Kyligence
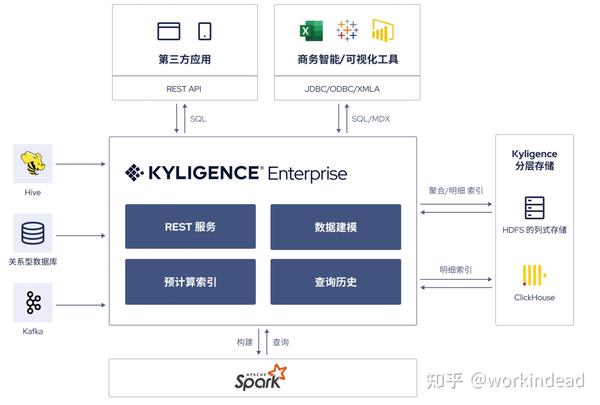
Kyligence,作为大数据管理和分析平台,支持PB级数据集上亚秒级标准SQL查询响应。Kyligence 4 集成了包括SQL查询、触发构建任务等全面的REST API。
基本概念
1. Table - 源数据表。在创建模型并加载数据之前,系统需要从数据源(通常为 Hive)同步表的元数据,包含表名、列名、列属性等。
2. Model - 模型,也是逻辑语义层。模型是一组表以及它们间的关联关系 (Join Relationship)。模型中定义了事实表、维度表、度量、维度、和一组索引。模型和其中的索引定义了加载数据时要执行的预计算。系统支持基于星型模型和雪花模型的多维模型。
数据集市模式:星型模型(Star Schema)VS. 雪花模型(Snowflake Schema)
星型和雪花型模式常见于维度数据仓库和数据集市,在这些数据检索速度比数据操作效率更重要的地方。因此,这些模式中的表没有进行太多规范化,并且经常被设计为低于第三范式的规范化级别。星型模式是雪花模式的一个重要特例,对于处理更简单的查询更有效。
事实表(Fact)VS. 维度表(Dim)
- 事实表:一般为具有可统计量化(度量)的信息的表。如订单表适合作为事实表,其中有订购数量、金额等可以被统计和量化的列。
- 维度表:一般为表示分析的业务角度的表。如商品信息表适合作为维度表,其中有商品类别、商品上标等可以作为分析的业务角度的列。时间表通常作为维度表使用,便于按日/周/月/季/年统计业务数据。
相对庞⼤的事实表⽽⾔,维度表通常很⼩且内容稳定。
- 维度:⼀般为可分析的业务⾓度,如订单⽇期表⽰⽇期维度、商品ID表⽰商品维度。
- 度量:⼀般为可统计量化的数值信息,如销售总额、销售总量等。通常为可量化的列与函数⼀起配合使⽤,如SUM、COUNT、TOP_N等。
3. Index - 索引,在数据加载时将构建索引,索引将被用于加速查询。索引分为聚合索引与明细索引。
- Aggregate Index - 聚合索引,本质是多个维度和度量的组合,适合回答聚合查询,比如某年的销售总额。
- Table Index - 明细索引,本质是大宽表的多路索引,适合回答到记录的明细查询,比如某用户的近 100 笔交易。
4. Load Data - 加载数据。为了加速查询,需要将数据从源表加载入模型,在此过程中也将构建索引,整个过程即是数据的预计算过程。每一次数据加载将产生一个 Segment。载入数据后的模型可以服务于查询,由于预计算,在模型上执行的查询将获得极大的加速。
- Incremental Load - 增量数据加载。在事实表上可以定义一个分区日期或时间列。根据分区列,可以按时间范围对超大数据集做增量加载。
- Full Load - 全量加载。如果没有定义分区列,那么源表中的所有数据将被一次性加载。
- Build Index - 重建索引。用户可以随时调整模型和索引的定义。对于已加载的数据,其上的索引需要按新的定义重新构建。如果用户要求加速某些查询,系统也可能优化模型和索引,进而触发重建索引。
示例
以SSB(Star Schema Benchmark)数据集为例,SSB是Kyligence Enterprise 提供的开源的、专⻔针对星型模型 OLAP 场景的测试数据集。
| 事实表 | P_LINEORDER - 销售订单表,每⼀⾏对应着⼀笔交易订单。 |
| 维度表 | CUSTOMER - 用户信息表(如⽤户的名称、地址、城市等);SUPPLIER - 供应商信息表(如供应商名称、地址、电话);DATES - 时间信息表(如单个⽇期所在的年份、⽉份、星期等);PART - 零件信息表(如零件的名称、类别、颜⾊、型号等) |
| 维度 | 零件ID |
| 度量 | 销售总额、销售总量 |
| 聚合索引 | 某年的销售总额 |
| 明细索引 | 某用户的近 100 笔交易 |
事实表 P_LINEORDER 和剩下的 5 张表⼀起构成了整个星型模型的结构,下图是实例-关系(ER)图:

链接:https://zhuanlan.zhihu.com/p/488474090
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Intelligent Recommendation - 智能推荐,指系统具备的自动优化模型和索引来加速查询的能力。系统可以依据历史查询模式和数据集特征来自动优化模型和索引。这样可以大量节省用户手工设计模型和索引的时间。
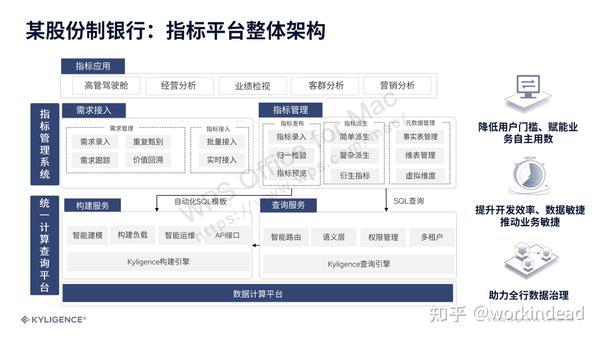
某股份制银行指标中台
现代管理学之⽗彼得·德鲁克有⼀句⾮常经典的话:“What gets measured gets done”,意思是只有⼀个事情能被量化,才能够被解决。就好⽐家⾥有了⼀台秤,才能衡量减肥的效果。那么如何量化管理企业呢,这个统⼀的标准去衡量业务,就是指标的由来。
Quota - 指标。指标是衡量⽬标的参数;预期中打算达到的指数、规格、标准,⼀般⽤数据表⽰。 例如,存款余额。
AtomQuota - 原⼦指标。原⼦指标和度量含义相同,也叫基础指标,是基于某⼀业务事件⾏为下的度量,是业务定义中不可再拆分的指标,具有明确业务含义的名称,如存款余额。
简单派生指标 VS. 复杂派生指标
- 简单派生指标:一到多个指标添加过滤条件生成新指标。若多个指标过滤相同条件,选好一个指标添加过滤后,勾选设置的条件应用于其他指标即可。
- 复杂派生指标:一到多个指标通过加减乘除、添加过滤条件、时间偏移生成新指标。
- 示例
| 维度 | 机构 |
| 维度属性 | 总行、分行、支行 |
| 指标主题 | 零售主题 |
| 原子指标/度量 | 当日零售客户存款余额 |
| 派生指标 | 当月零售客户存款余额 |
| 复合指标 | 定期存款月日均 |
