源码实现,包括 create table、select 、add partition、insert 、drop partition 这五种语句。
create table
create table 会重点讲构建 Partition 的这部分,更详细的可以看 TiDB 源码阅读系列文章(十七)DDL 源码解析,当用户执行创建分区表的SQL语句,语法解析(Parser)阶段会把 SQL 语句中 Partition 相关信息转换成 ast.PartitionOptions,下文会介绍。接下来会做一系列 Check,分区名在当前的分区表中是否、是否分区 Range 的值保持递增、如果分区键构成为表达式检查表达式里面是否是允许的函数、检查分区键必须是 INT 类型,或者通过表达式返回 INT 类型、检查分区键是否符合一些约束。
解释下分区键,在分区表中用于计算这一行数据属于哪一个分区的列的集合叫做分区键。分区键构成可能是一个字段或多个字段也可以是表达式。
// PartitionOptions specifies the partition options.
type PartitionOptions struct {
Tp model.PartitionType
Expr ExprNode
ColumnNames []*ColumnName
Definitions []*PartitionDefinition
}
// PartitionDefinition defines a single partition.
type PartitionDefinition struct {
Name model.CIStr
LessThan []ExprNode
MaxValue bool
Comment string
}
PartitionOptions 结构中 Tp 字段表示分区类型,Expr 字段表示分区键,ColumnNames 字段表示 Columns 分区,这种类型分区又分为 Range columns 分区和 List columns 分区,这种分区目前先不展开介绍。PartitionDefinition 其中 Name 字段表示分区名,LessThan 表示分区 Range 值,MaxValue 字段表示 Range 值是否为大值,Comment 字段表示分区的描述。
CreateTable Partition 部分主要流程如下:
把上文提到语法解析阶段会把 SQL语句中 Partition 相关信息转换成
ast.PartitionOptions, 然后 buildTablePartitionInfo 负责把PartitionOptions结构转换PartitionInfo, 即 Partition 的元信息。checkPartitionNameUnique 检查分区名是否重复,分表名是不区分大小写的。
对于每一分区 Range 值进行 Check,checkAddPartitionValue 就是检查新增的 Partition 的 Range 需要比之前所有 Partition 的 Range 都更大。
TiDB 单表多只能有 1024 个分区 ,超过大分区的限制不会创建成功。
如果分区键构成是一个包含函数的表达式需要检查表达式里面是否是允许的函数 checkPartitionFuncValid。
检查分区键必须是 INT 类型,或者通过表达式返回 INT 类型,同时检查分区键中的字段在表中是否存在 checkPartitionFuncType。
如果分区字段中有主键或者索引的列,那么多有主键列和索引列都必须包含进来。即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列 checkRangePartitioningKeysConstraints。
通过以上对
PartitionInfo的一系列 check 主要流程就讲完了,需要注意的是我们没有对PartitionInfo的元数据持久化单独存储而是附加在 TableInfo Partition 中。
add partition
add partition 首先需要从 SQL 中解析出来 Partition 的元信息,然后对当前添加的分区会有一些 Check 和限制,主要检查是否是分区表、分区名是已存在、大分区数限制、是否 Range 值保持递增,后把 Partition 的元信息 PartitionInfo 追加到 Table 的元信息 TableInfo中,具体如下:
检查是否是分区表,若不是分区表则报错提示。
用户的 SQL 语句被解析成将 ast.PartitionDefinition 然后 buildPartitionInfo 做的事就是保存表原来已存在的分区信息例如分区类型,分区键,分区具体信息,每个新分区分配一个独立的 PartitionID。
TiDB 默认一个表多只能有 1024 个分区,超过大分区的限制会报错。
对于每新增一个分区需要检查 Range 值进行 Check,checkAddPartitionValue 简单说就是检查新增的 Partition 的 Range 需要比之前所有 Partition 的 Range 都更大。
checkPartitionNameUnique 检查分区名是否重复,分表名是不区分大小写的。
后把 Partition 的元信息 PartitionInfo 追加到 Table 的元信息 TableInfo.Partition 中,具体实现在这里 updatePartitionInfo。
drop partition
drop partition 和 drop table 类似,只不过需要先找到对应的 Partition ID,然后删除对应的数据,以及修改对应 Table 的 Partition 元信息,两者区别是如果是 drop table 则删除整个表数据和表的 TableInfo 元信息,如果是 drop partition 则需删除对应分区数据和 TableInfo 中的 Partition 元信息,删除分区之前会有一些 Check 具体如下:
只能对分区表做 drop partition 操作,若不是分区表则报错提示。
checkDropTablePartition 检查删除的分区是否存在,TiDB 默认是不能删除所有分区,如果想删除后一个分区,要用 drop table 代替。
removePartitionInfo 会把要删除的分区从 Partition 元信息删除掉,删除前会做checkDropTablePartition 的检查。
对分区表数据则需要拿到 PartitionID 根据插入数据时候的编码规则构造出 StartKey 和 EndKey 便能包含对应分区 Range 内所有的数据,然后把这个范围内的数据删除,点击查看 具体代码实现。
编码规则:
Key:
tablePrefix_rowPrefix_partitionID_rowIDstartKey:
tablePrefix_rowPrefix_partitionIDendKey:
tablePrefix_rowPrefix_partitionID + 1删除了分区,同时也将删除该分区中的所有数据。如果删除了分区导致分区不能覆盖所有值,那么插入数据的时候会报错。
Select 语句
Select 语句重点讲 Select Partition 如何查询的和分区裁剪(Partition Pruning),更详细的可以看 TiDB 源码阅读系列文章(六)Select 语句概览 。
一条 SQL 语句的处理流程,从 Client 接收数据,MySQL 协议解析和转换,SQL 语法解析,逻辑查询计划和物理查询计划执行,到后返回结果。那么对于分区表是如何查询表里的数据的,其实主要的修改是 逻辑查询计划 阶段,举个例子:如果用上文中 employees 表作查询, 在 SQL 语句的处理流程前几个阶段没什么不同,但是在逻辑查询计划阶段,rewriteDataSource 将 DataSource 重写了变成 Union All 。每个 Partition id 对应一个 Table Reader。
select * from employees
等价于:
select * from (union all
select * from p0 where id < 1991
select * from p1 where id < 1996
select * from p2 where id < 2001
select * from p3 where id < MAXVALUE)
通过观察 EXPLAIN 的结果可以证实上面的例子,如图 1,终物理执行计划中有四个 Table Reader 因为 employees 表中有四个分区,Table Reader 表示在 TiDB 端从 TiKV 端读取,cop task 是指被下推到 TiKV 端分布式执行的计算任务。
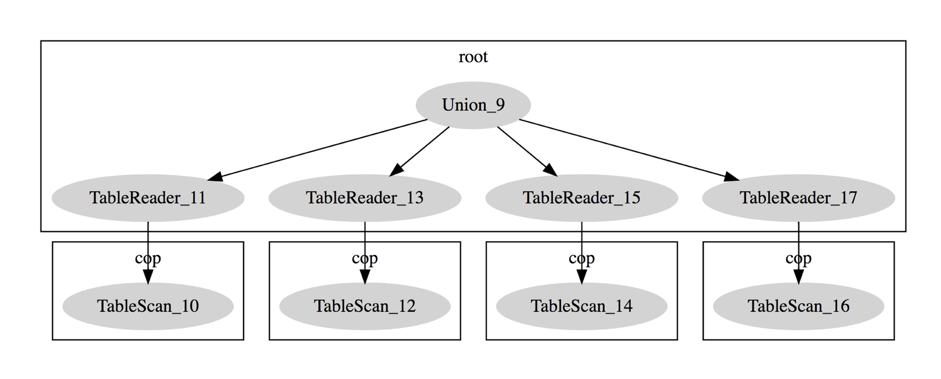
用户在使用分区表时,往往只需要访问其中部分的分区, 就像程序局部性原理一样,优化器分析 FROM 和 WHERE 子句来消除不必要的分区,具体还要优化器根据实际的 SQL 语句中所带的条件,避免访问无关分区的优化过程我们称之为分区裁剪(Partition Pruning),具体实现在 这里,分区裁剪是分区表提供的重要优化手段,通过分区的裁剪,避免访问无关数据,可以加速查询速度。当然用户可以刻意利用分区裁剪的特性在 SQL 加入定位分区的条件,优化查询性能。
Insert 语句
Insert 语句 是怎么样写入 Table Partition ?
其实解释这些问题就可以了:
普通表和分区表怎么区分?
插入数据应该插入哪个 Partition?
每个 Partition 的 RowKey 怎么编码的和普通表的区别是什么?
怎么将数据插入到相应的 Partition 里面?
普通 Table 和 Table Partition 也是实现了 Table 的接口,load schema 在初始化 Table 数据结构的时候,如果发现 tableInfo 里面没有 Partition 信息,则生成一个普通的 tables.Table,普通的 Table 跟以前处理逻辑保持不变,如果 tableInfo 里面有 Partition 信息,则会生成一个 tables.PartitionedTable,它们的区别是 RowKey 的编码方式:
每个分区有一个独立的 Partition ID,Partition ID 和 Table ID 地位平等,每个 Partition 的 Row 和 index 在编码的时候都使用这个 Partition 的 ID。
下面是 PartitionRecordKey 和普通表 RecordKey 区别。
分区表按照规则编码成 Key-Value pair:
Key:
tablePrefix_rowPrefix_partitionID_rowIDValue:
[col1, col2, col3, col4]普通表按照规则编码成 Key-Value pair:
Key:
tablePrefix_rowPrefix_tableID_rowIDValue:
[col1, col2, col3, col4]
通过 locatePartition 操作查询到应该插入哪个 Partition,目前支持 RANGE 分区插入到那个分区主要是通过范围来判断,例如在 employees 表中插入下面的 sql,通过计算范围该条记录会插入到 p3 分区中,接着调用对应 Partition 上面的 AddRecord 方法,将数据插入到相应的 Partition 里面。
INSERT INTO employees VALUES (1, 'PingCAP TiDB', '2003-10-15'),插入数据时,如果某行数据不属于任何 Partition,则该事务失败,所有操作回滚。如果 Partition 的 Key 算出来是一个
NULL,对于不同的 Partition 类型有不同的处理方式:对于 Range Partition:该行数据被插入到小的那个 Partition
对于 List partition:如果某个 Partition 的 Value List 中有
NULL,该行数据被插入那个 Partition,否则插入失败对于 Hash 和 Key Partition:
NULL值视为 0,计算 Partition ID 将数据插入到对应的 Partition
在 TiDB 分区表中分区字段插入的值不能大于表中 Range 值大的上界,否则会报错
End
TiDB 目前支持 Range 分区类型,点击查看 具体及细节。剩余其它类型的分区类型正在开发中,后面陆续会和大家见面,敬请期待。它们的源码实现读者届时可以自行阅读,流程和文中上述描述类似。
