In 2017, we won the competition for the development of the transaction core for Alfa-Bank's investment business and started working at once. (Vladimir Drynkin, Development Team Lead for Alfa-Bank's Investment Business Transaction Core, spoke about the investment business core at HighLoad++ 2018.) This system was supposed to aggregate transaction data in different formats from various sources, unify the data, save it, and provide access to it.
2017年,我们赢得了Alfa-Bank投资业务交易核心开发方面的竞争,并立即开始工作。 (阿尔法银行投资业务交易核心开发团队负责人弗拉基米尔·德莱金(Vladimir Drynkin)在HighLoad ++ 2018上谈到了投资业务核心。)该系统应该以各种格式汇总来自各种来源的交易数据,统一数据,保存数据和提供对其的访问。
In the process of development, the system evolved and extended its functions. At some point, we realized that we created something much more than just application software designed for a well-defined scope of tasks: we created a system for building distributed applications with persistent storage. Our experience served as a basis for the new product, Tarantool Data Grid (TDG).
在开发过程中,该系统不断发展壮大并扩展了其功能。 在某个时候,我们意识到我们不仅创建了为明确定义的任务范围设计的应用程序软件,还做了很多事情:我们创建了一个用于构建具有持久性存储的分布式应用程序的系统。 我们的经验为新产品Tarantool Data Grid (TDG)奠定了基础。
I want to talk about TDG architecture and the solutions that we worked out during the development. I will introduce the basic functions and show how our product could become the basis for building turnkey solutions.
我想谈谈TDG架构以及我们在开发过程中制定的解决方案。 我将介绍基本功能,并说明我们的产品如何成为构建交钥匙解决方案的基础。
In terms of architecture, we divided the system into separate roles. Every one of them is responsible for a specific range of tasks. One running instance of an application implements one or more role *. There may be several roles of the same type in a cluster:
在体系结构方面,我们将系统划分为不同的角色 。 他们每个人都负责特定的任务范围。 一个正在运行的应用程序实例实现一种或多种角色类型。 群集中可能有多个相同类型的角色:
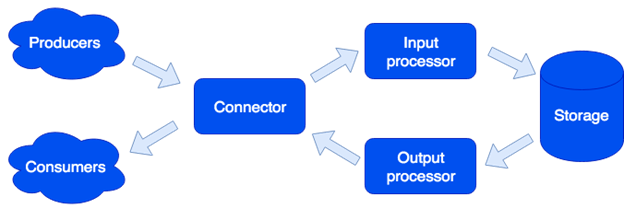
连接器 (Connector)
The Connector is responsible for communication with the outside world; it is designed to accept the request, parse it, and if it succeeds, then it sends the data for processing to the input processor. The following formats are supported: HTTP, SOAP, Kafka, FIX. The architecture allows us to add support for new formats (IBM MQ support is coming soon). If request parsing fails, the connector returns an error. Otherwise, it responds that the request has been processed successfully, even if an error occurred during further processing. This is done on purpose in order to work with the systems that do not know how to repeat requests, or vice versa, do it too aggressively. To make sure that no data is lost, the repair queue is used: the object joins the queue and is removed from it only after successful processing. The administrator receives notifications about the objects remaining in the repair queue and can retry processing after handling a software error or hardware failure.
连接器负责与外界的交流; 它被设计为接受请求,解析请求,如果请求成功,则将数据发送给输入处理器进行处理。 支持以下格式:HTTP,SOAP,Kafka,FIX。 该体系结构使我们能够添加对新格式的支持(IBM MQ支持即将推出)。 如果请求解析失败,则连接器将返回错误。 否则,即使在进一步处理期间发生错误,它也会响应已成功处理该请求。 这样做是有目的的,以便与不知道如何重复请求的系统一起工作,反之亦然。 为了确保没有数据丢失,使用了修复队列:对象加入队列,仅在成功处理后才从队列中删除。 管理员会收到有关修复队列中剩余对象的通知,并可以在处理软件错误或硬件故障后重试处理。
输入处理器 (Input Processor)
The Input Processor categorizes the received data by characteristics and calls the corresponding handlers. Handlers are Lua code that runs in a sandbox, so they cannot affect the system operation. At this stage, the data could be transformed as required, and if necessary, any number of tasks may run to implement the necessary logic. For example, when adding a new user in MDM (Master Data Management built based on Tarantool Data Grid), a golden record would be created as a separate task so that the request processing doesn't slow down. The sandbox supports requests for reading, changing, and adding data. It also allows you to call some function for all the roles of the storage type and aggregate the result (map/reduce).
输入处理器按特征对接收到的数据进行分类,并调用相应的处理程序。 处理程序是在沙箱中运行的Lua代码,因此它们不会影响系统操作。 在此阶段,可以根据需要转换数据,如果需要,可以运行任意数量的任务来实现必要的逻辑。 例如,在MDM(基于Tarantool Data Grid构建的主数据管理)中添加新用户时,黄金记录将被创建为单独的任务,以使请求处理不会减慢速度。 沙盒支持读取,更改和添加数据的请求。 它还允许您为存储类型的所有角色调用某些函数并汇总结果(映射/归约)。
Handlers can be described in files:
处理程序可以在文件中描述:
- sum.lua
-
- local x, y = unpack(...)
- return x + y
Then declared in the configuration:
然后在配置中声明:
- functions:
- sum: { __file: sum.lua }
Why Lua? Lua is a straightforward language. Based on our experience, people start to write code that would solve their problem only a couple of hours after seeing the language for the first time. And these are not only professional developers, but for example, analysts. Moreover, thanks to the JIT compiler, Lua is sppedy.
为什么是卢阿? Lua是一种简单易懂的语言。 根据我们的经验,人们在次看到该语言后几个小时就开始编写可以解决问题的代码。 这些不仅是专业开发人员,而且还包括分析师。 而且,由于使用了JIT编译器,Lua非常出色。
存储 (Storage)
The Storage stores persistent data. Before saving, the data is validated for compliance with the data scheme. To describe the scheme, we use the extended Apache Avro format. Example:
存储设备存储持久性数据。 保存之前,将验证数据是否符合数据方案。 为了描述该方案,我们使用扩展的Apache Avro格式。 例:
- {
- "name": "User",
- "type": "record",
- "logicalType": "Aggregate",
- "fields": [
- { "name": "id", "type": "string" },
- { "name": "first_name", "type": "string" },
- { "name": "last_name", "type": "string" }
- ],
- "indexes": ["id"]
- }
Based on this description, DDL (Data Definition Language) for Tarantool DBMS and GraphQLschema for data access are generated automatically.
基于此描述,将自动生成用于Tarantool DBMS的DDL(数据定义语言)和用于数据访问的GraphQL模式。
Asynchronous data replication is supported (we also plan to add synchronous replication).
支持异步数据复制(我们还计划添加同步复制)。
输出处理器 (Output Processor)
Sometimes it is necessary to notify external consumers about the new data. That is why we have the Output Processor role. After saving the data, it could be transferred into the appropriate handler (for example, to transform it as required by the consumer), and then transferred to the connector for sending. The repair queue is also used here: if no one accepts the object, the administrator can try again later.
有时有必要将新数据通知外部使用者。 这就是为什么我们要担任输出处理器角色。 保存数据后,可以将其传输到适当的处理程序中(例如,根据使用者的要求进行转换),然后将其传输到连接器以进行发送。 修复队列也在此处使用:如果没有人接受该对象,则管理员可以稍后重试。
缩放比例 (Scaling)
The Connector, Input Processor, and Output Processor roles are stateless, which allows us to scale the system horizontally by merely adding new application instances with the necessary enabled role. For horizontal storage scaling, a cluster is organized using the virtual buckets approach. After adding a new server, some buckets from the old servers move to a new server in the background. This process is transparent for the users and does not affect the operation of the entire system.
连接器,输入处理器和输出处理器角色是无状态的,这使我们能够通过仅添加具有必要启用角色的新应用程序实例来水平扩展系统。 对于水平存储扩展,使用虚拟存储桶方法来组织集群。 添加新服务器后,旧服务器中的一些存储桶将在后台移至新服务器。 此过程对用户是透明的,并且不会影响整个系统的操作。
资料属性 (Data Properties)
Objects may be huge and contain other objects. We ensure adding and updating data atomically, and saving the object with all the dependencies on a single virtual bucket. This is done to avoid the so-called «smearing» of the object across multiple physical servers.
对象可能很大,并且包含其他对象。 我们确保原子地添加和更新数据,并将具有所有依赖项的对象保存在单个虚拟存储桶中。 这样做是为了避免跨多个物理服务器的对象的所谓“拖尾”。
Versioning is also supported: each update of the object creates a new version, and we can always make a time slice to see how everything looked like at the time. For data that does not need a long history, we can limit the number of versions or even store only the last one, that is, we can disable versioning for a specific data type. We can also set the historical limits: for example, delete all the objects of a specific type older than a year. Archiving is also supported: we can upload objects above a certain age to free up the cluster space.
还支持版本控制:对象的每次更新都会创建一个新版本,我们始终可以制作一个时间片来查看当时的一切情况。 对于不需要很长历史记录的数据,我们可以限制版本数,甚至只存储后一个版本,也就是说,我们可以禁用特定数据类型的版本控制。 我们还可以设置历史限制:例如,删除所有特定类型的对象早于一年。 还支持存档:我们可以上传超过一定年龄的对象以释放集群空间。
任务 (Tasks)
Interesting features to be noted include the ability to run tasks on time, at the user's request, or automatically from the sandbox:
需要注意的有趣功能包括根据用户的请求或从沙盒自动运行任务的能力:
Here we can see another role called Runner. This role has no state; if necessary, more application instances with this role could be added to the cluster. The Runner is responsible for completing the tasks. As I have already mentioned, new tasks could be created from the sandbox; they join the queue on the storage and then run on the runner. This type of tasks is called a Job. We also have a task type called Task, that is, a user-defined task that would run on time (using the cron syntax) or on-demand. To run and track such tasks, we have a convenient task manager. The scheduler role must be enabled to use this function. This role has a state, so it does not scale which is not necessary anyway. However, like any other role it can have a replica that starts working if the master suddenly fails.
在这里,我们可以看到另一个名为Runner的角色。 这个角色没有状态; 如有必要,可以将更多具有该角色的应用程序实例添加到群集中。 跑步者负责完成任务。 正如我已经提到的,可以从沙箱中创建新任务。 他们加入存储队列,然后在运行器上运行。 这种任务称为作业。 我们还有一个名为Task的任务类型,即用户定义的任务,可以按时(使用cron语法)或按需运行。 为了运行和跟踪此类任务,我们有一个方便的任务管理器。 必须启用调度程序角色才能使用此功能。 该角色具有状态,因此它不会扩展,而这是不必要的。 但是,像其他任何角色一样,如果主服务器突然发生故障,它可以具有一个可以开始工作的副本。
记录仪 (Logger)
Another role is called Logger. It collects logs from all cluster members and provides an interface for uploading and viewing them via the web interface.
另一个角色称为Logger。 它从所有群集成员收集日志,并提供一个用于通过Web界面上传和查看日志的界面。
服务 (Services)
It is worth mentioning that the system makes it easy to create services. In the configuration file, you can specify which requests should be sent to the user-written handler running in the sandbox. Such a handler may, for example, perform some kind of analytical request and return the result.
值得一提的是,该系统使创建服务变得容易。 在配置文件中,您可以指定应将哪些请求发送到在沙箱中运行的用户编写的处理程序。 这样的处理程序可以例如执行某种分析请求并返回结果。
The service is described in the configuration file:
该服务在配置文件中描述:
- services:
- sum:
- doc: "adds two numbers"
- function: sum
- return_type: int
- args:
- x: int
- y: int
The GraphQL API is generated automatically, and the service is available for calls:
GraphQL API是自动生成的,并且该服务可用于以下调用:
- query {
- sum(x: 1, y: 2)
- }
This calls the sum handler that returns the result:
这将调用sum处理程序以返回结果:
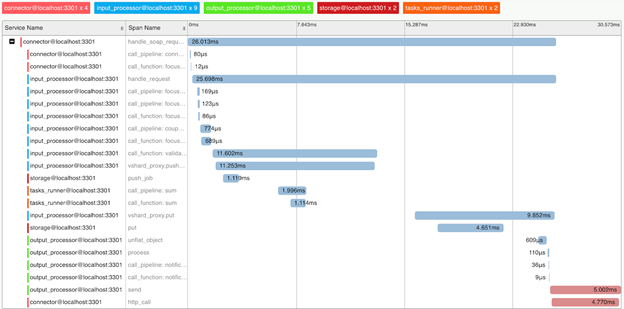
3要求分析和指标 (Request Profiling and Metrics)
We implemented support for the OpenTracing protocol to bring a better understanding of the system mechanisms and request profiling. On demand, the system can send information about how the request was executed to tools supporting this protocol (e.g. Zipkin):
我们实现了对OpenTracing协议的支持,以更好地理解系统机制和请求分析。 根据需要,系统可以将有关如何执行请求的信息发送到支持此协议的工具(例如Zipkin):
Needless to say, the system provides internal metrics that can be collected using Prometheus and visualized using Grafana.
不用说,该系统提供了内部指标,可以使用Prometheus进行收集并使用Grafana进行可视化。
部署方式 (Deployment)
Tarantool Data Grid can be deployed from RPM-packages or archives using the built-in utility or Ansible. Kubernetes is also supported (Tarantool Kubernetes Operator).
可以使用内置实用程序或Ansible从RPM软件包或归档中部署Tarantool Data Grid。 Kubernetes也受支持( Tarantool Kubernetes Operator )。
An application that implements business logic (configuration, handlers) is loaded into the deployed Tarantool Data Grid cluster in the archive via the UI or as a script using the provided API.
通过UI或使用提供的API作为脚本,将实现业务逻辑(配置,处理程序)的应用程序加载到存档中已部署的Tarantool Data Grid集群中。
样例应用 (Sample Applications)
What applications can you create with Tarantool Data Grid? In fact, most business tasks are somehow related to data stream processing, storing and accessing. Therefore, if you have large data streams that require secure storage, and accessibility, then our product could save you much time in development and help you concentrate on your business logic.
您可以使用Tarantool Data Grid创建哪些应用程序? 实际上,大多数业务任务都以某种方式与数据流的处理,存储和访问有关。 因此,如果您有需要安全存储和可访问性的大型数据流,那么我们的产品可以为您节省大量开发时间,并帮助您专注于业务逻辑。
For example, you would like to gather information about the real estate market to stay up to date on the best offers in the future. In this case, we single out the following tasks:
例如,您想收集有关房地产市场的信息,以便将来了解新的佳报价。 在这种情况下,我们将选择以下任务:
- Robots gathering information from open sources would be your data sources. You can solve this problem using ready-made solutions or by writing code in any language.从开放源收集信息的机器人将是您的数据源。 您可以使用现成的解决方案或通过使用任何语言编写代码来解决此问题。
- Next, Tarantool Data Grid accepts and saves the data. If the data format from various sources is different, then you could write code in Lua that would convert everything to a single format. At the pre-processing stage, you could also, for example, filter recurring offers or further update database information about agents operating in the market.接下来,Tarantool数据网格接受并保存数据。 如果来自各种来源的数据格式不同,则可以用Lua编写代码,将所有内容转换为单一格式。 在预处理阶段,例如,您还可以过滤重复报价或进一步更新有关市场中代理商的数据库信息。
- Now you already have a scalable solution in the cluster that could be filled with data and used to create data samples. Then you can implement new functions, for example, write a service that would create a data request and return the most advantageous offer per day. It would only require several lines in the configuration file and some Lua code.现在,您已经在集群中有了一个可伸缩的解决方案,可以在其中填充数据并用于创建数据样本。 然后,您可以实现新功能,例如,编写将创建数据请求并每天返回优惠报价的服务。 在配置文件中只需要几行,并需要一些Lua代码。
接下来是什么? (What is next?)
For us, a priority is to increase the development convenience with Tarantool Data Grid. (For example, this is an IDE with support for profiling and debugging handlers that work in the sandbox.)
对我们来说,优先考虑的是使用Tarantool Data Grid增加开发的便利性。 (例如,这是一个IDE,它支持在沙箱中工作的分析和调试处理程序。)
We also pay great attention to security issues. Right now, our product is being certified by FSTEC of Russia (Federal Service for Technology and Export Control) to acknowledge the high level of security and meet the certification requirements for software products used in personal data information systems and federal information systems.
我们也非常注意安全问题。 目前,我们的产品已通过俄罗斯FSTEC(技术和出口控制联邦服务)的认证,以确认其高度的安全性并满足个人数据信息系统和联邦信息系统中使用的软件产品的认证要求。
